 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-guided Fusion of Multimodal Features for Change Detection from Optical-SAR Images
Apr 07, 2026Multimodal change detection (MMCD) identifies changed areas in multimodal remote sensing (RS) data, demonstrating significant application value in land use monitoring, disaster assessment, and urban sustainable development. However, literature MMCD approaches exhibit limitations in cross-modal interaction and exploiting modality-specific characteristics. This leads to insufficient modeling of fine-grained change information, thus hindering the precise detection of semantic changes in multimodal data. To address the above problems, we propose STSF-Net, a framework designed for MMCD between optical and SAR images. STSF-Net jointly models modality-specific and spatio-temporal common features to enhance change representations. Specifically, modality-specific features are exploited to capture genuine semantic change signals, while spatio-temporal common features are embedded to suppress pseudo-changes caused by differences in imaging mechanisms. Furthermore, we introduce an optical and SAR feature fusion strategy that adaptively adjusts feature importance based on semantic priors obtained from pre-trained foundational models, enabling semantic-guided adaptive fusion of multi-modal information. In addition, we introduce the Delta-SN6 dataset, the first openly-accessible multiclass MMCD benchmark consisting of very-high-resolution (VHR) fully polarimetric SAR and optical images. Experimental results on Delta-SN6, BRIGHT, and Wuhan-Het datasets demonstrate that our method outperforms the state-of-the-art (SOTA) by 3.21%, 1.08%, and 1.32% in mIoU, respectively. The associated code and Delta-SN6 dataset will be released at: https://github.com/liuxuanguang/STSF-Net.
VFM-Loc: Zero-Shot Cross-View Geo-Localization via Aligning Discriminative Visual Hierarchies
Mar 14, 2026Cross-View Geo-Localization (CVGL) in remote sensing aims to locate a drone-view query by matching it to geo-tagged satellite images. Although supervised methods have achieved strong results on closeset benchmarks, they often fail to generalize to unconstrained, real-world scenarios due to severe viewpoint differences and dataset bias. To overcome these limitations, we present VFM-Loc, a training-free framework for zero-shot CVGL that leverages the generalizable visual representations from vision foundational models (VFMs). VFM-Loc identifies and matches discriminative visual clues across different viewpoints through a progressive alignment strategy. First, we design a hierarchical clue extraction mechanism using Generalized Mean pooling and Scale-Weighted RMAC to preserve distinctive visual clues across scales while maintaining hierarchical confidence. Second, we introduce a statistical manifold alignment pipeline based on domain-wise PCA and Orthogonal Procrustes analysis, linearly aligning heterogeneous feature distributions in a shared metric space. Experiments demonstrate that VFM-Loc exhibits strong zero-shot accuracy on standard benchmarks and surpasses supervised methods by over 20% in Recall@1 on the challenging LO-UCV dataset with large oblique angles. This work highlights that principled alignment of pre-trained features can effectively bridge the cross-view gap, establishing a robust and training-free paradigm for real-world CVGL. The relevant code is made available at: https://github.com/DingLei14/VFM-Loc.
Enhancing TableQA through Verifiable Reasoning Trace Reward
Jan 30, 2026A major challenge in training TableQA agents, compared to standard text- and image-based agents, is that answers cannot be inferred from a static input but must be reasoned through stepwise transformations of the table state, introducing multi-step reasoning complexity and environmental interaction. This leads to a research question: Can explicit feedback on table transformation action improve model reasoning capability? In this work, we introduce RE-Tab, a plug-and-play framework that architecturally enhances trajectory search via lightweight, training-free reward modeling by formulating the problem as a Partially Observable Markov Decision Process. We demonstrate that providing explicit verifiable rewards during State Transition (``What is the best action?'') and Simulative Reasoning (``Am I sure about the output?'') is crucial to steer the agent's navigation in table states. By enforcing stepwise reasoning with reward feedback in table transformations, RE-Tab achieves state-of-the-art performance in TableQA with almost 25\% drop in inference cost. Furthermore, a direct plug-and-play implementation of RE-Tab brings up to 41.77% improvement in QA accuracy and 33.33% drop in test-time inference samples for consistent answer. Consistent improvement pattern across various LLMs and state-of-the-art benchmarks further confirms RE-Tab's generalisability. The repository is available at https://github.com/ThomasK1018/RE_Tab .
