 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Stationary Functional Bilevel Optimization
Jan 21, 2026Functional bilevel optimization (FBO) provides a powerful framework for hierarchical learning in function spaces, yet current methods are limited to static offline settings and perform suboptimally in online, non-stationary scenarios. We propose SmoothFBO, the first algorithm for non-stationary FBO with both theoretical guarantees and practical scalability. SmoothFBO introduces a time-smoothed stochastic hypergradient estimator that reduces variance through a window parameter, enabling stable outer-loop updates with sublinear regret. Importantly, the classical parametric bilevel case is a special reduction of our framework, making SmoothFBO a natural extension to online, non-stationary settings. Empirically, SmoothFBO consistently outperforms existing FBO methods in non-stationary hyperparameter optimization and model-based reinforcement learning, demonstrating its practical effectiveness. Together, these results establish SmoothFBO as a general, theoretically grounded, and practically viable foundation for bilevel optimization in online, non-stationary scenarios.
Optimal transport unlocks end-to-end learning for single-molecule localization
Dec 11, 2025Single-molecule localization microscopy (SMLM) allows reconstructing biology-relevant structures beyond the diffraction limit by detecting and localizing individual fluorophores -- fluorescent molecules stained onto the observed specimen -- over time to reconstruct super-resolved images. Currently, efficient SMLM requires non-overlapping emitting fluorophores, leading to long acquisition times that hinders live-cell imaging. Recent deep-learning approaches can handle denser emissions, but they rely on variants of non-maximum suppression (NMS) layers, which are unfortunately non-differentiable and may discard true positives with their local fusion strategy. In this presentation, we reformulate the SMLM training objective as a set-matching problem, deriving an optimal-transport loss that eliminates the need for NMS during inference and enables end-to-end training. Additionally, we propose an iterative neural network that integrates knowledge of the microscope's optical system inside our model. Experiments on synthetic benchmarks and real biological data show that both our new loss function and architecture surpass the state of the art at moderate and high emitter densities. Code is available at https://github.com/RSLLES/SHOT.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Unsupervised Imaging Inverse Problems with Diffusion Distribution Matching
Jun 17, 2025This work addresses image restoration tasks through the lens of inverse problems using unpaired datasets. In contrast to traditional approaches -- which typically assume full knowledge of the forward model or access to paired degraded and ground-truth images -- the proposed method operates under minimal assumptions and relies only on small, unpaired datasets. This makes it particularly well-suited for real-world scenarios, where the forward model is often unknown or misspecified, and collecting paired data is costly or infeasible. The method leverages conditional flow matching to model the distribution of degraded observations, while simultaneously learning the forward model via a distribution-matching loss that arises naturally from the framework. Empirically, it outperforms both single-image blind and unsupervised approaches on deblurring and non-uniform point spread function (PSF) calibration tasks. It also matches state-of-the-art performance on blind super-resolution. We also showcase the effectiveness of our method with a proof of concept for lens calibration: a real-world application traditionally requiring time-consuming experiments and specialized equipment. In contrast, our approach achieves this with minimal data acquisition effort.
MicroFlow: Domain-Specific Optical Flow for Ground Deformation Estimation in Seismic Events
Apr 18, 2025Dense ground displacement measurements are crucial for geological studies but are impractical to collect directly. Traditionally, displacement fields are estimated using patch matching on optical satellite images from different acquisition times. While deep learning-based optical flow models are promising, their adoption in ground deformation analysis is hindered by challenges such as the absence of real ground truth, the need for sub-pixel precision, and temporal variations due to geological or anthropogenic changes. In particular, we identify that deep learning models relying on explicit correlation layers struggle at estimating small displacements in real-world conditions. Instead, we propose a model that employs iterative refinements with explicit warping layers and a correlation-independent backbone, enabling sub-pixel precision. Additionally, a non-convex variant of Total Variation regularization preserves fault-line sharpness while maintaining smoothness elsewhere. Our model significantly outperforms widely used geophysics methods on semi-synthetic benchmarks and generalizes well to challenging real-world scenarios captured by both medium- and high-resolution sensors. Project page: https://jbertrand89.github.io/microflow/.
