 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
SneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
Consistency-diversity-realism Pareto fronts of conditional image generative models
Jun 14, 2024



Building world models that accurately and comprehensively represent the real world is the utmost aspiration for conditional image generative models as it would enable their use as world simulators. For these models to be successful world models, they should not only excel at image quality and prompt-image consistency but also ensure high representation diversity. However, current research in generative models mostly focuses on creative applications that are predominantly concerned with human preferences of image quality and aesthetics. We note that generative models have inference time mechanisms - or knobs - that allow the control of generation consistency, quality, and diversity. In this paper, we use state-of-the-art text-to-image and image-and-text-to-image models and their knobs to draw consistency-diversity-realism Pareto fronts that provide a holistic view on consistency-diversity-realism multi-objective. Our experiments suggest that realism and consistency can both be improved simultaneously; however there exists a clear tradeoff between realism/consistency and diversity. By looking at Pareto optimal points, we note that earlier models are better at representation diversity and worse in consistency/realism, and more recent models excel in consistency/realism while decreasing significantly the representation diversity. By computing Pareto fronts on a geodiverse dataset, we find that the first version of latent diffusion models tends to perform better than more recent models in all axes of evaluation, and there exist pronounced consistency-diversity-realism disparities between geographical regions. Overall, our analysis clearly shows that there is no best model and the choice of model should be determined by the downstream application. With this analysis, we invite the research community to consider Pareto fronts as an analytical tool to measure progress towards world models.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Improving Text-to-Image Consistency via Automatic Prompt Optimization
Mar 26, 2024



Impressive advances in text-to-image (T2I) generative models have yielded a plethora of high performing models which are able to generate aesthetically appealing, photorealistic images. Despite the progress, these models still struggle to produce images that are consistent with the input prompt, oftentimes failing to capture object quantities, relations and attributes properly. Existing solutions to improve prompt-image consistency suffer from the following challenges: (1) they oftentimes require model fine-tuning, (2) they only focus on nearby prompt samples, and (3) they are affected by unfavorable trade-offs among image quality, representation diversity, and prompt-image consistency. In this paper, we address these challenges and introduce a T2I optimization-by-prompting framework, OPT2I, which leverages a large language model (LLM) to improve prompt-image consistency in T2I models. Our framework starts from a user prompt and iteratively generates revised prompts with the goal of maximizing a consistency score. Our extensive validation on two datasets, MSCOCO and PartiPrompts, shows that OPT2I can boost the initial consistency score by up to 24.9% in terms of DSG score while preserving the FID and increasing the recall between generated and real data. Our work paves the way toward building more reliable and robust T2I systems by harnessing the power of LLMs.
Improving Automatic VQA Evaluation Using Large Language Models
Oct 04, 2023
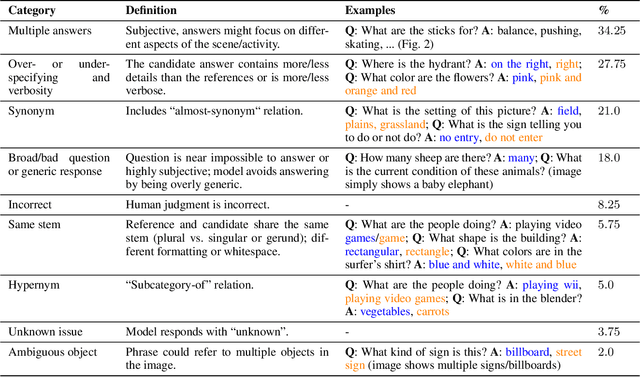

