 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGriDiT: Factorized Grid-Based Diffusion for Efficient Long Image Sequence Generation
Dec 24, 2025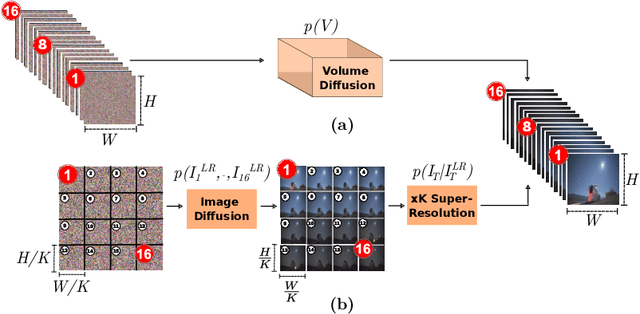
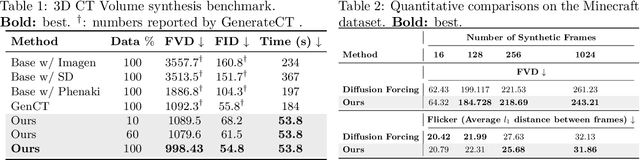
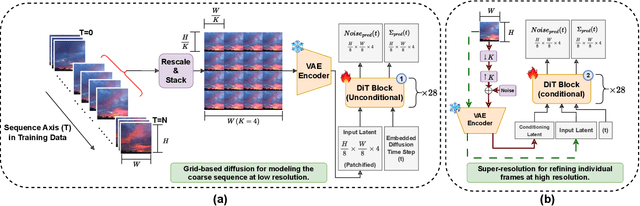
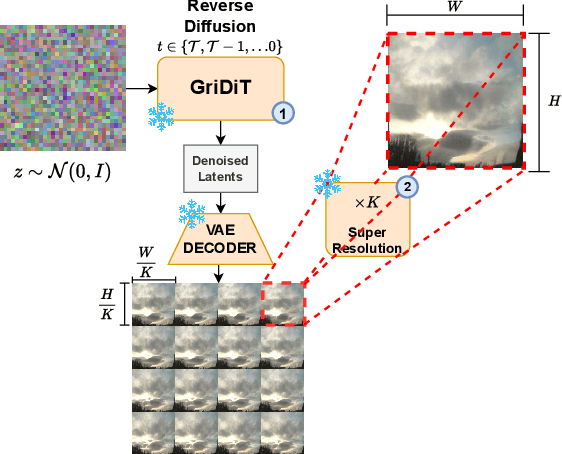
Modern deep learning methods typically treat image sequences as large tensors of sequentially stacked frames. However, is this straightforward representation ideal given the current state-of-the-art (SoTA)? In this work, we address this question in the context of generative models and aim to devise a more effective way of modeling image sequence data. Observing the inefficiencies and bottlenecks of current SoTA image sequence generation methods, we showcase that rather than working with large tensors, we can improve the generation process by factorizing it into first generating the coarse sequence at low resolution and then refining the individual frames at high resolution. We train a generative model solely on grid images comprising subsampled frames. Yet, we learn to generate image sequences, using the strong self-attention mechanism of the Diffusion Transformer (DiT) to capture correlations between frames. In effect, our formulation extends a 2D image generator to operate as a low-resolution 3D image-sequence generator without introducing any architectural modifications. Subsequently, we super-resolve each frame individually to add the sequence-independent high-resolution details. This approach offers several advantages and can overcome key limitations of the SoTA in this domain. Compared to existing image sequence generation models, our method achieves superior synthesis quality and improved coherence across sequences. It also delivers high-fidelity generation of arbitrary-length sequences and increased efficiency in inference time and training data usage. Furthermore, our straightforward formulation enables our method to generalize effectively across diverse data domains, which typically require additional priors and supervision to model in a generative context. Our method consistently outperforms SoTA in quality and inference speed (at least twice-as-fast) across datasets.
Weakest Link in the Chain: Security Vulnerabilities in Advanced Reasoning Models
Jun 16, 2025The introduction of advanced reasoning capabilities have improved the problem-solving performance of large language models, particularly on math and coding benchmarks. However, it remains unclear whether these reasoning models are more or less vulnerable to adversarial prompt attacks than their non-reasoning counterparts. In this work, we present a systematic evaluation of weaknesses in advanced reasoning models compared to similar non-reasoning models across a diverse set of prompt-based attack categories. Using experimental data, we find that on average the reasoning-augmented models are \emph{slightly more robust} than non-reasoning models (42.51\% vs 45.53\% attack success rate, lower is better). However, this overall trend masks significant category-specific differences: for certain attack types the reasoning models are substantially \emph{more vulnerable} (e.g., up to 32 percentage points worse on a tree-of-attacks prompt), while for others they are markedly \emph{more robust} (e.g., 29.8 points better on cross-site scripting injection). Our findings highlight the nuanced security implications of advanced reasoning in language models and emphasize the importance of stress-testing safety across diverse adversarial techniques.