A New Statistical Model of Star Speckles for Learning to Detect and Characterize Exoplanets in Direct Imaging Observations
Mar 21, 2025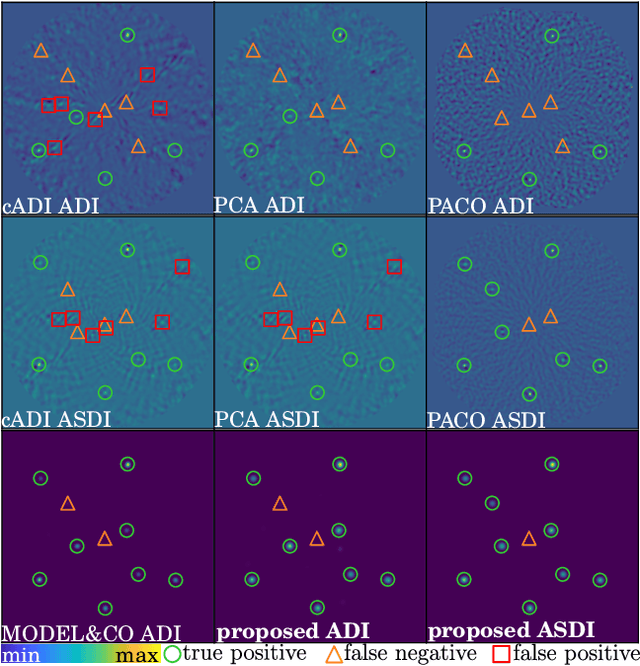
The search for exoplanets is an active field in astronomy, with direct imaging as one of the most challenging methods due to faint exoplanet signals buried within stronger residual starlight. Successful detection requires advanced image processing to separate the exoplanet signal from this nuisance component. This paper presents a novel statistical model that captures nuisance fluctuations using a multi-scale approach, leveraging problem symmetries and a joint spectral channel representation grounded in physical principles. Our model integrates into an interpretable, end-to-end learnable framework for simultaneous exoplanet detection and flux estimation. The proposed algorithm is evaluated against the state of the art using datasets from the SPHERE instrument operating at the Very Large Telescope (VLT). It significantly improves the precision-recall trade-off, notably on challenging datasets that are otherwise unusable by astronomers. The proposed approach is computationally efficient, robust to varying data quality, and well suited for large-scale observational surveys.
Cluster and Predict Latents Patches for Improved Masked Image Modeling
Feb 12, 2025Masked Image Modeling (MIM) offers a promising approach to self-supervised representation learning, however existing MIM models still lag behind the state-of-the-art. In this paper, we systematically analyze target representations, loss functions, and architectures, to introduce CAPI - a novel pure-MIM framework that relies on the prediction of latent clusterings. Our approach leverages a clustering-based loss, which is stable to train, and exhibits promising scaling properties. Our ViT-L backbone, CAPI, achieves 83.8% accuracy on ImageNet and 32.1% mIoU on ADE20K with simple linear probes, substantially outperforming previous MIM methods and approaching the performance of the current state-of-the-art, DINOv2. We release all our code and models.
LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes
Oct 18, 2024



We address the task of uplifting visual features or semantic masks from 2D vision models to 3D scenes represented by Gaussian Splatting. Whereas common approaches rely on iterative optimization-based procedures, we show that a simple yet effective aggregation technique yields excellent results. Applied to semantic masks from Segment Anything (SAM), our uplifting approach leads to segmentation quality comparable to the state of the art. We then extend this method to generic DINOv2 features, integrating 3D scene geometry through graph diffusion, and achieve competitive segmentation results despite DINOv2 not being trained on millions of annotated masks like SAM.
