 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe data heat island effect: quantifying the impact of AI data centers in a warming world
Mar 21, 2026The strong and continuous increase of AI-based services leads to the steady proliferation of AI data centres worldwide with the unavoidable escalation of their power consumption. It is unknown how this energy demand for computational purposes will impact the surrounding environment. Here, we focus our attention on the heat dissipation of AI hyperscalers. Taking advantage of land surface temperature measurements acquired by remote sensing platforms over the last decades, we are able to obtain a robust assessment of the temperature increase recorded in the areas surrounding AI data centres globally. We estimate that the land surface temperature increases by 2°C on average after the start of operations of an AI data centre, inducing local microclimate zones, which we call the data heat island effect. We assess the impact on the communities, quantifying that more than 340 million people could be affected by this temperature increase. Our results show that the data heat island effect could have a remarkable influence on communities and regional welfare in the future, hence becoming part of the conversation around environmentally sustainable AI worldwide.
Foundation Models in Remote Sensing: Evolving from Unimodality to Multimodality
Mar 01, 2026Remote sensing (RS) techniques are increasingly crucial for deepening our understanding of the planet. As the volume and diversity of RS data continue to grow exponentially, there is an urgent need for advanced data modeling and understanding capabilities to manage and interpret these vast datasets effectively. Foundation models present significant new growth opportunities and immense potential to revolutionize the RS field. In this paper, we conduct a comprehensive technical survey on foundation models in RS, offering a brand-new perspective by exploring their evolution from unimodality to multimodality. We hope this work serves as a valuable entry point for researchers interested in both foundation models and RS and helps them launch new projects or explore new research topics in this rapidly evolving area. This survey addresses the following three key questions: What are foundation models in RS? Why are foundation models needed in RS? How can we effectively guide junior researchers in gaining a comprehensive and practical understanding of foundation models in RS applications? More specifically, we begin by outlining the background and motivation, emphasizing the importance of foundation models in RS. We then review existing foundation models in RS, systematically categorizing them into unimodal and multimodal approaches. Additionally, we provide a tutorial-like section to guide researchers, especially beginners, on how to train foundation models in RS and apply them to real-world tasks. The survey aims to equip researchers in RS with a deeper and more efficient understanding of foundation models, enabling them to get started easily and effectively apply these models across various RS applications.
KANO: Kolmogorov-Arnold Neural Operator for Image Super-Resolution
Dec 28, 2025The highly nonlinear degradation process, complex physical interactions, and various sources of uncertainty render single-image Super-resolution (SR) a particularly challenging task. Existing interpretable SR approaches, whether based on prior learning or deep unfolding optimization frameworks, typically rely on black-box deep networks to model latent variables, which leaves the degradation process largely unknown and uncontrollable. Inspired by the Kolmogorov-Arnold theorem (KAT), we for the first time propose a novel interpretable operator, termed Kolmogorov-Arnold Neural Operator (KANO), with the application to image SR. KANO provides a transparent and structured representation of the latent degradation fitting process. Specifically, we employ an additive structure composed of a finite number of B-spline functions to approximate continuous spectral curves in a piecewise fashion. By learning and optimizing the shape parameters of these spline functions within defined intervals, our KANO accurately captures key spectral characteristics, such as local linear trends and the peak-valley structures at nonlinear inflection points, thereby endowing SR results with physical interpretability. Furthermore, through theoretical modeling and experimental evaluations across natural images, aerial photographs, and satellite remote sensing data, we systematically compare multilayer perceptrons (MLPs) and Kolmogorov-Arnold networks (KANs) in handling complex sequence fitting tasks. This comparative study elucidates the respective advantages and limitations of these models in characterizing intricate degradation mechanisms, offering valuable insights for the development of interpretable SR techniques.
