 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisalignment Between Backpropagation and the Hierarchy of Brain Responses to Images
May 27, 2026Backpropagation is the core learning mechanism underlying deep learning. However, whether and how this algorithm is implemented in the brain remains highly debated. In particular, while forward activations of pretrained models reliably map onto the cortical hierarchy of visual processing, it is unknown whether backpropagated gradients exhibit a similar correspondence. Here, we address this question using functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) recordings of human brain responses to natural images. For this, we extend standard encoding analyses of forward activations to map backpropagated gradients onto neural data. Focusing on a recent self-supervised vision model (DINOv3) and reproducing results on eight vision models, we find that backpropagated gradients can reliably predict both fMRI and MEG signals, specifically in higher-level visual cortex and for later latencies. However, the spatial and temporal organization of these backpropagated gradients in the brain diverges from the patterns expected under a biologically plausible backpropagation mechanism: specifically, both the order in which gradients are computed and their spatial organization diverge from the temporal and spatial hierarchies of the human brain. Together, these results suggest that, although deep networks and the brain may share similar representational content, they likely rely on fundamentally different mechanisms to learn those representations.
Are Object-Centric Representations Better At Compositional Generalization?
Feb 18, 2026Compositional generalization, the ability to reason about novel combinations of familiar concepts, is fundamental to human cognition and a critical challenge for machine learning. Object-centric (OC) representations, which encode a scene as a set of objects, are often argued to support such generalization, but systematic evidence in visually rich settings is limited. We introduce a Visual Question Answering benchmark across three controlled visual worlds (CLEVRTex, Super-CLEVR, and MOVi-C) to measure how well vision encoders, with and without object-centric biases, generalize to unseen combinations of object properties. To ensure a fair and comprehensive comparison, we carefully account for training data diversity, sample size, representation size, downstream model capacity, and compute. We use DINOv2 and SigLIP2, two widely used vision encoders, as the foundation models and their OC counterparts. Our key findings reveal that (1) OC approaches are superior in harder compositional generalization settings; (2) original dense representations surpass OC only on easier settings and typically require substantially more downstream compute; and (3) OC models are more sample efficient, achieving stronger generalization with fewer images, whereas dense encoders catch up or surpass them only with sufficient data and diversity. Overall, object-centric representations offer stronger compositional generalization when any one of dataset size, training data diversity, or downstream compute is constrained.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning
Mar 27, 2025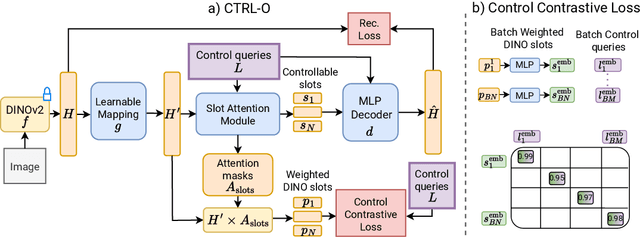

Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. Current state-of-the-art object-centric models have shown remarkable success in object discovery in diverse domains, including complex real-world scenes. However, these models suffer from a key limitation: they lack controllability. Specifically, current object-centric models learn representations based on their preconceived understanding of objects, without allowing user input to guide which objects are represented. Introducing controllability into object-centric models could unlock a range of useful capabilities, such as the ability to extract instance-specific representations from a scene. In this work, we propose a novel approach for user-directed control over slot representations by conditioning slots on language descriptions. The proposed ConTRoLlable Object-centric representation learning approach, which we term CTRL-O, achieves targeted object-language binding in complex real-world scenes without requiring mask supervision. Next, we apply these controllable slot representations on two downstream vision language tasks: text-to-image generation and visual question answering. The proposed approach enables instance-specific text-to-image generation and also achieves strong performance on visual question answering.
Temporally Consistent Object-Centric Learning by Contrasting Slots
Dec 18, 2024



Unsupervised object-centric learning from videos is a promising approach to extract structured representations from large, unlabeled collections of videos. To support downstream tasks like autonomous control, these representations must be both compositional and temporally consistent. Existing approaches based on recurrent processing often lack long-term stability across frames because their training objective does not enforce temporal consistency. In this work, we introduce a novel object-level temporal contrastive loss for video object-centric models that explicitly promotes temporal consistency. Our method significantly improves the temporal consistency of the learned object-centric representations, yielding more reliable video decompositions that facilitate challenging downstream tasks such as unsupervised object dynamics prediction. Furthermore, the inductive bias added by our loss strongly improves object discovery, leading to state-of-the-art results on both synthetic and real-world datasets, outperforming even weakly-supervised methods that leverage motion masks as additional cues.
Zero-Shot Object-Centric Representation Learning
Aug 17, 2024