Dynamic Quantization Error Propagation in Encoder-Decoder ASR Quantization
Jan 05, 2026Running Automatic Speech Recognition (ASR) models on memory-constrained edge devices requires efficient compression. While layer-wise post-training quantization is effective, it suffers from error accumulation, especially in encoder-decoder architectures. Existing solutions like Quantization Error Propagation (QEP) are suboptimal for ASR due to the model's heterogeneity, processing acoustic features in the encoder while generating text in the decoder. To address this, we propose Fine-grained Alpha for Dynamic Quantization Error Propagation (FADE), which adaptively controls the trade-off between cross-layer error correction and local quantization. Experiments show that FADE significantly improves stability by reducing performance variance across runs, while simultaneously surpassing baselines in mean WER.
S2C: Learning Noise-Resistant Differences for Unsupervised Change Detection in Multimodal Remote Sensing Images
Feb 18, 2025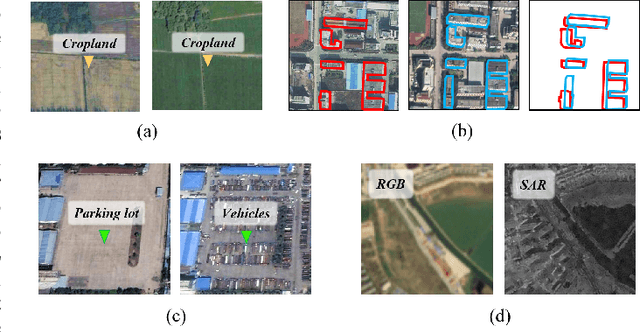
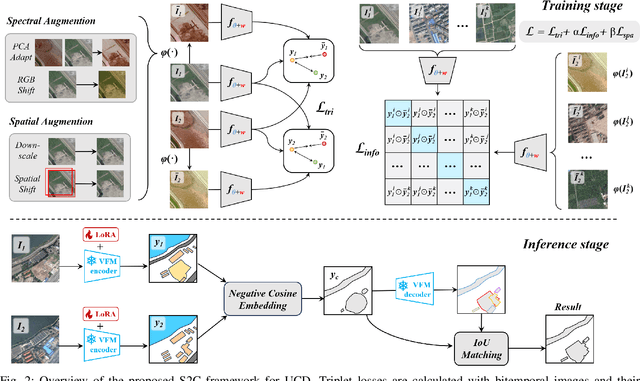
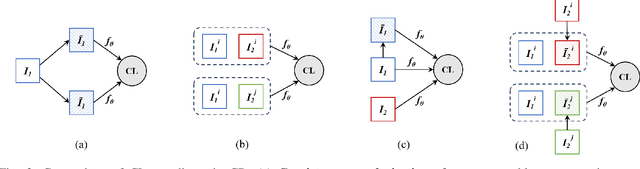

Unsupervised Change Detection (UCD) in multimodal Remote Sensing (RS) images remains a difficult challenge due to the inherent spatio-temporal complexity within data, and the heterogeneity arising from different imaging sensors. Inspired by recent advancements in Visual Foundation Models (VFMs) and Contrastive Learning (CL) methodologies, this research aims to develop CL methodologies to translate implicit knowledge in VFM into change representations, thus eliminating the need for explicit supervision. To this end, we introduce a Semantic-to-Change (S2C) learning framework for UCD in both homogeneous and multimodal RS images. Differently from existing CL methodologies that typically focus on learning multi-temporal similarities, we introduce a novel triplet learning strategy that explicitly models temporal differences, which are crucial to the CD task. Furthermore, random spatial and spectral perturbations are introduced during the training to enhance robustness to temporal noise. In addition, a grid sparsity regularization is defined to suppress insignificant changes, and an IoU-matching algorithm is developed to refine the CD results. Experiments on four benchmark CD datasets demonstrate that the proposed S2C learning framework achieves significant improvements in accuracy, surpassing current state-of-the-art by over 31\%, 9\%, 23\%, and 15\%, respectively. It also demonstrates robustness and sample efficiency, suitable for training and adaptation of various Visual Foundation Models (VFMs) or backbone neural networks. The relevant code will be available at: github.com/DingLei14/S2C.
