 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTECCI: Tricky Edits of Collected and Curated Images
May 31, 2026Despite tremendous recent progress, current text-guided image editing methods still struggle with many aspects of editing involving instruction following, minimally editing the source image, and ensuring high visual quality. These problems are especially apparent when the requested edit is challenging, such as those that involve position, motion, viewpoint, scale and creative edits. To systematically test generative image editors, we propose a novel image editing benchmark -- TECCI: Tricky Edits of Collected and Curated Images. TECCI consists of a completely new set of images we are releasing. The images in TECCI span 7 image categories. The images and these categories were curated intentionally to target weaknesses of existing methods. The edit instructions in TECCI are automatically generated by Gemini, covering 5 edit types per source image. We also curated a set of 530 images for which we created challenging manually written edit instructions. Overall, TECCI contains 7550 pairs of images and edit instructions. We conduct human evaluations of five leading image editing models on TECCI. Humans judge outputs along three dimensions: 1) instruction following, 2) minimality of the edits, and 3) visual quality. To scale-up the evaluation, we also build an auto-rater using Gemini that achieves 74.7% accuracy in matching human evaluations. Our evaluations reveal that: 1) none of the models exceed a 22% overall success rate, demonstrating the challenging nature of TECCI, 2) Nano Banana Pro is the best performing model overall, 3) models perform significantly better at instruction following compared to minimal edits and visual quality, 4) models struggle with editing architecture and nature images which require strong understanding of spatial layout and intricate visual details. 5) reasoning and creative edits are the most difficult, whereas color and appearance edits are the easiest.
How and What to Imagine? Visual Thinking in Unified Multimodal Models for Cross-View Spatial Reasoning
May 26, 2026Cross-view spatial reasoning remains a weak spot for vision-language models (VLMs): they often reason in language and lose the fine-grained geometry needed for the task. Thinking with images aims to address this by generating an intermediate thinking image, but recent work shows that models often ignore the visual evidence in these traces. We therefore ask how to make visual thinking matter, and what kind of visual thinking works best. We study these questions in unified multimodal models (UMMs), which natively support interleaved image-text generation. For the first question, we propose View Dropout (VDrop), a training-time intervention that hides parts of one input view from the answer span while keeping them visible to the thinking-image tokens. This encourages the model to use the thinking image when answering, instead of relying only on the input views. Once the thinking image is used for answer prediction, we study which type of visual thinking is most effective. We frame this as a learnability-informativeness tradeoff and compare three thinking-image variants: top-down, panoramic, and point-matching renderings. Trained on synthetic scenes and evaluated on five real-world out-of-domain benchmarks, panoramic visual thinking with VDrop is the only configuration that is both informative and learnable, and it achieves the best out-of-domain generalization.
RiT: Vanilla Diffusion Transformers Suffice in Representation Space
May 21, 2026Flow matching with $x$-prediction -- regressing the clean data point rather than the ambient velocity -- is known to exploit low-dimensional manifold structure effectively in pixel space \cite{li2025back}. We ask whether a pretrained representation space, while containing a low-dimensional data manifold of comparable intrinsic dimensionality, offers a distribution more favorable for flow-matching learning. Comparing pixel, SD-VAE, and DINOv2 features along four geometric axes, we find that pixel and DINOv2 share nearly identical intrinsic dimensionalities (both $\hat{d}\!\approx\!33$) yet DINOv2 exhibits $7.3\times$ higher effective rank, $35\times$ better covariance conditioning, $11.5\times$ lower excess kurtosis, and $1.7\times$ lower on-manifold interpolation error; SD-VAE latents are consistently intermediate, indicating that the advantage stems from representation-learning objectives rather than mere compression. These statistical properties render the flow-matching regression well-conditioned and remove the need for the specialized prediction heads or Riemannian transport used by prior DINOv2 diffusion methods. We propose the \emph{Representation Image Transformer} (RiT): a vanilla Diffusion Transformer trained by $x$-prediction on frozen DINOv2 features, augmented only by a dimension-aware noise schedule and joint \texttt{[CLS]}-patch modeling. On ImageNet $256{\times}256$, RiT attains FID 1.45 without guidance and 1.14 with classifier-free guidance, outperforming DiT$^\text{DH}$-XL with $19\%$ fewer parameters (676M vs.\ 839M). The resulting ODE is efficiently solvable at coarse discretizations: with classifier-free guidance, $5$ Heun steps already reach FID 2.0 and $10$ steps reach 1.25, without distillation or consistency training. Code at https://github.com/lezhang7/RiT.
From Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
May 04, 2026Human-level agentic intelligence extends beyond low-level geometric perception, evolving from recognizing where things are to understanding what they are for. While existing benchmarks effectively evaluate the geometric perception capabilities of multimodal large language models (MLLMs), they fall short of probing the higher-order cognitive abilities required for grounded intelligence. To address this gap, we introduce the Spatial-Functional Intelligence Benchmark (SFI-Bench), a video-based benchmark with over 1,500 expert-annotated questions derived from diverse egocentric indoor video scans. SFI-Bench systematically evaluates two complementary dimensions of advanced reasoning: (1) Structured Spatial Reasoning, which requires understanding complex layouts and forming coherent spatial representations, and (2) Functional Reasoning, which involves inferring object affordances and their context-dependent utility. The benchmark includes tasks such as conditional counting, multi-hop relational reasoning, functional pairing, and knowledge-grounded troubleshooting, directly challenging models to integrate perception, memory, and inference. Our experiments reveal that current MLLMs consistently struggle to combine spatial memory with functional reasoning and external knowledge, highlighting a critical bottleneck in achieving grounded intelligence. SFI-Bench therefore provides a diagnostic tool for measuring progress toward more cognitively capable and truly grounded multimodal agents.
