 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Large Language Models for Dynamic Constraints through Human-in-the-Loop Discriminators
Oct 19, 2024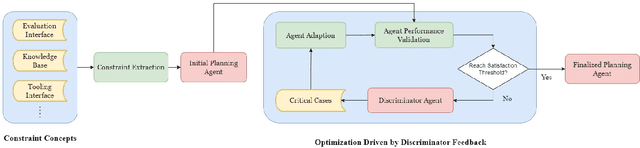


Large Language Models (LLMs) have recently demonstrated impressive capabilities across various real-world applications. However, due to the current text-in-text-out paradigm, it remains challenging for LLMs to handle dynamic and complex application constraints, let alone devise general solutions that meet predefined system goals. Current common practices like model finetuning and reflection-based reasoning often address these issues case-by-case, limiting their generalizability. To address this issue, we propose a flexible framework that enables LLMs to interact with system interfaces, summarize constraint concepts, and continually optimize performance metrics by collaborating with human experts. As a case in point, we initialized a travel planner agent by establishing constraints from evaluation interfaces. Then, we employed both LLM-based and human discriminators to identify critical cases and continuously improve agent performance until the desired outcomes were achieved. After just one iteration, our framework achieved a $7.78\%$ pass rate with the human discriminator (a $40.2\%$ improvement over baseline) and a $6.11\%$ pass rate with the LLM-based discriminator. Given the adaptability of our proposal, we believe this framework can be applied to a wide range of constraint-based applications and lay a solid foundation for model finetuning with performance-sensitive data samples.
Dual-Model Distillation for Efficient Action Classification with Hybrid Edge-Cloud Solution
Oct 16, 2024As Artificial Intelligence models, such as Large Video-Language models (VLMs), grow in size, their deployment in real-world applications becomes increasingly challenging due to hardware limitations and computational costs. To address this, we design a hybrid edge-cloud solution that leverages the efficiency of smaller models for local processing while deferring to larger, more accurate cloud-based models when necessary. Specifically, we propose a novel unsupervised data generation method, Dual-Model Distillation (DMD), to train a lightweight switcher model that can predict when the edge model's output is uncertain and selectively offload inference to the large model in the cloud. Experimental results on the action classification task show that our framework not only requires less computational overhead, but also improves accuracy compared to using a large model alone. Our framework provides a scalable and adaptable solution for action classification in resource-constrained environments, with potential applications beyond healthcare. Noteworthy, while DMD-generated data is used for optimizing performance and resource usage in our pipeline, we expect the concept of DMD to further support future research on knowledge alignment across multiple models.
Smart Language Agents in Real-World Planning
Jul 29, 2024

Comprehensive planning agents have been a long term goal in the field of artificial intelligence. Recent innovations in Natural Language Processing have yielded success through the advent of Large Language Models (LLMs). We seek to improve the travel-planning capability of such LLMs by extending upon the work of the previous paper TravelPlanner. Our objective is to explore a new method of using LLMs to improve the travel planning experience. We focus specifically on the "sole-planning" mode of travel planning; that is, the agent is given necessary reference information, and its goal is to create a comprehensive plan from the reference information. While this does not simulate the real-world we feel that an optimization of the sole-planning capability of a travel planning agent will still be able to enhance the overall user experience. We propose a semi-automated prompt generation framework which combines the LLM-automated prompt and "human-in-the-loop" to iteratively refine the prompt to improve the LLM performance. Our result shows that LLM automated prompt has its limitations and "human-in-the-loop" greatly improves the performance by $139\%$ with one single iteration.