 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards In-Vehicle Multi-Task Facial Attribute Recognition: Investigating Synthetic Data and Vision Foundation Models
Mar 10, 2024
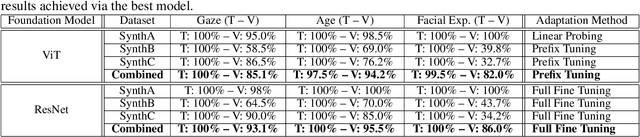


In the burgeoning field of intelligent transportation systems, enhancing vehicle-driver interaction through facial attribute recognition, such as facial expression, eye gaze, age, etc., is of paramount importance for safety, personalization, and overall user experience. However, the scarcity of comprehensive large-scale, real-world datasets poses a significant challenge for training robust multi-task models. Existing literature often overlooks the potential of synthetic datasets and the comparative efficacy of state-of-the-art vision foundation models in such constrained settings. This paper addresses these gaps by investigating the utility of synthetic datasets for training complex multi-task models that recognize facial attributes of passengers of a vehicle, such as gaze plane, age, and facial expression. Utilizing transfer learning techniques with both pre-trained Vision Transformer (ViT) and Residual Network (ResNet) models, we explore various training and adaptation methods to optimize performance, particularly when data availability is limited. We provide extensive post-evaluation analysis, investigating the effects of synthetic data distributions on model performance in in-distribution data and out-of-distribution inference. Our study unveils counter-intuitive findings, notably the superior performance of ResNet over ViTs in our specific multi-task context, which is attributed to the mismatch in model complexity relative to task complexity. Our results highlight the challenges and opportunities for enhancing the use of synthetic data and vision foundation models in practical applications.
Utilizing Human Feedback for Primitive Optimization in Wheelchair Tennis
Dec 29, 2022Agile robotics presents a difficult challenge with robots moving at high speeds requiring precise and low-latency sensing and control. Creating agile motion that accomplishes the task at hand while being safe to execute is a key requirement for agile robots to gain human trust. This requires designing new approaches that are flexible and maintain knowledge over world constraints. In this paper, we consider the problem of building a flexible and adaptive controller for a challenging agile mobile manipulation task of hitting ground strokes on a wheelchair tennis robot. We propose and evaluate an extension to work done on learning striking behaviors using a probabilistic movement primitive (ProMP) framework by (1) demonstrating the safe execution of learned primitives on an agile mobile manipulator setup, and (2) proposing an online primitive refinement procedure that utilizes evaluative feedback from humans on the executed trajectories.
Athletic Mobile Manipulator System for Robotic Wheelchair Tennis
Oct 05, 2022
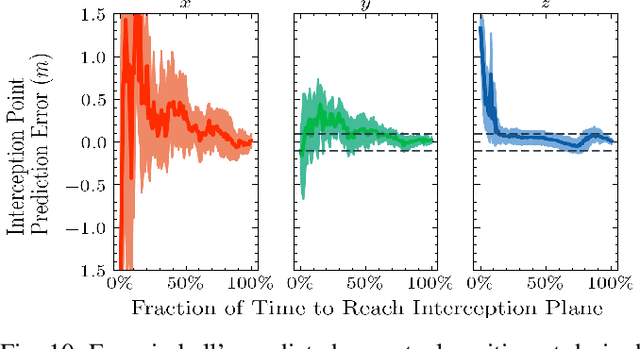

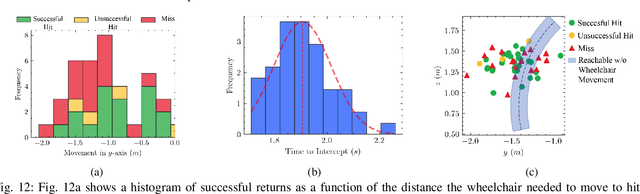
Athletics are a quintessential and universal expression of humanity. From French monks who in the 12th century invented jeu de paume, the precursor to modern lawn tennis, back to the K'iche' people who played the Maya Ballgame as a form of religious expression over three thousand years ago, humans have sought to train their minds and bodies to excel in sporting contests. Advances in robotics are opening up the possibility of robots in sports. Yet, key challenges remain, as most prior works in robotics for sports are limited to pristine sensing environments, do not require significant force generation, or are on miniaturized scales unsuited for joint human-robot play. In this paper, we propose the first open-source, autonomous robot for playing regulation wheelchair tennis. We demonstrate the performance of our full-stack system in executing ground strokes and evaluate each of the system's hardware and software components. The goal of this paper is to (1) inspire more research in human-scale robot athletics and (2) establish the first baseline towards developing a robot in future work that can serve as a teammate for mixed, human-robot doubles play. Our paper contributes to the science of systems design and poses a set of key challenges for the robotics community to address in striving towards a vision of human-robot collaboration in sports.