The goal of object-centric representation learning is to decompose visual scenes into a structured representation that isolates the entities. Recent successes have shown that object-centric representation learning can be scaled to real-world scenes by utilizing pre-trained self-supervised features. However, so far, object-centric methods have mostly been applied in-distribution, with models trained and evaluated on the same dataset. This is in contrast to the wider trend in machine learning towards general-purpose models directly applicable to unseen data and tasks. Thus, in this work, we study current object-centric methods through the lens of zero-shot generalization by introducing a benchmark comprising eight different synthetic and real-world datasets. We analyze the factors influencing zero-shot performance and find that training on diverse real-world images improves transferability to unseen scenarios. Furthermore, inspired by the success of task-specific fine-tuning in foundation models, we introduce a novel fine-tuning strategy to adapt pre-trained vision encoders for the task of object discovery. We find that the proposed approach results in state-of-the-art performance for unsupervised object discovery, exhibiting strong zero-shot transfer to unseen datasets.
DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Oct 09, 2023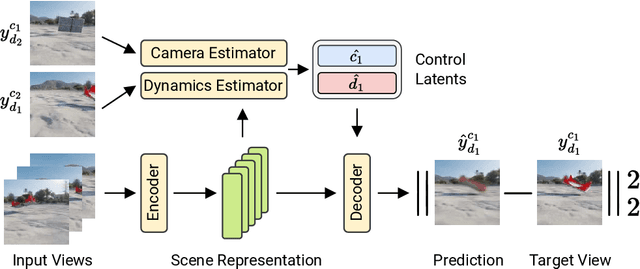
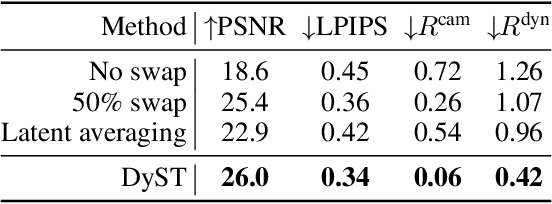


Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
Object-Centric Learning for Real-World Videos by Predicting Temporal Feature Similarities
Jun 07, 2023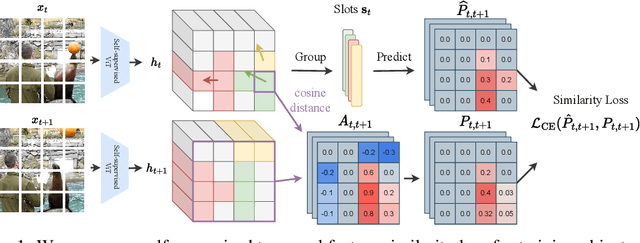
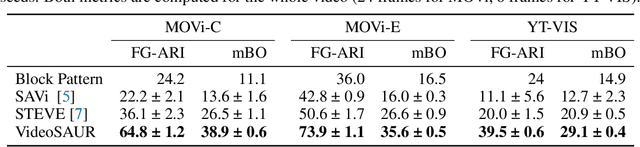
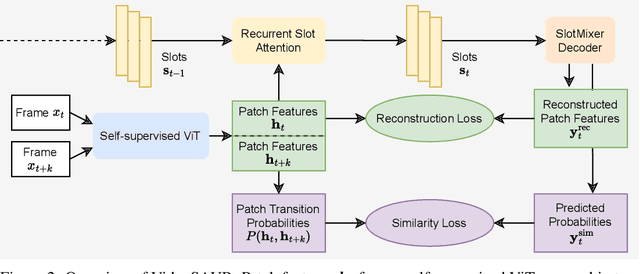