Hyperspectral Imaging
Aug 11, 2025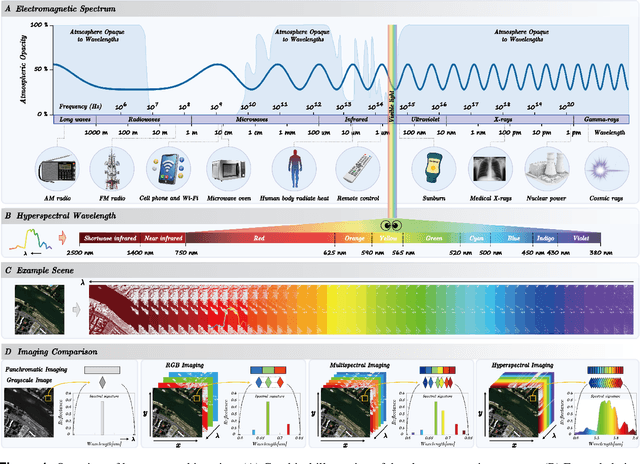
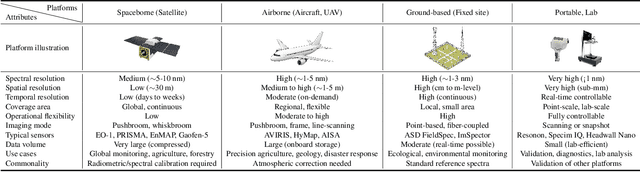
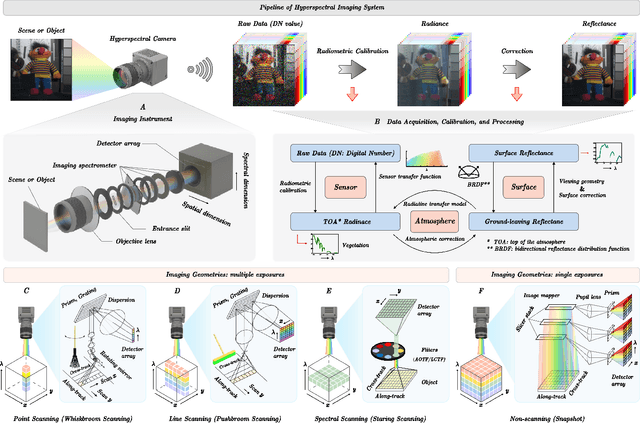

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
Prospects for Mitigating Spectral Variability in Tropical Species Classification Using Self-Supervised Learning
Mar 17, 2025Airborne hyperspectral imaging is a promising method for identifying tropical species, but spectral variability between acquisitions hinders consistent results. This paper proposes using Self-Supervised Learning (SSL) to encode spectral features that are robust to abiotic variability and relevant for species identification. By employing the state-of-the-art Barlow-Twins approach on repeated spectral acquisitions, we demonstrate the ability to develop stable features. For the classification of 40 tropical species, experiments show that these features can outperform typical reflectance products in terms of robustness to spectral variability by 10 points of accuracy across dates.
* 5 pages, 3 figures, published as proceeding of the "2024 14th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS)"
UrbanSAM: Learning Invariance-Inspired Adapters for Segment Anything Models in Urban Construction
Feb 21, 2025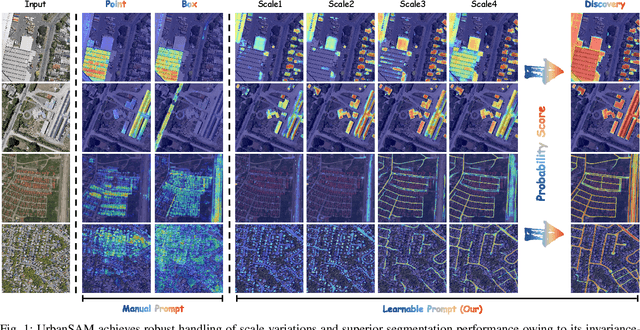
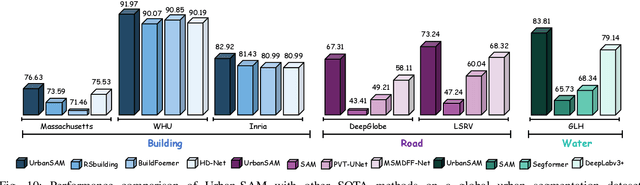
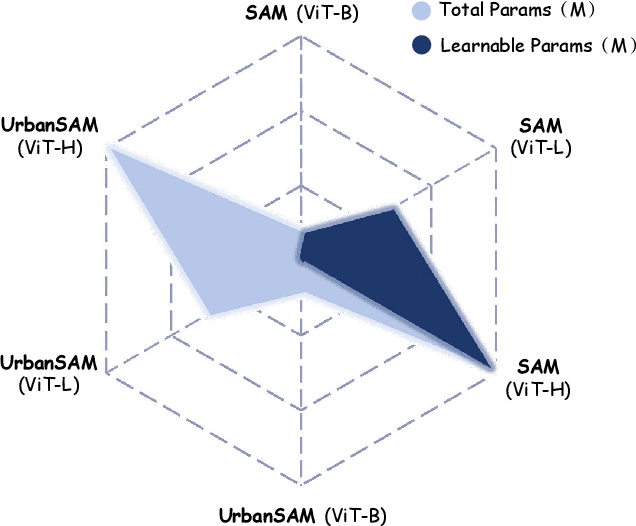
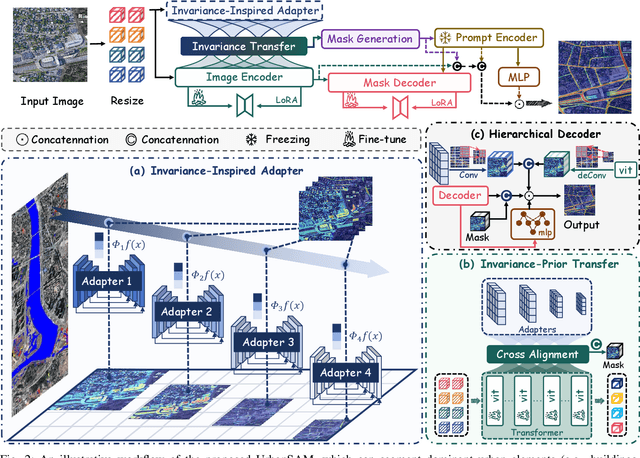
