 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseCol: Periodically Refreshed Column-Sparse Attention for Accelerating Diffusion Language Models
May 20, 2026Inference in diffusion large language models (dLLMs) is computationally expensive, as full self-attention must be repeatedly executed at each step of the denoising process without KV cache. Recent sparse attention methods for dLLMs mitigate this cost via block-sparse computation, which is applied only in later iterations when model performance is less sensitive to coarse-grained sparse approximation, but yields limited improvements in computational efficiency and acceleration. This motivates a finer-grained sparsification strategy that can be applied from earlier iterations and leverages reusable sparsity patterns, enabling further efficiency gains. In this work, we introduce PulseCol, a periodically refreshed column-sparse attention method for accelerating diffusion language models. PulseCol replaces coarse block-level sparsity with a finer-grained column-sparse structure, allowing important attention interactions to be retained more precisely while exposing greater sparsity. Built on this column-level formulation, PulseCol further identifies sparse patterns at the early denoising step and reuses them across subsequent iterations, refreshing them only at a small number of intermediate steps to track the evolution of sparse attention patterns during denoising. Experiments show that PulseCol achieves higher sparsity and greater practical speedup than prior sparse attention methods for dLLMs, while maintaining model quality. Enabled by optimized GPU kernels for column-sparse attention, PulseCol delivers up to 1.95$\times$ end-to-end speedup over FlashAttention across several context lengths.
Learning Molecular Chirality via Chiral Determinant Kernels
Feb 07, 2026Chirality is a fundamental molecular property that governs stereospecific behavior in chemistry and biology. Capturing chirality in machine learning models remains challenging due to the geometric complexity of stereochemical relationships and the limitations of traditional molecular representations that often lack explicit stereochemical encoding. Existing approaches to chiral molecular representation primarily focus on central chirality, relying on handcrafted stereochemical tags or limited 3D encodings, and thus fail to generalize to more complex forms such as axial chirality. In this work, we introduce ChiDeK (Chiral Determinant Kernels), a framework that systematically integrates stereogenic information into molecular representation learning. We propose the chiral determinant kernel to encode the SE(3)-invariant chirality matrix and employ cross-attention to integrate stereochemical information from local chiral centers into the global molecular representation. This design enables explicit modeling of chiral-related features within a unified architecture, capable of jointly encoding central and axial chirality. To support the evaluation of axial chirality, we construct a new benchmark for electronic circular dichroism (ECD) and optical rotation (OR) prediction. Across four tasks, including R/S configuration classification, enantiomer ranking, ECD spectrum prediction, and OR prediction, ChiDeK achieves substantial improvements over state-of-the-art baselines, most notably yielding over 7% higher accuracy on axially chiral tasks on average.
Reaction Prediction via Interaction Modeling of Symmetric Difference Shingle Sets
Nov 16, 2025


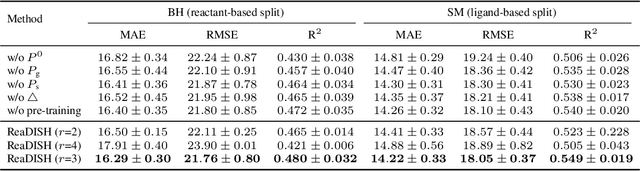
Chemical reaction prediction remains a fundamental challenge in organic chemistry, where existing machine learning models face two critical limitations: sensitivity to input permutations (molecule/atom orderings) and inadequate modeling of substructural interactions governing reactivity. These shortcomings lead to inconsistent predictions and poor generalization to real-world scenarios. To address these challenges, we propose ReaDISH, a novel reaction prediction model that learns permutation-invariant representations while incorporating interaction-aware features. It introduces two innovations: (1) symmetric difference shingle encoding, which extends the differential reaction fingerprint (DRFP) by representing shingles as continuous high-dimensional embeddings, capturing structural changes while eliminating order sensitivity; and (2) geometry-structure interaction attention, a mechanism that models intra- and inter-molecular interactions at the shingle level. Extensive experiments demonstrate that ReaDISH improves reaction prediction performance across diverse benchmarks. It shows enhanced robustness with an average improvement of 8.76% on R$^2$ under permutation perturbations.
RTMol: Rethinking Molecule-text Alignment in a Round-trip View
Nov 15, 2025



Aligning molecular sequence representations (e.g., SMILES notations) with textual descriptions is critical for applications spanning drug discovery, materials design, and automated chemical literature analysis. Existing methodologies typically treat molecular captioning (molecule-to-text) and text-based molecular design (text-to-molecule) as separate tasks, relying on supervised fine-tuning or contrastive learning pipelines. These approaches face three key limitations: (i) conventional metrics like BLEU prioritize linguistic fluency over chemical accuracy, (ii) training datasets frequently contain chemically ambiguous narratives with incomplete specifications, and (iii) independent optimization of generation directions leads to bidirectional inconsistency. To address these issues, we propose RTMol, a bidirectional alignment framework that unifies molecular captioning and text-to-SMILES generation through self-supervised round-trip learning. The framework introduces novel round-trip evaluation metrics and enables unsupervised training for molecular captioning without requiring paired molecule-text corpora. Experiments demonstrate that RTMol enhances bidirectional alignment performance by up to 47% across various LLMs, establishing an effective paradigm for joint molecule-text understanding and generation.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