Importing Phantoms: Measuring LLM Package Hallucination Vulnerabilities
Jan 31, 2025



Large Language Models (LLMs) have become an essential tool in the programmer's toolkit, but their tendency to hallucinate code can be used by malicious actors to introduce vulnerabilities to broad swathes of the software supply chain. In this work, we analyze package hallucination behaviour in LLMs across popular programming languages examining both existing package references and fictional dependencies. By analyzing this package hallucination behaviour we find potential attacks and suggest defensive strategies to defend against these attacks. We discover that package hallucination rate is predicated not only on model choice, but also programming language, model size, and specificity of the coding task request. The Pareto optimality boundary between code generation performance and package hallucination is sparsely populated, suggesting that coding models are not being optimized for secure code. Additionally, we find an inverse correlation between package hallucination rate and the HumanEval coding benchmark, offering a heuristic for evaluating the propensity of a model to hallucinate packages. Our metrics, findings and analyses provide a base for future models, securing AI-assisted software development workflows against package supply chain attacks.
Multi-Conditioned Denoising Diffusion Probabilistic Model (mDDPM) for Medical Image Synthesis
Sep 07, 2024



Medical imaging applications are highly specialized in terms of human anatomy, pathology, and imaging domains. Therefore, annotated training datasets for training deep learning applications in medical imaging not only need to be highly accurate but also diverse and large enough to encompass almost all plausible examples with respect to those specifications. We argue that achieving this goal can be facilitated through a controlled generation framework for synthetic images with annotations, requiring multiple conditional specifications as input to provide control. We employ a Denoising Diffusion Probabilistic Model (DDPM) to train a large-scale generative model in the lung CT domain and expand upon a classifier-free sampling strategy to showcase one such generation framework. We show that our approach can produce annotated lung CT images that can faithfully represent anatomy, convincingly fooling experts into perceiving them as real. Our experiments demonstrate that controlled generative frameworks of this nature can surpass nearly every state-of-the-art image generative model in achieving anatomical consistency in generated medical images when trained on comparable large medical datasets.
The Effect of Robot Skill Level and Communication in Rapid, Proximate Human-Robot Collaboration
Apr 07, 2023As high-speed, agile robots become more commonplace, these robots will have the potential to better aid and collaborate with humans. However, due to the increased agility and functionality of these robots, close collaboration with humans can create safety concerns that alter team dynamics and degrade task performance. In this work, we aim to enable the deployment of safe and trustworthy agile robots that operate in proximity with humans. We do so by 1) Proposing a novel human-robot doubles table tennis scenario to serve as a testbed for studying agile, proximate human-robot collaboration and 2) Conducting a user-study to understand how attributes of the robot (e.g., robot competency or capacity to communicate) impact team dynamics, perceived safety, and perceived trust, and how these latent factors affect human-robot collaboration (HRC) performance. We find that robot competency significantly increases perceived trust ($p<.001$), extending skill-to-trust assessments in prior studies to agile, proximate HRC. Furthermore, interestingly, we find that when the robot vocalizes its intention to perform a task, it results in a significant decrease in team performance ($p=.037$) and perceived safety of the system ($p=.009$).
Improving CT Image Segmentation Accuracy Using StyleGAN Driven Data Augmentation
Feb 07, 2023Medical Image Segmentation is a useful application for medical image analysis including detecting diseases and abnormalities in imaging modalities such as MRI, CT etc. Deep learning has proven to be promising for this task but usually has a low accuracy because of the lack of appropriate publicly available annotated or segmented medical datasets. In addition, the datasets that are available may have a different texture because of different dosage values or scanner properties than the images that need to be segmented. This paper presents a StyleGAN-driven approach for segmenting publicly available large medical datasets by using readily available extremely small annotated datasets in similar modalities. The approach involves augmenting the small segmented dataset and eliminating texture differences between the two datasets. The dataset is augmented by being passed through six different StyleGANs that are trained on six different style images taken from the large non-annotated dataset we want to segment. Specifically, style transfer is used to augment the training dataset. The annotations of the training dataset are hence combined with the textures of the non-annotated dataset to generate new anatomically sound images. The augmented dataset is then used to train a U-Net segmentation network which displays a significant improvement in the segmentation accuracy in segmenting the large non-annotated dataset.