Discovering Failure Modes in Vision-Language Models using RL
Apr 06, 2026Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favor of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying 36 novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
Communicating about Space: Language-Mediated Spatial Integration Across Partial Views
Apr 01, 2026Humans build shared spatial understanding by communicating partial, viewpoint-dependent observations. We ask whether Multimodal Large Language Models (MLLMs) can do the same, aligning distinct egocentric views through dialogue to form a coherent, allocentric mental model of a shared environment. To study this systematically, we introduce COSMIC, a benchmark for Collaborative Spatial Communication. In this setting, two static MLLM agents observe a 3D indoor environment from different viewpoints and exchange natural-language messages to solve spatial queries. COSMIC contains 899 diverse scenes and 1250 question-answer pairs spanning five tasks. We find a capability hierarchy, MLLMs are most reliable at identifying shared anchor objects across views, perform worse on relational reasoning, and largely fail at building globally consistent maps, performing near chance, even for frontier models. Moreover, we find thinking capability yields gains in anchor grounding, but is insufficient for higher-level spatial communication. To contextualize model behavior, we collect 250 human-human dialogues. Humans achieve 95% aggregate accuracy, while the best model, Gemini-3-Pro-Thinking, reaches 72%, leaving substantial room for improvement. Moreover, human conversations grow more precise as partners align on a shared spatial understanding, whereas MLLMs keep exploring without converging, suggesting limited capacity to form and sustain a robust shared mental model throughout the dialogue. Our code and data is available at https://github.com/ankursikarwar/Cosmic.
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
May 26, 2025We present REARANK, a large language model (LLM)-based listwise reasoning reranking agent. REARANK explicitly reasons before reranking, significantly improving both performance and interpretability. Leveraging reinforcement learning and data augmentation, REARANK achieves substantial improvements over baseline models across popular information retrieval benchmarks, notably requiring only 179 annotated samples. Built on top of Qwen2.5-7B, our REARANK-7B demonstrates performance comparable to GPT-4 on both in-domain and out-of-domain benchmarks and even surpasses GPT-4 on reasoning-intensive BRIGHT benchmarks. These results underscore the effectiveness of our approach and highlight how reinforcement learning can enhance LLM reasoning capabilities in reranking.
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning
Mar 27, 2025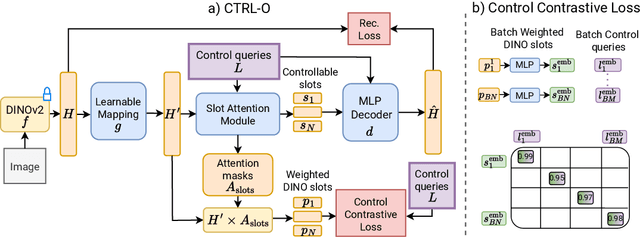

Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. Current state-of-the-art object-centric models have shown remarkable success in object discovery in diverse domains, including complex real-world scenes. However, these models suffer from a key limitation: they lack controllability. Specifically, current object-centric models learn representations based on their preconceived understanding of objects, without allowing user input to guide which objects are represented. Introducing controllability into object-centric models could unlock a range of useful capabilities, such as the ability to extract instance-specific representations from a scene. In this work, we propose a novel approach for user-directed control over slot representations by conditioning slots on language descriptions. The proposed ConTRoLlable Object-centric representation learning approach, which we term CTRL-O, achieves targeted object-language binding in complex real-world scenes without requiring mask supervision. Next, we apply these controllable slot representations on two downstream vision language tasks: text-to-image generation and visual question answering. The proposed approach enables instance-specific text-to-image generation and also achieves strong performance on visual question answering.
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction
Mar 19, 2025Autonomous agents that navigate Graphical User Interfaces (GUIs) to automate tasks like document editing and file management can greatly enhance computer workflows. While existing research focuses on online settings, desktop environments, critical for many professional and everyday tasks, remain underexplored due to data collection challenges and licensing issues. We introduce UI-Vision, the first comprehensive, license-permissive benchmark for offline, fine-grained evaluation of computer use agents in real-world desktop environments. Unlike online benchmarks, UI-Vision provides: (i) dense, high-quality annotations of human demonstrations, including bounding boxes, UI labels, and action trajectories (clicks, drags, and keyboard inputs) across 83 software applications, and (ii) three fine-to-coarse grained tasks-Element Grounding, Layout Grounding, and Action Prediction-with well-defined metrics to rigorously evaluate agents' performance in desktop environments. Our evaluation reveals critical limitations in state-of-the-art models like UI-TARS-72B, including issues with understanding professional software, spatial reasoning, and complex actions like drag-and-drop. These findings highlight the challenges in developing fully autonomous computer use agents. By releasing UI-Vision as open-source, we aim to advance the development of more capable agents for real-world desktop tasks.