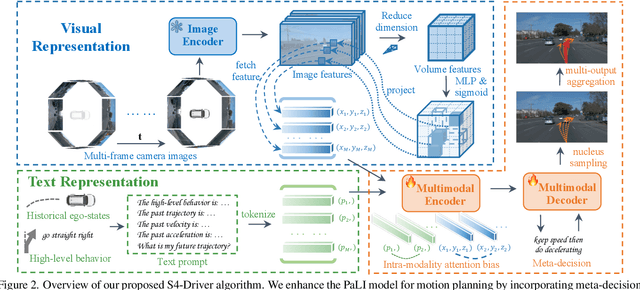

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Models
Mar 20, 2025Semantic Interpretability in Reinforcement Learning (RL) enables transparency, accountability, and safer deployment by making the agent's decisions understandable and verifiable. Achieving this, however, requires a feature space composed of human-understandable concepts, which traditionally rely on human specification and fail to generalize to unseen environments. In this work, we introduce Semantically Interpretable Reinforcement Learning with Vision-Language Models Empowered Automation (SILVA), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and interpretable tree-based models for policy optimization. SILVA first queries a VLM to identify relevant semantic features for an unseen environment, then extracts these features from the environment. Finally, it trains an Interpretable Control Tree via RL, mapping the extracted features to actions in a transparent and interpretable manner. To address the computational inefficiency of extracting features directly with VLMs, we develop a feature extraction pipeline that generates a dataset for training a lightweight convolutional network, which is subsequently used during RL. By leveraging VLMs to automate tree-based RL, SILVA removes the reliance on human annotation previously required by interpretable models while also overcoming the inability of VLMs alone to generate valid robot policies, enabling semantically interpretable reinforcement learning without human-in-the-loop.
ELEMENTAL: Interactive Learning from Demonstrations and Vision-Language Models for Reward Design in Robotics
Nov 27, 2024Reinforcement learning (RL) has demonstrated compelling performance in robotic tasks, but its success often hinges on the design of complex, ad hoc reward functions. Researchers have explored how Large Language Models (LLMs) could enable non-expert users to specify reward functions more easily. However, LLMs struggle to balance the importance of different features, generalize poorly to out-of-distribution robotic tasks, and cannot represent the problem properly with only text-based descriptions. To address these challenges, we propose ELEMENTAL (intEractive LEarning froM dEmoNstraTion And Language), a novel framework that combines natural language guidance with visual user demonstrations to align robot behavior with user intentions better. By incorporating visual inputs, ELEMENTAL overcomes the limitations of text-only task specifications, while leveraging inverse reinforcement learning (IRL) to balance feature weights and match the demonstrated behaviors optimally. ELEMENTAL also introduces an iterative feedback-loop through self-reflection to improve feature, reward, and policy learning. Our experiment results demonstrate that ELEMENTAL outperforms prior work by 42.3% on task success, and achieves 41.3% better generalization in out-of-distribution tasks, highlighting its robustness in LfD.
Faster Model Predictive Control via Self-Supervised Initialization Learning
Aug 06, 2024



Optimization for robot control tasks, spanning various methodologies, includes Model Predictive Control (MPC). However, the complexity of the system, such as non-convex and non-differentiable cost functions and prolonged planning horizons often drastically increases the computation time, limiting MPC's real-world applicability. Prior works in speeding up the optimization have limitations on solving convex problem and generalizing to hold out domains. To overcome this challenge, we develop a novel framework aiming at expediting optimization processes. In our framework, we combine offline self-supervised learning and online fine-tuning through reinforcement learning to improve the control performance and reduce optimization time. We demonstrate the effectiveness of our method on a novel, challenging Formula-1-track driving task, achieving 3.9\% higher performance in optimization time and 3.6\% higher performance in tracking accuracy on challenging holdout tracks.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
Learning Models of Adversarial Agent Behavior under Partial Observability
Jul 05, 2023The need for opponent modeling and tracking arises in several real-world scenarios, such as professional sports, video game design, and drug-trafficking interdiction. In this work, we present Graph based Adversarial Modeling with Mutal Information (GrAMMI) for modeling the behavior of an adversarial opponent agent. GrAMMI is a novel graph neural network (GNN) based approach that uses mutual information maximization as an auxiliary objective to predict the current and future states of an adversarial opponent with partial observability. To evaluate GrAMMI, we design two large-scale, pursuit-evasion domains inspired by real-world scenarios, where a team of heterogeneous agents is tasked with tracking and interdicting a single adversarial agent, and the adversarial agent must evade detection while achieving its own objectives. With the mutual information formulation, GrAMMI outperforms all baselines in both domains and achieves 31.68% higher log-likelihood on average for future adversarial state predictions across both domains.