Multi-UAV Planning for Cooperative Wildfire Coverage and Tracking with Quality-of-Service Guarantees
Jun 21, 2022In recent years, teams of robot and Unmanned Aerial Vehicles (UAVs) have been commissioned by researchers to enable accurate, online wildfire coverage and tracking. While the majority of prior work focuses on the coordination and control of such multi-robot systems, to date, these UAV teams have not been given the ability to reason about a fire's track (i.e., location and propagation dynamics) to provide performance guarantee over a time horizon. Motivated by the problem of aerial wildfire monitoring, we propose a predictive framework which enables cooperation in multi-UAV teams towards collaborative field coverage and fire tracking with probabilistic performance guarantee. Our approach enables UAVs to infer the latent fire propagation dynamics for time-extended coordination in safety-critical conditions. We derive a set of novel, analytical temporal, and tracking-error bounds to enable the UAV-team to distribute their limited resources and cover the entire fire area according to the case-specific estimated states and provide a probabilistic performance guarantee. Our results are not limited to the aerial wildfire monitoring case-study and are generally applicable to problems, such as search-and-rescue, target tracking and border patrol. We evaluate our approach in simulation and provide demonstrations of the proposed framework on a physical multi-robot testbed to account for real robot dynamics and restrictions. Our quantitative evaluations validate the performance of our method accumulating 7.5x and 9.0x smaller tracking-error than state-of-the-art model-based and reinforcement learning benchmarks, respectively.
Iterated Reasoning with Mutual Information in Cooperative and Byzantine Decentralized Teaming
Jan 20, 2022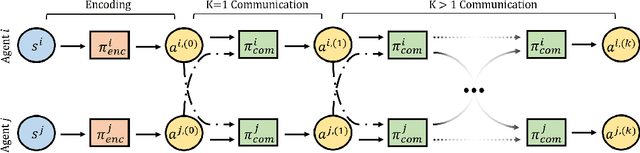



Information sharing is key in building team cognition and enables coordination and cooperation. High-performing human teams also benefit from acting strategically with hierarchical levels of iterated communication and rationalizability, meaning a human agent can reason about the actions of their teammates in their decision-making. Yet, the majority of prior work in Multi-Agent Reinforcement Learning (MARL) does not support iterated rationalizability and only encourage inter-agent communication, resulting in a suboptimal equilibrium cooperation strategy. In this work, we show that reformulating an agent's policy to be conditional on the policies of its neighboring teammates inherently maximizes Mutual Information (MI) lower-bound when optimizing under Policy Gradient (PG). Building on the idea of decision-making under bounded rationality and cognitive hierarchy theory, we show that our modified PG approach not only maximizes local agent rewards but also implicitly reasons about MI between agents without the need for any explicit ad-hoc regularization terms. Our approach, InfoPG, outperforms baselines in learning emergent collaborative behaviors and sets the state-of-the-art in decentralized cooperative MARL tasks. Our experiments validate the utility of InfoPG by achieving higher sample efficiency and significantly larger cumulative reward in several complex cooperative multi-agent domains.