A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Feb 05, 2025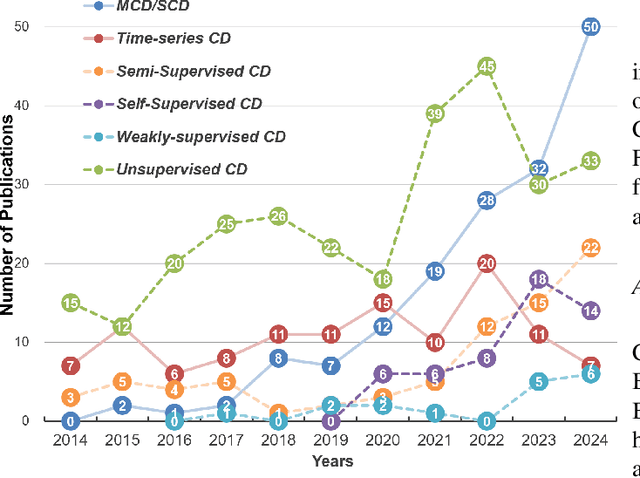
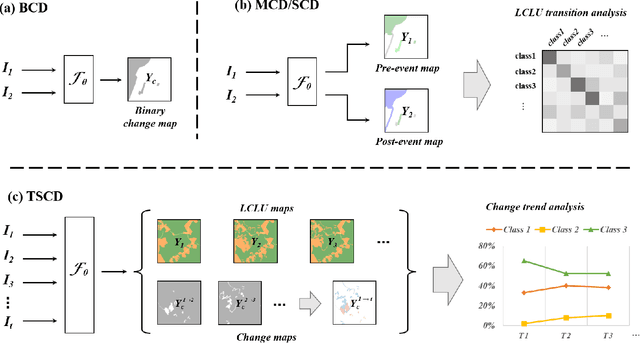
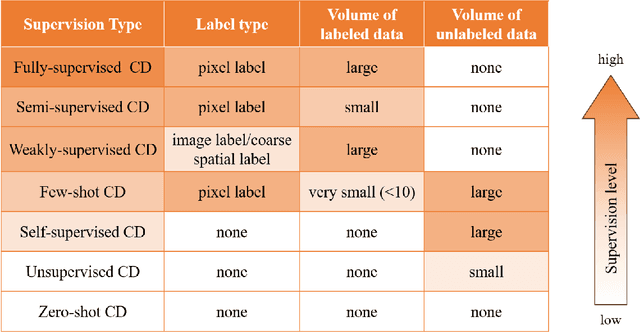
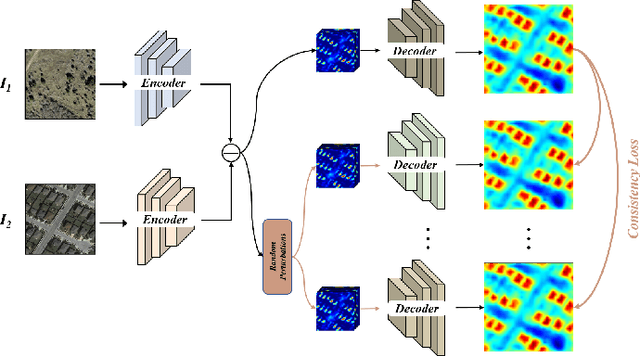
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the 'data-hungry' issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.
Right this way: Can VLMs Guide Us to See More to Answer Questions?
Nov 01, 2024



In question-answering scenarios, humans can assess whether the available information is sufficient and seek additional information if necessary, rather than providing a forced answer. In contrast, Vision Language Models (VLMs) typically generate direct, one-shot responses without evaluating the sufficiency of the information. To investigate this gap, we identify a critical and challenging task in the Visual Question Answering (VQA) scenario: can VLMs indicate how to adjust an image when the visual information is insufficient to answer a question? This capability is especially valuable for assisting visually impaired individuals who often need guidance to capture images correctly. To evaluate this capability of current VLMs, we introduce a human-labeled dataset as a benchmark for this task. Additionally, we present an automated framework that generates synthetic training data by simulating ``where to know'' scenarios. Our empirical results show significant performance improvements in mainstream VLMs when fine-tuned with this synthetic data. This study demonstrates the potential to narrow the gap between information assessment and acquisition in VLMs, bringing their performance closer to humans.
Dual-Model Distillation for Efficient Action Classification with Hybrid Edge-Cloud Solution
Oct 16, 2024As Artificial Intelligence models, such as Large Video-Language models (VLMs), grow in size, their deployment in real-world applications becomes increasingly challenging due to hardware limitations and computational costs. To address this, we design a hybrid edge-cloud solution that leverages the efficiency of smaller models for local processing while deferring to larger, more accurate cloud-based models when necessary. Specifically, we propose a novel unsupervised data generation method, Dual-Model Distillation (DMD), to train a lightweight switcher model that can predict when the edge model's output is uncertain and selectively offload inference to the large model in the cloud. Experimental results on the action classification task show that our framework not only requires less computational overhead, but also improves accuracy compared to using a large model alone. Our framework provides a scalable and adaptable solution for action classification in resource-constrained environments, with potential applications beyond healthcare. Noteworthy, while DMD-generated data is used for optimizing performance and resource usage in our pipeline, we expect the concept of DMD to further support future research on knowledge alignment across multiple models.