Utilizing Human Feedback for Primitive Optimization in Wheelchair Tennis
Dec 29, 2022Agile robotics presents a difficult challenge with robots moving at high speeds requiring precise and low-latency sensing and control. Creating agile motion that accomplishes the task at hand while being safe to execute is a key requirement for agile robots to gain human trust. This requires designing new approaches that are flexible and maintain knowledge over world constraints. In this paper, we consider the problem of building a flexible and adaptive controller for a challenging agile mobile manipulation task of hitting ground strokes on a wheelchair tennis robot. We propose and evaluate an extension to work done on learning striking behaviors using a probabilistic movement primitive (ProMP) framework by (1) demonstrating the safe execution of learned primitives on an agile mobile manipulator setup, and (2) proposing an online primitive refinement procedure that utilizes evaluative feedback from humans on the executed trajectories.
Athletic Mobile Manipulator System for Robotic Wheelchair Tennis
Oct 05, 2022
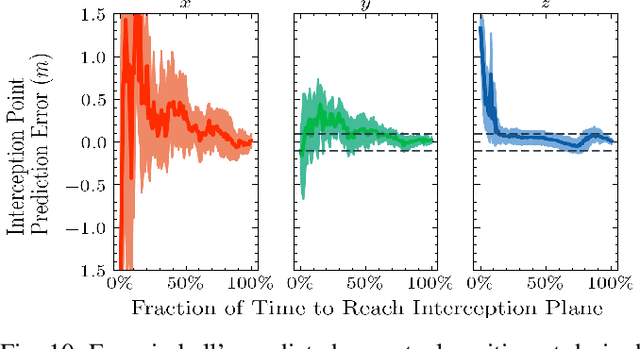

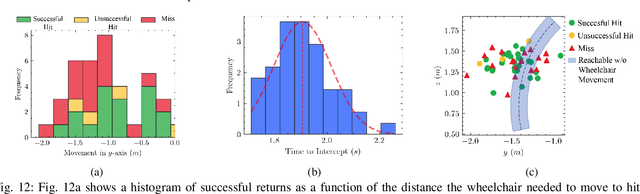
Athletics are a quintessential and universal expression of humanity. From French monks who in the 12th century invented jeu de paume, the precursor to modern lawn tennis, back to the K'iche' people who played the Maya Ballgame as a form of religious expression over three thousand years ago, humans have sought to train their minds and bodies to excel in sporting contests. Advances in robotics are opening up the possibility of robots in sports. Yet, key challenges remain, as most prior works in robotics for sports are limited to pristine sensing environments, do not require significant force generation, or are on miniaturized scales unsuited for joint human-robot play. In this paper, we propose the first open-source, autonomous robot for playing regulation wheelchair tennis. We demonstrate the performance of our full-stack system in executing ground strokes and evaluate each of the system's hardware and software components. The goal of this paper is to (1) inspire more research in human-scale robot athletics and (2) establish the first baseline towards developing a robot in future work that can serve as a teammate for mixed, human-robot doubles play. Our paper contributes to the science of systems design and poses a set of key challenges for the robotics community to address in striving towards a vision of human-robot collaboration in sports.
Image Synthesis for Data Augmentation in Medical CT using Deep Reinforcement Learning
Mar 22, 2021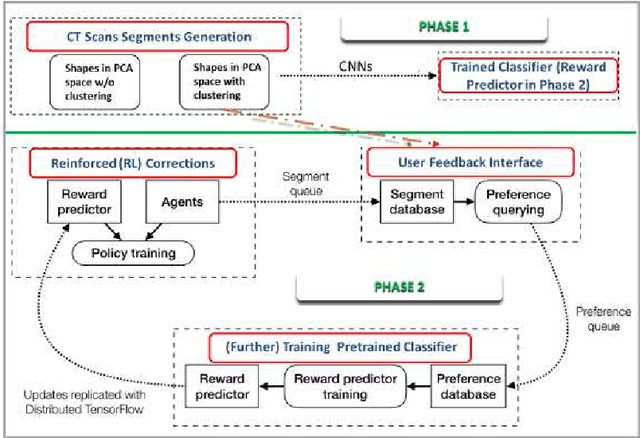
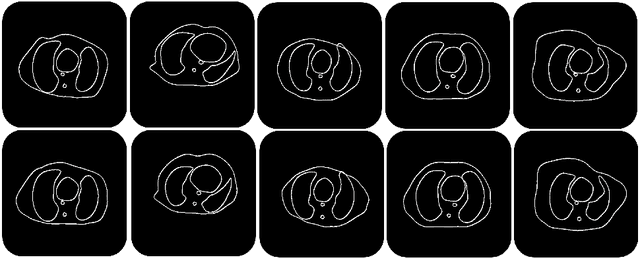
Deep learning has shown great promise for CT image reconstruction, in particular to enable low dose imaging and integrated diagnostics. These merits, however, stand at great odds with the low availability of diverse image data which are needed to train these neural networks. We propose to overcome this bottleneck via a deep reinforcement learning (DRL) approach that is integrated with a style-transfer (ST) methodology, where the DRL generates the anatomical shapes and the ST synthesizes the texture detail. We show that our method bears high promise for generating novel and anatomically accurate high resolution CT images at large and diverse quantities. Our approach is specifically designed to work with even small image datasets which is desirable given the often low amount of image data many researchers have available to them.