SpectralEarth: Training Hyperspectral Foundation Models at Scale
Aug 15, 2024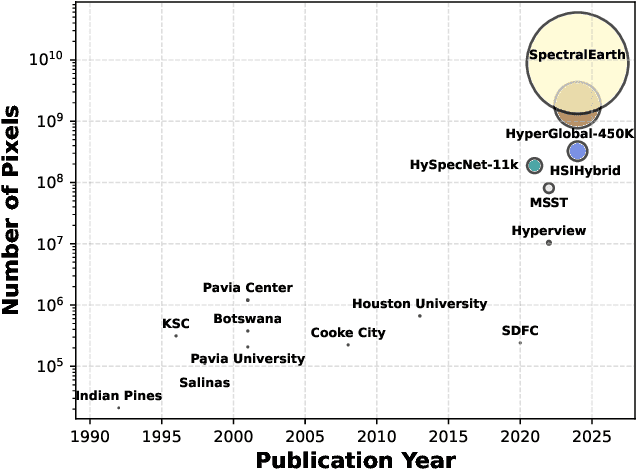
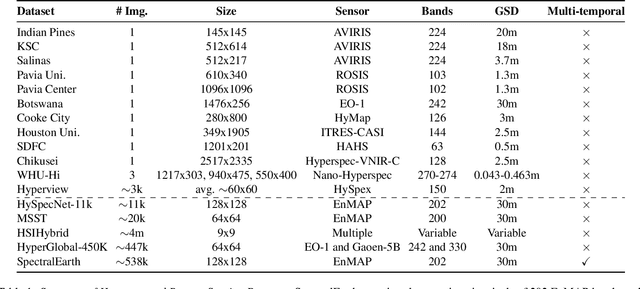

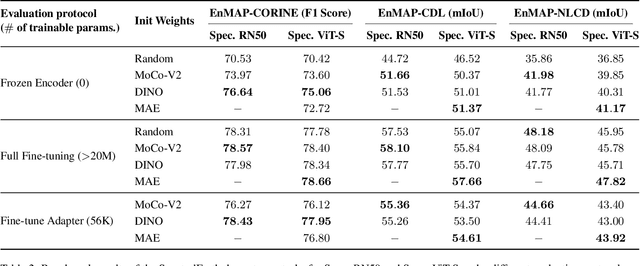
Foundation models have triggered a paradigm shift in computer vision and are increasingly being adopted in remote sensing, particularly for multispectral imagery. Yet, their potential in hyperspectral imaging (HSI) remains untapped due to the absence of comprehensive and globally representative hyperspectral datasets. To close this gap, we introduce SpectralEarth, a large-scale multi-temporal dataset designed to pretrain hyperspectral foundation models leveraging data from the Environmental Mapping and Analysis Program (EnMAP). SpectralEarth comprises 538,974 image patches covering 415,153 unique locations from more than 11,636 globally distributed EnMAP scenes spanning two years of archive. Additionally, 17.5% of these locations include multiple timestamps, enabling multi-temporal HSI analysis. Utilizing state-of-the-art self-supervised learning (SSL) algorithms, we pretrain a series of foundation models on SpectralEarth. We integrate a spectral adapter into classical vision backbones to accommodate the unique characteristics of HSI. In tandem, we construct four downstream datasets for land-cover and crop-type mapping, providing benchmarks for model evaluation. Experimental results support the versatility of our models, showcasing their generalizability across different tasks and sensors. We also highlight computational efficiency during model fine-tuning. The dataset, models, and source code will be made publicly available.
Functional Bilevel Optimization for Machine Learning
Mar 29, 2024


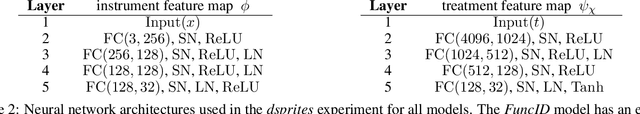
In this paper, we introduce a new functional point of view on bilevel optimization problems for machine learning, where the inner objective is minimized over a function space. These types of problems are most often solved by using methods developed in the parametric setting, where the inner objective is strongly convex with respect to the parameters of the prediction function. The functional point of view does not rely on this assumption and notably allows using over-parameterized neural networks as the inner prediction function. We propose scalable and efficient algorithms for the functional bilevel optimization problem and illustrate the benefits of our approach on instrumental regression and reinforcement learning tasks, which admit natural functional bilevel structures.