 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reward Was in Your Data All Along: Correcting Flow Matching with Discriminator-Guided RL
Jun 17, 2026Score- and flow-matching models often rely on preference-based reinforcement learning for two purposes: aligning with subjective preferences and, surprisingly, recovering properties such as visual realism and coherent object structure that matching-based training is intended to learn from the data itself. We argue that this reflects a structural mismatch. Matching losses measure $\ell_2$ regression error on the velocity or score field under training-time marginals, a proxy poorly aligned with the visual and semantic properties that determine sample quality at inference. Given a reward aligned with these properties, RL sidesteps the mismatch by evaluating the model on its own samples and following the reward landscape directly. The challenge is to obtain such a reward without relying on human preferences, which are expensive and conflate data realism with annotator inclinations. We propose Discriminator-Guided RL (DRL). DRL trains a discriminator to separate data from base-model samples in a pretrained representation space and uses its logit as the reward in KL-regularized RL. The pretrained space restricts the discriminator to perceptually meaningful directions, and the logit estimates the log-likelihood ratio between data and model, which is the optimal reward for targeting the data distribution. Across SiT, JiT, REPA, and RAE, DRL reduces guidance-free FID (e.g., $9.38 \to 2.62$ on SiT) and semantic-space FD (e.g., $88.2 \to 19.3$ on DINOv3 for SiT), with consistent gains across all backbones, and improves human-preference rewards without training on them. It also yields a better Pareto frontier between preference reward and image fidelity under subsequent preference-based post-training, increasing alignment while reducing low-level artifacts such as oversaturation and excessive brightness.
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
Dec 18, 2025Reward models (RMs) are essential for training large language models (LLMs), but remain underexplored for omni models that handle interleaved image and text sequences. We introduce Multimodal RewardBench 2 (MMRB2), the first comprehensive benchmark for reward models on multimodal understanding and (interleaved) generation. MMRB2 spans four tasks: text-to-image, image editing, interleaved generation, and multimodal reasoning ("thinking-with-images"), providing 1,000 expert-annotated preference pairs per task from 23 models and agents across 21 source tasks. MMRB2 is designed with: (1) practical but challenging prompts; (2) responses from state-of-the-art models and agents; and (3) preference pairs with strong human-expert consensus, curated via an ensemble filtering strategy. Using MMRB2, we study existing judges for each subtask, including multimodal LLM-as-a-judge and models trained with human preferences. The latest Gemini 3 Pro attains 75-80% accuracy. GPT-5 and Gemini 2.5 Pro reach 66-75% accuracy, compared to >90% for humans, yet surpass the widely used GPT-4o (59%). The best performing open-source model Qwen3-VL-32B achieves similar accuracies as Gemini 2.5 Flash (64%). We also show that MMRB2 performance strongly correlates with downstream task success using Best-of-N sampling and conduct an in-depth analysis that shows key areas to improve the reward models going forward.
Why Less is More (Sometimes): A Theory of Data Curation
Nov 05, 2025



This paper introduces a theoretical framework to resolve a central paradox in modern machine learning: When is it better to use less data? This question has become critical as classical scaling laws suggesting ``more is more'' (Sun et al., 2025) are challenged by methods like LIMO (``less is more'') and s1 (Ye et al., 2025; Muenighoff et al., 2025), which achieve superior performance with small, aggressively curated datasets. Here, we study data curation strategies where an imperfect oracle selects the training examples according to their difficulty and correctness. Our results provide exact scaling law curves for test error under both label-agnostic and label-aware curation rules, revealing when and why keeping only a subset of data can improve generalization. In contrast to classical scaling laws, we show that under certain conditions, small curated datasets can outperform full datasets, and we provide analytical conditions for this by deriving precise phase transition curves tied to data size and quality. We validate these theoretical claims with empirical results on ImageNet, confirming our predictions about when curation improves accuracy and can even mitigate model collapse. Furthermore, our framework provides a principled explanation for the contradictory curation strategies recently observed in LLM mathematical reasoning.
Multi-Modal Language Models as Text-to-Image Model Evaluators
May 01, 2025The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.
Improving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025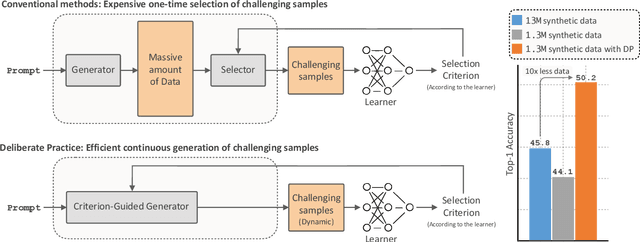
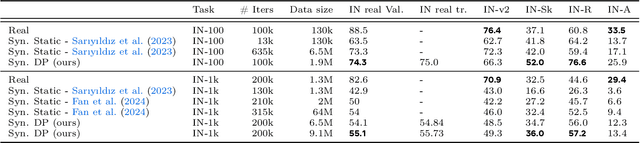
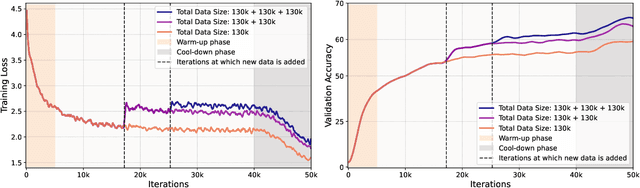

Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Nov 05, 2024Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In this work, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i)~the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii)~the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset -- with FID improvements of 7% on 256 and 8% on 512 resolutions -- as well as text-to-image generation on the CC12M dataset -- with FID improvements of 8% on 256 and 23% on 512 resolution.