Noise Entangled GAN For Low-Dose CT Simulation
Feb 18, 2021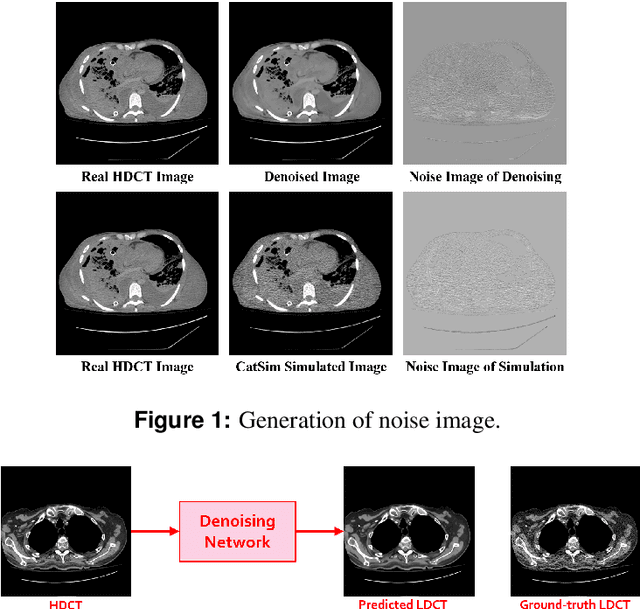
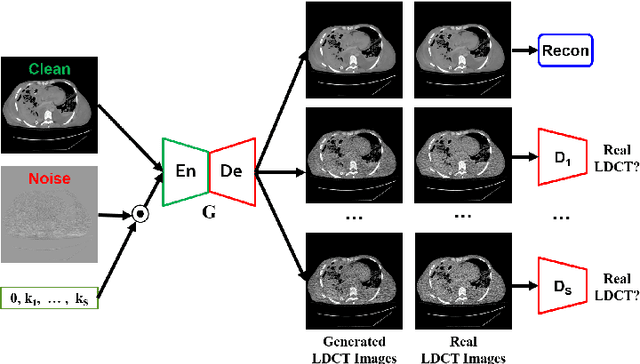
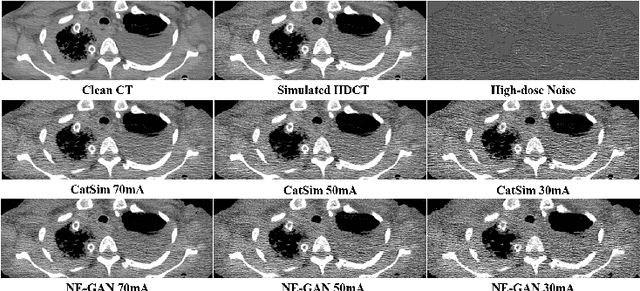
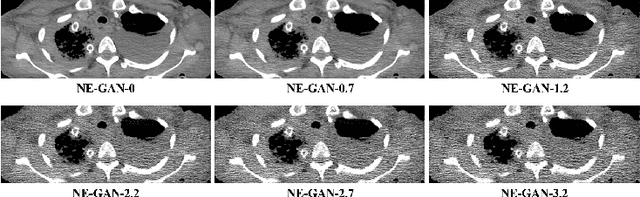
We propose a Noise Entangled GAN (NE-GAN) for simulating low-dose computed tomography (CT) images from a higher dose CT image. First, we present two schemes to generate a clean CT image and a noise image from the high-dose CT image. Then, given these generated images, an NE-GAN is proposed to simulate different levels of low-dose CT images, where the level of generated noise can be continuously controlled by a noise factor. NE-GAN consists of a generator and a set of discriminators, and the number of discriminators is determined by the number of noise levels during training. Compared with the traditional methods based on the projection data that are usually unavailable in real applications, NE-GAN can directly learn from the real and/or simulated CT images and may create low-dose CT images quickly without the need of raw data or other proprietary CT scanner information. The experimental results show that the proposed method has the potential to simulate realistic low-dose CT images.