Unsupervised video-based object-centric learning is a promising avenue to learn structured representations from large, unlabeled video collections, but previous approaches have only managed to scale to real-world datasets in restricted domains. Recently, it was shown that the reconstruction of pre-trained self-supervised features leads to object-centric representations on unconstrained real-world image datasets. Building on this approach, we propose a novel way to use such pre-trained features in the form of a temporal feature similarity loss. This loss encodes temporal correlations between image patches and is a natural way to introduce a motion bias for object discovery. We demonstrate that this loss leads to state-of-the-art performance on the challenging synthetic MOVi datasets. When used in combination with the feature reconstruction loss, our model is the first object-centric video model that scales to unconstrained video datasets such as YouTube-VIS.
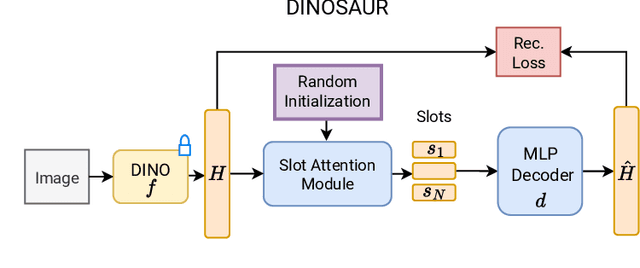
Bridging the Gap to Real-World Object-Centric Learning
Sep 29, 2022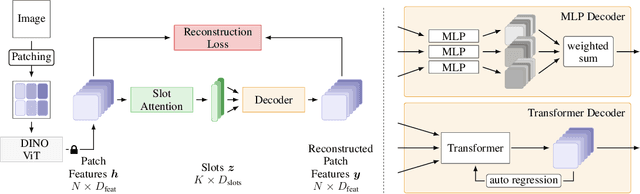
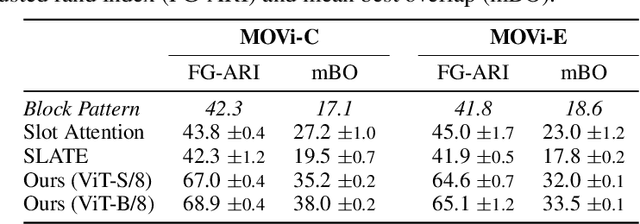


Humans naturally decompose their environment into entities at the appropriate level of abstraction to act in the world. Allowing machine learning algorithms to derive this decomposition in an unsupervised way has become an important line of research. However, current methods are restricted to simulated data or require additional information in the form of motion or depth in order to successfully discover objects. In this work, we overcome this limitation by showing that reconstructing features from models trained in a self-supervised manner is a sufficient training signal for object-centric representations to arise in a fully unsupervised way. Our approach, DINOSAUR, significantly out-performs existing object-centric learning models on simulated data and is the first unsupervised object-centric model that scales to real world-datasets such as COCO and PASCAL VOC. DINOSAUR is conceptually simple and shows competitive performance compared to more involved pipelines from the computer vision literature.
On the Pitfalls of Heteroscedastic Uncertainty Estimation with Probabilistic Neural Networks
Apr 01, 2022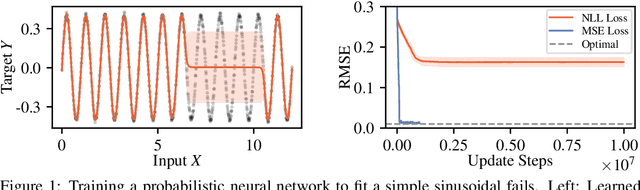
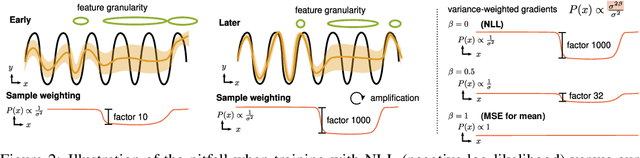
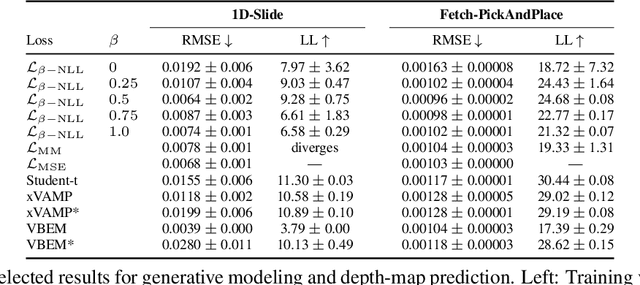
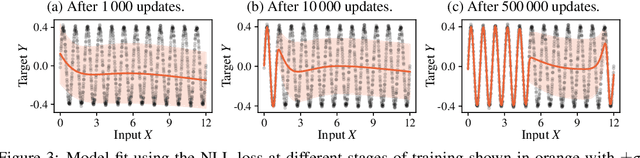
Capturing aleatoric uncertainty is a critical part of many machine learning systems. In deep learning, a common approach to this end is to train a neural network to estimate the parameters of a heteroscedastic Gaussian distribution by maximizing the logarithm of the likelihood function under the observed data. In this work, we examine this approach and identify potential hazards associated with the use of log-likelihood in conjunction with gradient-based optimizers. First, we present a synthetic example illustrating how this approach can lead to very poor but stable parameter estimates. Second, we identify the culprit to be the log-likelihood loss, along with certain conditions that exacerbate the issue. Third, we present an alternative formulation, termed $\beta$-NLL, in which each data point's contribution to the loss is weighted by the $\beta$-exponentiated variance estimate. We show that using an appropriate $\beta$ largely mitigates the issue in our illustrative example. Fourth, we evaluate this approach on a range of domains and tasks and show that it achieves considerable improvements and performs more robustly concerning hyperparameters, both in predictive RMSE and log-likelihood criteria.