FireCommander: An Interactive, Probabilistic Multi-agent Environment for Joint Perception-Action Tasks
Oct 31, 2020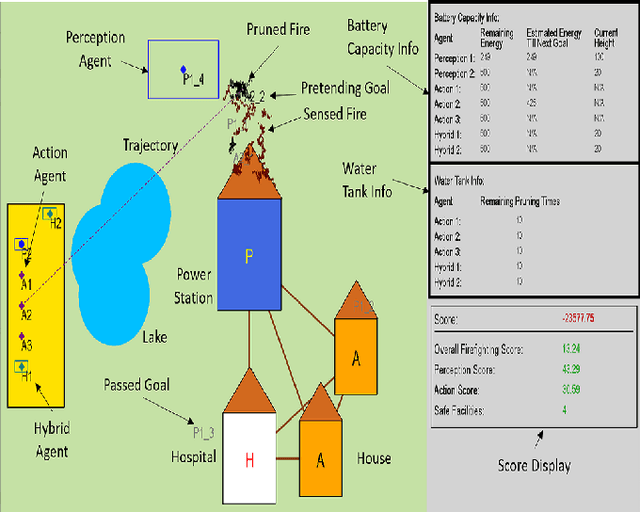

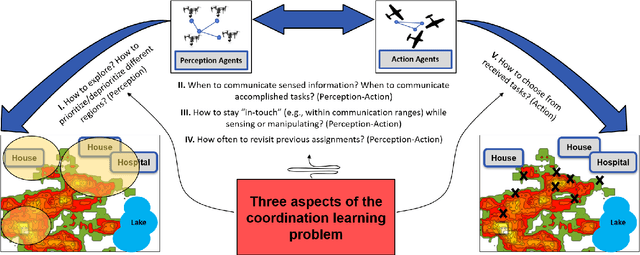

The purpose of this tutorial is to help individuals use the \underline{FireCommander} game environment for research applications. The FireCommander is an interactive, probabilistic joint perception-action reconnaissance environment in which a composite team of agents (e.g., robots) cooperate to fight dynamic, propagating firespots (e.g., targets). In FireCommander game, a team of agents must be tasked to optimally deal with a wildfire situation in an environment with propagating fire areas and some facilities such as houses, hospitals, power stations, etc. The team of agents can accomplish their mission by first sensing (e.g., estimating fire states), communicating the sensed fire-information among each other and then taking action to put the firespots out based on the sensed information (e.g., dropping water on estimated fire locations). The FireCommander environment can be useful for research topics spanning a wide range of applications from Reinforcement Learning (RL) and Learning from Demonstration (LfD), to Coordination, Psychology, Human-Robot Interaction (HRI) and Teaming. There are four important facets of the FireCommander environment that overall, create a non-trivial game: (1) Complex Objectives: Multi-objective Stochastic Environment, (2)Probabilistic Environment: Agents' actions result in probabilistic performance, (3) Hidden Targets: Partially Observable Environment and, (4) Uni-task Robots: Perception-only and Action-only agents. The FireCommander environment is first-of-its-kind in terms of including Perception-only and Action-only agents for coordination. It is a general multi-purpose game that can be useful in a variety of combinatorial optimization problems and stochastic games, such as applications of Reinforcement Learning (RL), Learning from Demonstration (LfD) and Inverse RL (iRL).