Object extraction and segmentation from remote sensing (RS) images is a critical yet challenging task in urban environment monitoring. Urban morphology is inherently complex, with irregular objects of diverse shapes and varying scales. These challenges are amplified by heterogeneity and scale disparities across RS data sources, including sensors, platforms, and modalities, making accurate object segmentation particularly demanding. While the Segment Anything Model (SAM) has shown significant potential in segmenting complex scenes, its performance in handling form-varying objects remains limited due to manual-interactive prompting. To this end, we propose UrbanSAM, a customized version of SAM specifically designed to analyze complex urban environments while tackling scaling effects from remotely sensed observations. Inspired by multi-resolution analysis (MRA) theory, UrbanSAM incorporates a novel learnable prompter equipped with a Uscaling-Adapter that adheres to the invariance criterion, enabling the model to capture multiscale contextual information of objects and adapt to arbitrary scale variations with theoretical guarantees. Furthermore, features from the Uscaling-Adapter and the trunk encoder are aligned through a masked cross-attention operation, allowing the trunk encoder to inherit the adapter's multiscale aggregation capability. This synergy enhances the segmentation performance, resulting in more powerful and accurate outputs, supported by the learned adapter. Extensive experimental results demonstrate the flexibility and superior segmentation performance of the proposed UrbanSAM on a global-scale dataset, encompassing scale-varying urban objects such as buildings, roads, and water.