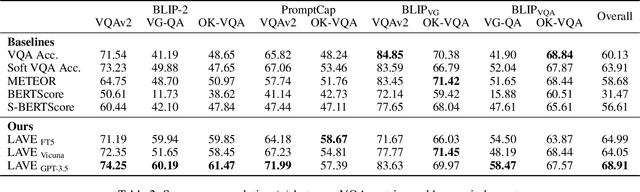
8 years after the visual question answering (VQA) task was proposed, accuracy remains the primary metric for automatic evaluation. VQA Accuracy has been effective so far in the IID evaluation setting. However, our community is undergoing a shift towards open-ended generative models and OOD evaluation. In this new paradigm, the existing VQA Accuracy metric is overly stringent and underestimates the performance of VQA systems. Thus, there is a need to develop more robust automatic VQA metrics that serve as a proxy for human judgment. In this work, we propose to leverage the in-context learning capabilities of instruction-tuned large language models (LLMs) to build a better VQA metric. We formulate VQA evaluation as an answer-rating task where the LLM is instructed to score the accuracy of a candidate answer given a set of reference answers. We demonstrate the proposed metric better correlates with human judgment compared to existing metrics across several VQA models and benchmarks. We hope wide adoption of our metric will contribute to better estimating the research progress on the VQA task.
MAPL: Parameter-Efficient Adaptation of Unimodal Pre-Trained Models for Vision-Language Few-Shot Prompting
Oct 13, 2022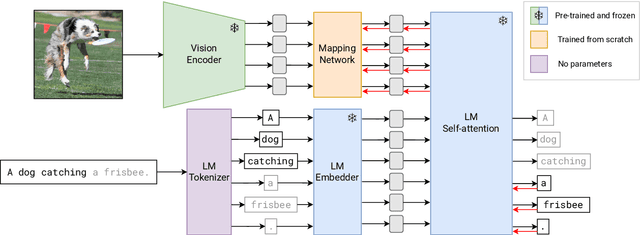

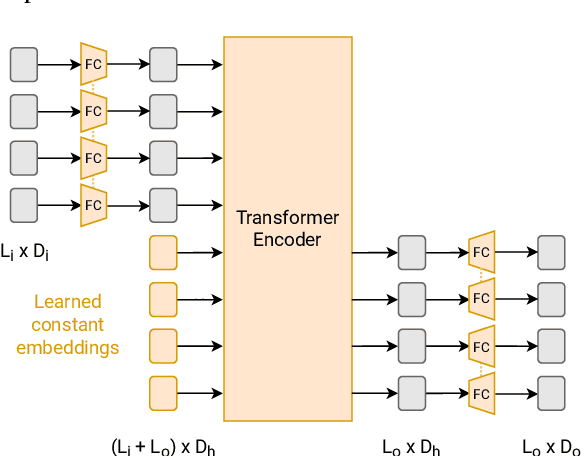
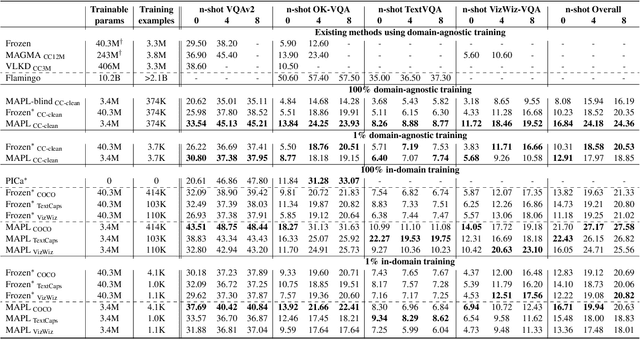
Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. We propose MAPL, a simple and parameter-efficient method that reuses frozen pre-trained unimodal models and leverages their strong generalization capabilities in multimodal vision-language (VL) settings. MAPL learns a lightweight mapping between the representation spaces of unimodal models using aligned image-text data, and can generalize to unseen VL tasks from just a few in-context examples. The small number of trainable parameters makes MAPL effective at low-data and in-domain learning. Moreover, MAPL's modularity enables easy extension to other pre-trained models. Extensive experiments on several visual question answering and image captioning benchmarks show that MAPL achieves superior or competitive performance compared to similar methods while training orders of magnitude fewer parameters. MAPL can be trained in just a few hours using modest computational resources and public datasets. We plan to release the code and pre-trained models.
Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
Mar 30, 2021
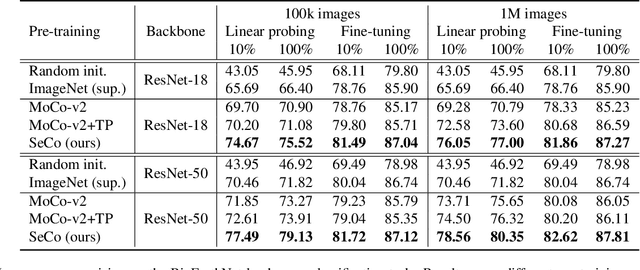
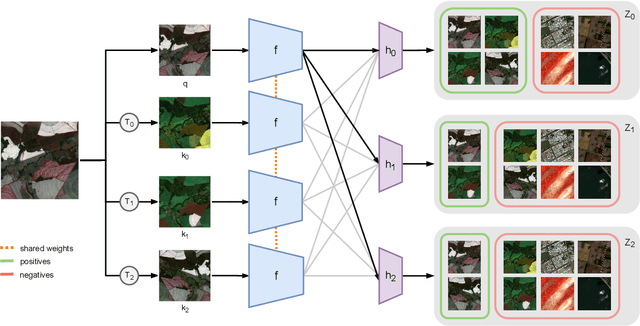