Coordinated Control of UAVs for Human-Centered Active Sensing of Wildfires
Jun 14, 2020
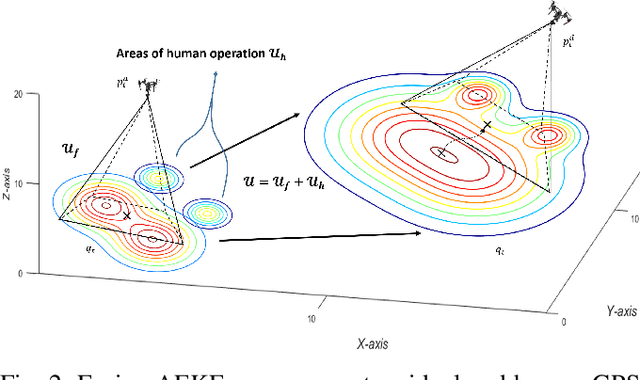
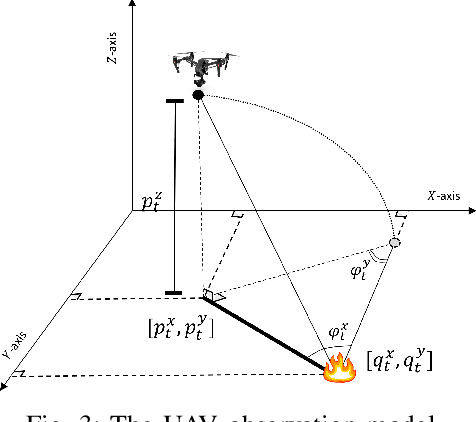
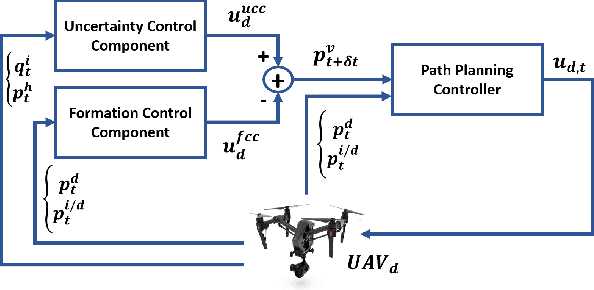
Fighting wildfires is a precarious task, imperiling the lives of engaging firefighters and those who reside in the fire's path. Firefighters need online and dynamic observation of the firefront to anticipate a wildfire's unknown characteristics, such as size, scale, and propagation velocity, and to plan accordingly. In this paper, we propose a distributed control framework to coordinate a team of unmanned aerial vehicles (UAVs) for a human-centered active sensing of wildfires. We develop a dual-criterion objective function based on Kalman uncertainty residual propagation and weighted multi-agent consensus protocol, which enables the UAVs to actively infer the wildfire dynamics and parameters, track and monitor the fire transition, and safely manage human firefighters on the ground using acquired information. We evaluate our approach relative to prior work, showing significant improvements by reducing the environment's cumulative uncertainty residual by more than $ 10^2 $ and $ 10^5 $ times in firefront coverage performance to support human-robot teaming for firefighting. We also demonstrate our method on physical robots in a mock firefighting exercise.
Safe Coordination of Human-Robot Firefighting Teams
Mar 16, 2019
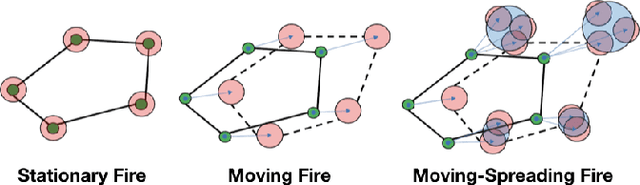
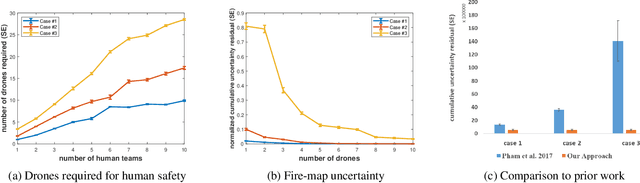
Wildfires are destructive and inflict massive, irreversible harm to victims' lives and natural resources. Researchers have proposed commissioning unmanned aerial vehicles (UAVs) to provide firefighters with real-time tracking information; yet, these UAVs are not able to reason about a fire's track, including current location, measurement, and uncertainty, as well as propagation. We propose a model-predictive, probabilistically safe distributed control algorithm for human-robot collaboration in wildfire fighting. The proposed algorithm overcomes the limitations of prior work by explicitly estimating the latent fire propagation dynamics to enable intelligent, time-extended coordination of the UAVs in support of on-the-ground human firefighters. We derive a novel, analytical bound that enables UAVs to distribute their resources and provides a probabilistic guarantee of the humans' safety while preserving the UAVs' ability to cover an entire fire.