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
Jul 09, 2024
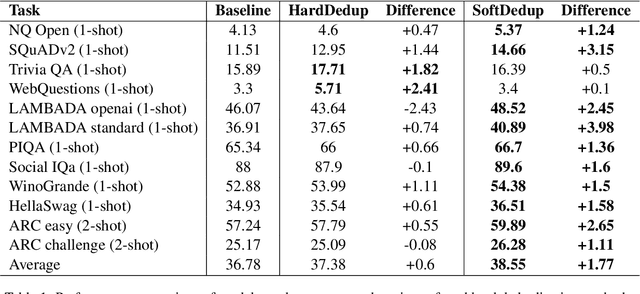
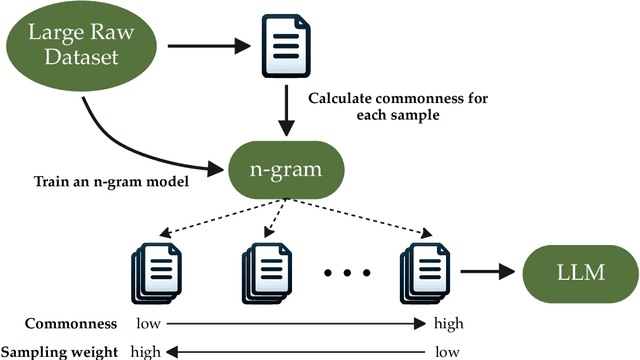
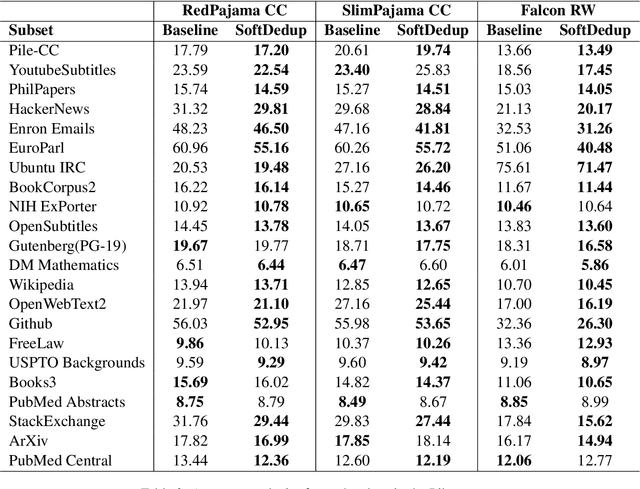
The effectiveness of large language models (LLMs) is often hindered by duplicated data in their extensive pre-training datasets. Current approaches primarily focus on detecting and removing duplicates, which risks the loss of valuable information and neglects the varying degrees of duplication. To address this, we propose a soft deduplication method that maintains dataset integrity while selectively reducing the sampling weight of data with high commonness. Central to our approach is the concept of "data commonness", a metric we introduce to quantify the degree of duplication by measuring the occurrence probabilities of samples using an n-gram model. Empirical analysis shows that this method significantly improves training efficiency, achieving comparable perplexity scores with at least a 26% reduction in required training steps. Additionally, it enhances average few-shot downstream accuracy by 1.77% when trained for an equivalent duration. Importantly, this approach consistently improves performance, even on rigorously deduplicated datasets, indicating its potential to complement existing methods and become a standard pre-training process for LLMs.
Read Anywhere Pointed: Layout-aware GUI Screen Reading with Tree-of-Lens Grounding
Jun 27, 2024



Graphical User Interfaces (GUIs) are central to our interaction with digital devices. Recently, growing efforts have been made to build models for various GUI understanding tasks. However, these efforts largely overlook an important GUI-referring task: screen reading based on user-indicated points, which we name the Screen Point-and-Read (SPR) task. This task is predominantly handled by rigid accessible screen reading tools, in great need of new models driven by advancements in Multimodal Large Language Models (MLLMs). In this paper, we propose a Tree-of-Lens (ToL) agent, utilizing a novel ToL grounding mechanism, to address the SPR task. Based on the input point coordinate and the corresponding GUI screenshot, our ToL agent constructs a Hierarchical Layout Tree. Based on the tree, our ToL agent not only comprehends the content of the indicated area but also articulates the layout and spatial relationships between elements. Such layout information is crucial for accurately interpreting information on the screen, distinguishing our ToL agent from other screen reading tools. We also thoroughly evaluate the ToL agent against other baselines on a newly proposed SPR benchmark, which includes GUIs from mobile, web, and operating systems. Last but not least, we test the ToL agent on mobile GUI navigation tasks, demonstrating its utility in identifying incorrect actions along the path of agent execution trajectories. Code and data: screen-point-and-read.github.io