A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Feb 05, 2025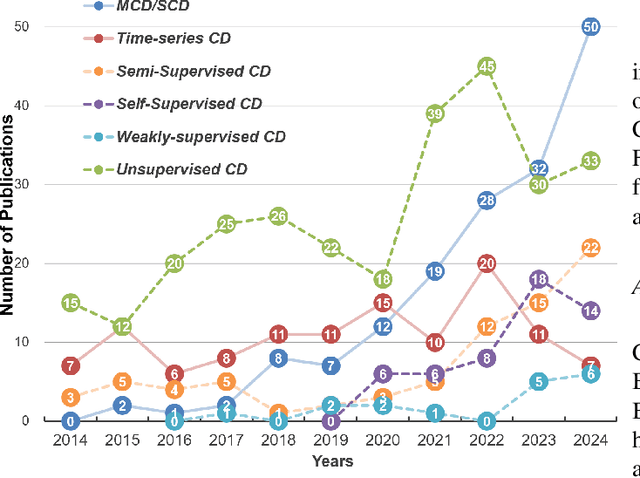
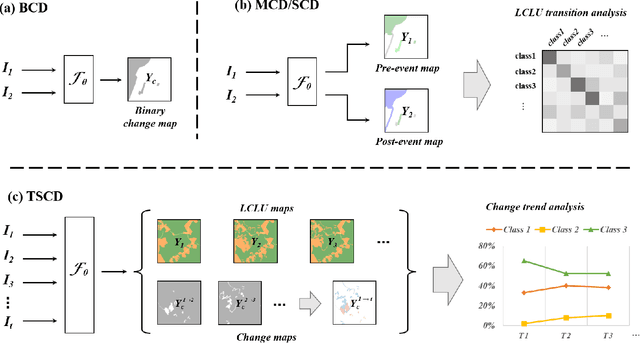
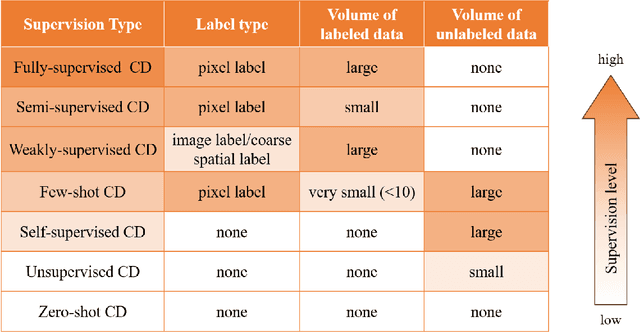
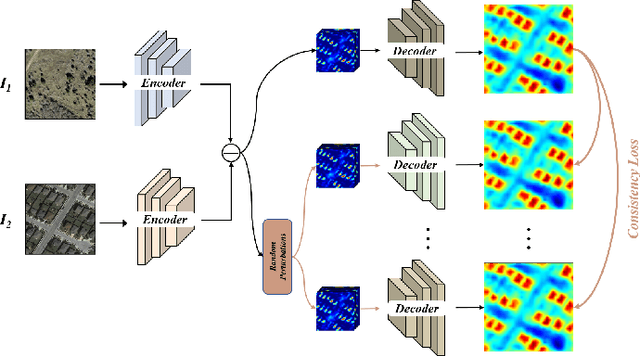
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the 'data-hungry' issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.
SeaMo: A Multi-Seasonal and Multimodal Remote Sensing Foundation Model
Dec 26, 2024



Remote Sensing (RS) data contains a wealth of multi-dimensional information crucial for Earth observation. Owing to its vast volume, diverse sources, and temporal properties, RS data is highly suitable for the development of large Visual Foundation Models (VFMs). VFMs act as robust feature extractors, learning from extensive RS data, and are subsequently fine-tuned for deployment in various geoscientific tasks. However, current VFMs in the RS domain are predominantly pretrained and tailored exclusively for specific characteristics of RS imagery, neglecting the potential of utilizing the multi-dimensional properties of RS data. Therefore, in this work, we propose SeaMo, a pioneering visual foundation model that integrates multi-seasonal and multimodal information in the RS field. SeaMo is designed to harness multiple properties of RS data. Within the masked image modeling framework, we employ non-aligned cropping techniques to extract spatial properties, use multi-source inputs for multimodal integration, and incorporate temporal-multimodal fusion blocks for effective assimilation of multi-seasonal data. SeaMo explicitly models the multi-dimensional properties of RS data, making the model more comprehensive, robust, and versatile. We applied SeaMo to several downstream geoscience tasks, which demonstrated exceptional performance. Extensive ablation studies were conducted to validate the model's superiority.