Remote sensing and automatic earth monitoring are key to solve global-scale challenges such as disaster prevention, land use monitoring, or tackling climate change. Although there exist vast amounts of remote sensing data, most of it remains unlabeled and thus inaccessible for supervised learning algorithms. Transfer learning approaches can reduce the data requirements of deep learning algorithms. However, most of these methods are pre-trained on ImageNet and their generalization to remote sensing imagery is not guaranteed due to the domain gap. In this work, we propose Seasonal Contrast (SeCo), an effective pipeline to leverage unlabeled data for in-domain pre-training of re-mote sensing representations. The SeCo pipeline is com-posed of two parts. First, a principled procedure to gather large-scale, unlabeled and uncurated remote sensing datasets containing images from multiple Earth locations at different timestamps. Second, a self-supervised algorithm that takes advantage of time and position invariance to learn transferable representations for re-mote sensing applications. We empirically show that models trained with SeCo achieve better performance than their ImageNet pre-trained counterparts and state-of-the-art self-supervised learning methods on multiple downstream tasks. The datasets and models in SeCo will be made public to facilitate transfer learning and enable rapid progress in re-mote sensing applications.
A Weakly Supervised Consistency-based Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020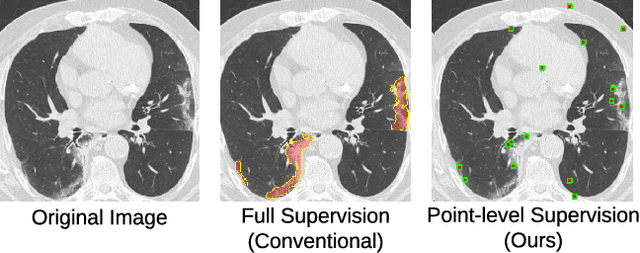

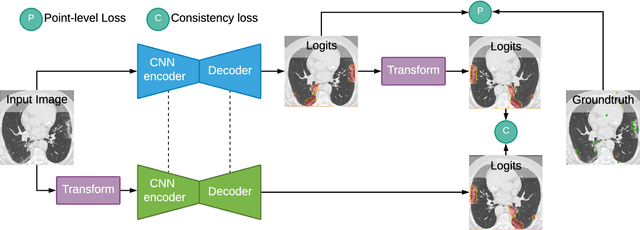
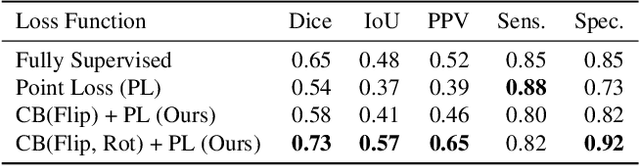
Coronavirus Disease 2019 (COVID-19) has spread aggressively across the world causing an existential health crisis. Thus, having a system that automatically detects COVID-19 in tomography (CT) images can assist in quantifying the severity of the illness. Unfortunately, labelling chest CT scans requires significant domain expertise, time, and effort. We address these labelling challenges by only requiring point annotations, a single pixel for each infected region on a CT image. This labeling scheme allows annotators to label a pixel in a likely infected region, only taking 1-3 seconds, as opposed to 10-15 seconds to segment a region. Conventionally, segmentation models train on point-level annotations using the cross-entropy loss function on these labels. However, these models often suffer from low precision. Thus, we propose a consistency-based (CB) loss function that encourages the output predictions to be consistent with spatial transformations of the input images. The experiments on 3 open-source COVID-19 datasets show that this loss function yields significant improvement over conventional point-level loss functions and almost matches the performance of models trained with full supervision with much less human effort. Code is available at: \url{https://github.com/IssamLaradji/covid19_weak_supervision}.