 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Model Distillation for Efficient Action Classification with Hybrid Edge-Cloud Solution
Oct 16, 2024As Artificial Intelligence models, such as Large Video-Language models (VLMs), grow in size, their deployment in real-world applications becomes increasingly challenging due to hardware limitations and computational costs. To address this, we design a hybrid edge-cloud solution that leverages the efficiency of smaller models for local processing while deferring to larger, more accurate cloud-based models when necessary. Specifically, we propose a novel unsupervised data generation method, Dual-Model Distillation (DMD), to train a lightweight switcher model that can predict when the edge model's output is uncertain and selectively offload inference to the large model in the cloud. Experimental results on the action classification task show that our framework not only requires less computational overhead, but also improves accuracy compared to using a large model alone. Our framework provides a scalable and adaptable solution for action classification in resource-constrained environments, with potential applications beyond healthcare. Noteworthy, while DMD-generated data is used for optimizing performance and resource usage in our pipeline, we expect the concept of DMD to further support future research on knowledge alignment across multiple models.
A Review of Vision-Language Models and their Performance on the Hateful Memes Challenge
May 09, 2023
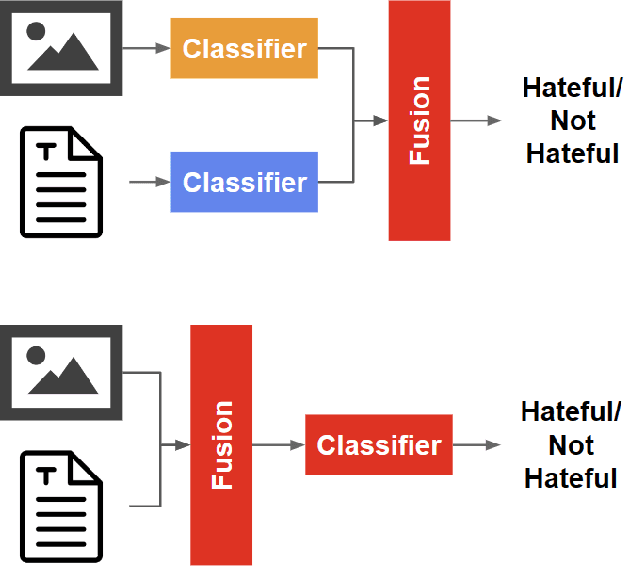
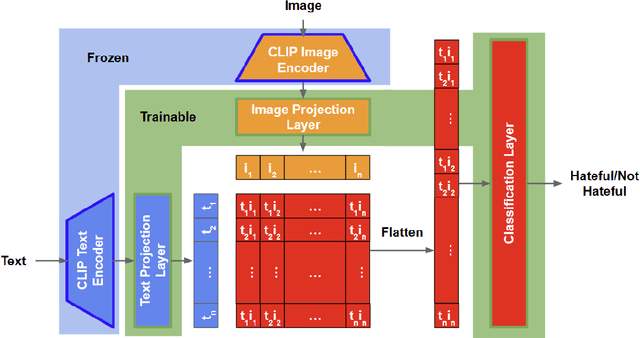
Moderation of social media content is currently a highly manual task, yet there is too much content posted daily to do so effectively. With the advent of a number of multimodal models, there is the potential to reduce the amount of manual labor for this task. In this work, we aim to explore different models and determine what is most effective for the Hateful Memes Challenge, a challenge by Meta designed to further machine learning research in content moderation. Specifically, we explore the differences between early fusion and late fusion models in classifying multimodal memes containing text and images. We first implement a baseline using unimodal models for text and images separately using BERT and ResNet-152, respectively. The outputs from these unimodal models were then concatenated together to create a late fusion model. In terms of early fusion models, we implement ConcatBERT, VisualBERT, ViLT, CLIP, and BridgeTower. It was found that late fusion performed significantly worse than early fusion models, with the best performing model being CLIP which achieved an AUROC of 70.06. The code for this work is available at https://github.com/bzhao18/CS-7643-Project.
Athletic Mobile Manipulator System for Robotic Wheelchair Tennis
Oct 05, 2022
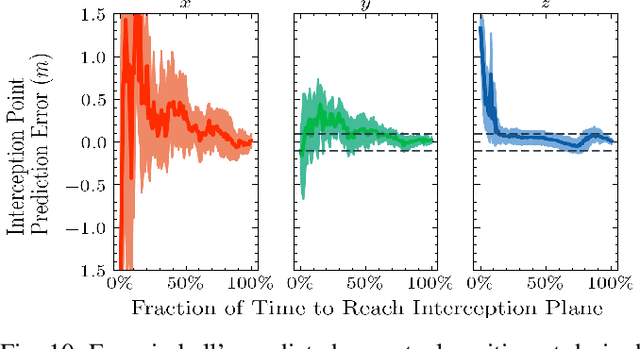

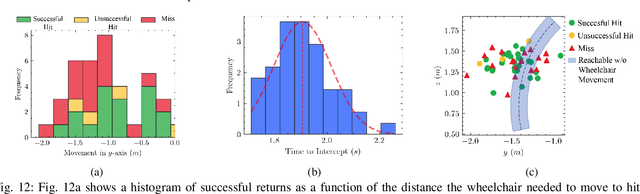
Athletics are a quintessential and universal expression of humanity. From French monks who in the 12th century invented jeu de paume, the precursor to modern lawn tennis, back to the K'iche' people who played the Maya Ballgame as a form of religious expression over three thousand years ago, humans have sought to train their minds and bodies to excel in sporting contests. Advances in robotics are opening up the possibility of robots in sports. Yet, key challenges remain, as most prior works in robotics for sports are limited to pristine sensing environments, do not require significant force generation, or are on miniaturized scales unsuited for joint human-robot play. In this paper, we propose the first open-source, autonomous robot for playing regulation wheelchair tennis. We demonstrate the performance of our full-stack system in executing ground strokes and evaluate each of the system's hardware and software components. The goal of this paper is to (1) inspire more research in human-scale robot athletics and (2) establish the first baseline towards developing a robot in future work that can serve as a teammate for mixed, human-robot doubles play. Our paper contributes to the science of systems design and poses a set of key challenges for the robotics community to address in striving towards a vision of human-robot collaboration in sports.