Dual-Branch Subpixel-Guided Network for Hyperspectral Image Classification
Dec 05, 2024



Deep learning (DL) has been widely applied into hyperspectral image (HSI) classification owing to its promising feature learning and representation capabilities. However, limited by the spatial resolution of sensors, existing DL-based classification approaches mainly focus on pixel-level spectral and spatial information extraction through complex network architecture design, while ignoring the existence of mixed pixels in actual scenarios. To tackle this difficulty, we propose a novel dual-branch subpixel-guided network for HSI classification, called DSNet, which automatically integrates subpixel information and convolutional class features by introducing a deep autoencoder unmixing architecture to enhance classification performance. DSNet is capable of fully considering physically nonlinear properties within subpixels and adaptively generating diagnostic abundances in an unsupervised manner to achieve more reliable decision boundaries for class label distributions. The subpixel fusion module is designed to ensure high-quality information fusion across pixel and subpixel features, further promoting stable joint classification. Experimental results on three benchmark datasets demonstrate the effectiveness and superiority of DSNet compared with state-of-the-art DL-based HSI classification approaches. The codes will be available at https://github.com/hanzhu97702/DSNet, contributing to the remote sensing community.
Multisource Collaborative Domain Generalization for Cross-Scene Remote Sensing Image Classification
Dec 05, 2024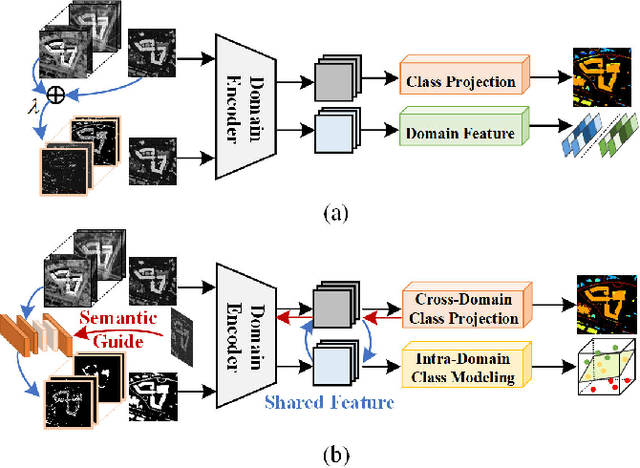

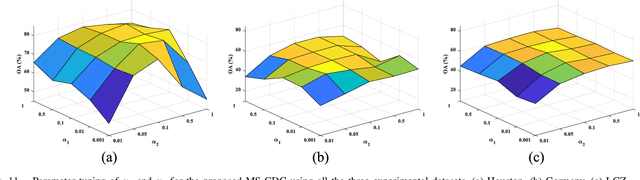
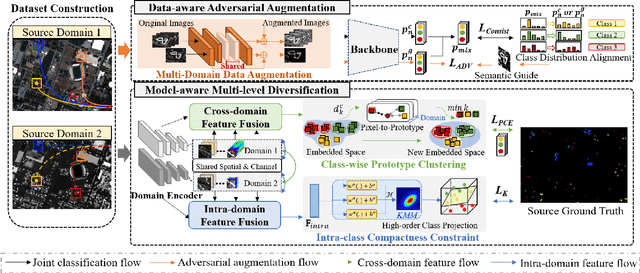
Cross-scene image classification aims to transfer prior knowledge of ground materials to annotate regions with different distributions and reduce hand-crafted cost in the field of remote sensing. However, existing approaches focus on single-source domain generalization to unseen target domains, and are easily confused by large real-world domain shifts due to the limited training information and insufficient diversity modeling capacity. To address this gap, we propose a novel multi-source collaborative domain generalization framework (MS-CDG) based on homogeneity and heterogeneity characteristics of multi-source remote sensing data, which considers data-aware adversarial augmentation and model-aware multi-level diversification simultaneously to enhance cross-scene generalization performance. The data-aware adversarial augmentation adopts an adversary neural network with semantic guide to generate MS samples by adaptively learning realistic channel and distribution changes across domains. In views of cross-domain and intra-domain modeling, the model-aware diversification transforms the shared spatial-channel features of MS data into the class-wise prototype and kernel mixture module, to address domain discrepancies and cluster different classes effectively. Finally, the joint classification of original and augmented MS samples is employed by introducing a distribution consistency alignment to increase model diversity and ensure better domain-invariant representation learning. Extensive experiments on three public MS remote sensing datasets demonstrate the superior performance of the proposed method when benchmarked with the state-of-the-art methods.