 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Universal Perception Encoder
Mar 23, 2026Running AI models on smart edge devices can unlock versatile user experiences, but presents challenges due to limited compute and the need to handle multiple tasks simultaneously. This requires a vision encoder with small size but powerful and versatile representations. We present our method, Efficient Universal Perception Encoder (EUPE), which offers both inference efficiency and universally good representations for diverse downstream tasks. We achieve this by distilling from multiple domain-expert foundation vision encoders. Unlike previous agglomerative methods that directly scale down from multiple teachers to an efficient encoder, we demonstrate the importance of first scaling up to a large proxy teacher and then scaling down from this single teacher. Experiments show that EUPE achieves on-par or better performance than individual domain experts of the same size on diverse task domains and also outperforms previous agglomerative encoders. We will release the full family of EUPE models and the code to foster future research.
DINOv3
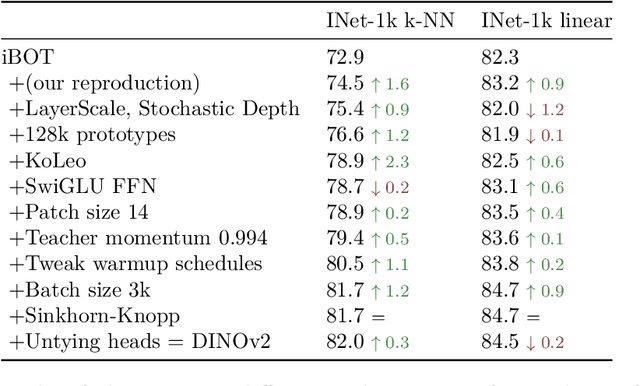
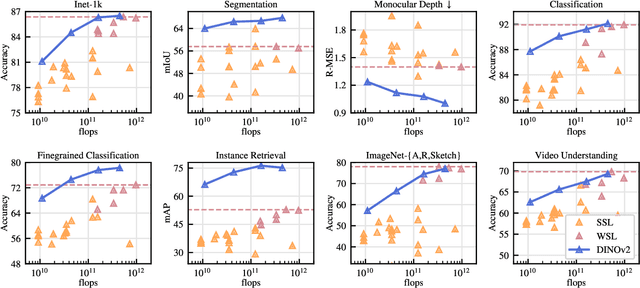
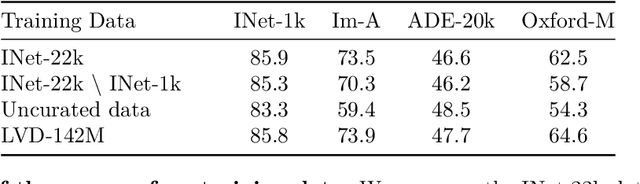
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Cluster and Predict Latents Patches for Improved Masked Image Modeling
Feb 12, 2025Masked Image Modeling (MIM) offers a promising approach to self-supervised representation learning, however existing MIM models still lag behind the state-of-the-art. In this paper, we systematically analyze target representations, loss functions, and architectures, to introduce CAPI - a novel pure-MIM framework that relies on the prediction of latent clusterings. Our approach leverages a clustering-based loss, which is stable to train, and exhibits promising scaling properties. Our ViT-L backbone, CAPI, achieves 83.8% accuracy on ImageNet and 32.1% mIoU on ADE20K with simple linear probes, substantially outperforming previous MIM methods and approaching the performance of the current state-of-the-art, DINOv2. We release all our code and models.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
You Don't Need Data-Augmentation in Self-Supervised Learning
Jun 13, 2024



Self-Supervised learning (SSL) with Joint-Embedding Architectures (JEA) has led to outstanding performances. All instantiations of this paradigm were trained using strong and well-established hand-crafted data augmentations, leading to the general belief that they are required for the proper training and performance of such models. On the other hand, generative reconstruction-based models such as BEIT and MAE or Joint-Embedding Predictive Architectures such as I-JEPA have shown strong performance without using data augmentations except masking. In this work, we challenge the importance of invariance and data-augmentation in JEAs at scale. By running a case-study on a recent SSL foundation model - DINOv2 - we show that strong image representations can be obtained with JEAs and only cropping without resizing provided the training data is large enough, reaching state-of-the-art results and using the least amount of augmentation in the literature. Through this study, we also discuss the impact of compute constraints on the outcomes of experimental deep learning research, showing that they can lead to very different conclusions.
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
May 24, 2024Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
Advancing human-centric AI for robust X-ray analysis through holistic self-supervised learning
May 02, 2024



AI Foundation models are gaining traction in various applications, including medical fields like radiology. However, medical foundation models are often tested on limited tasks, leaving their generalisability and biases unexplored. We present RayDINO, a large visual encoder trained by self-supervision on 873k chest X-rays. We compare RayDINO to previous state-of-the-art models across nine radiology tasks, from classification and dense segmentation to text generation, and provide an in depth analysis of population, age and sex biases of our model. Our findings suggest that self-supervision allows patient-centric AI proving useful in clinical workflows and interpreting X-rays holistically. With RayDINO and small task-specific adapters, we reach state-of-the-art results and improve generalization to unseen populations while mitigating bias, illustrating the true promise of foundation models: versatility and robustness.
Vision Transformers Need Registers
Sep 28, 2023



Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
Co-training $2^L$ Submodels for Visual Recognition
Dec 09, 2022We introduce submodel co-training, a regularization method related to co-training, self-distillation and stochastic depth. Given a neural network to be trained, for each sample we implicitly instantiate two altered networks, ``submodels'', with stochastic depth: we activate only a subset of the layers. Each network serves as a soft teacher to the other, by providing a loss that complements the regular loss provided by the one-hot label. Our approach, dubbed cosub, uses a single set of weights, and does not involve a pre-trained external model or temporal averaging. Experimentally, we show that submodel co-training is effective to train backbones for recognition tasks such as image classification and semantic segmentation. Our approach is compatible with multiple architectures, including RegNet, ViT, PiT, XCiT, Swin and ConvNext. Our training strategy improves their results in comparable settings. For instance, a ViT-B pretrained with cosub on ImageNet-21k obtains 87.4% top-1 acc. @448 on ImageNet-val.