 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025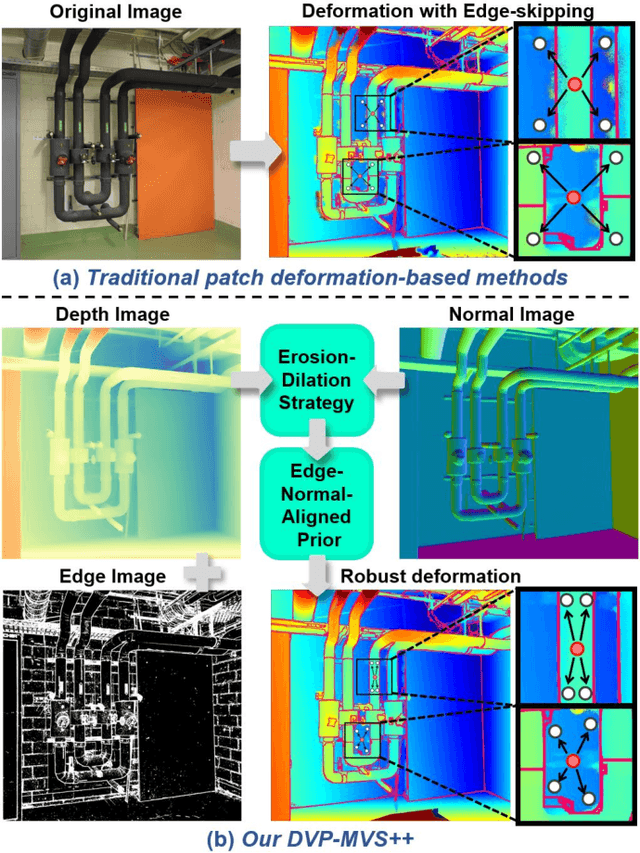
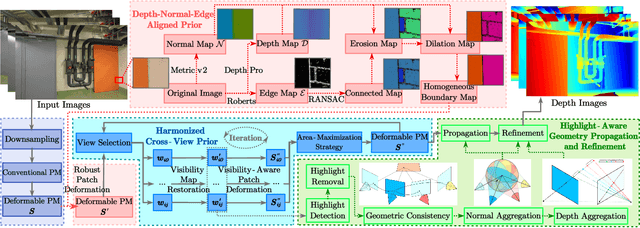
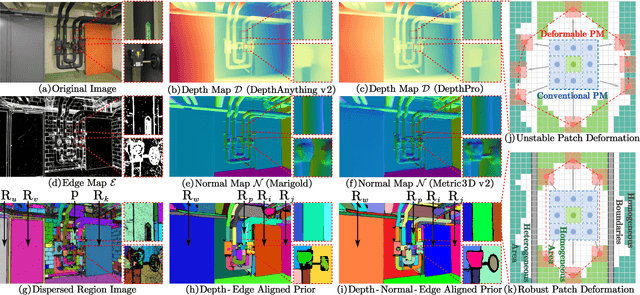
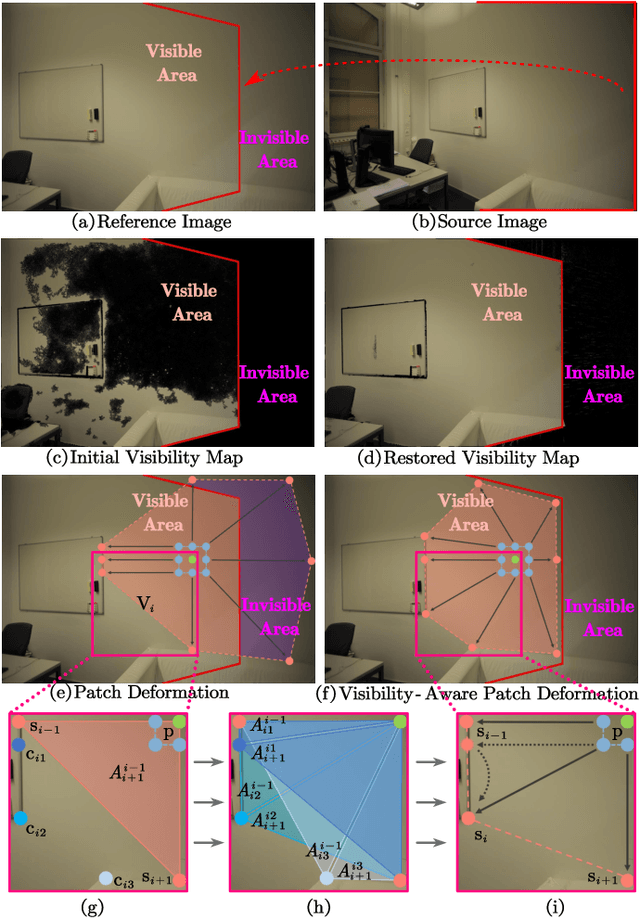
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
Fast-Powerformer: A Memory-Efficient Transformer for Accurate Mid-Term Wind Power Forecasting
Apr 15, 2025



Wind power forecasting (WPF), as a significant research topic within renewable energy, plays a crucial role in enhancing the security, stability, and economic operation of power grids. However, due to the high stochasticity of meteorological factors (e.g., wind speed) and significant fluctuations in wind power output, mid-term wind power forecasting faces a dual challenge of maintaining high accuracy and computational efficiency. To address these issues, this paper proposes an efficient and lightweight mid-term wind power forecasting model, termed Fast-Powerformer. The proposed model is built upon the Reformer architecture, incorporating structural enhancements such as a lightweight Long Short-Term Memory (LSTM) embedding module, an input transposition mechanism, and a Frequency Enhanced Channel Attention Mechanism (FECAM). These improvements enable the model to strengthen temporal feature extraction, optimize dependency modeling across variables, significantly reduce computational complexity, and enhance sensitivity to periodic patterns and dominant frequency components. Experimental results conducted on multiple real-world wind farm datasets demonstrate that the proposed Fast-Powerformer achieves superior prediction accuracy and operational efficiency compared to mainstream forecasting approaches. Furthermore, the model exhibits fast inference speed and low memory consumption, highlighting its considerable practical value for real-world deployment scenarios.
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Models
Mar 20, 2025Semantic Interpretability in Reinforcement Learning (RL) enables transparency, accountability, and safer deployment by making the agent's decisions understandable and verifiable. Achieving this, however, requires a feature space composed of human-understandable concepts, which traditionally rely on human specification and fail to generalize to unseen environments. In this work, we introduce Semantically Interpretable Reinforcement Learning with Vision-Language Models Empowered Automation (SILVA), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and interpretable tree-based models for policy optimization. SILVA first queries a VLM to identify relevant semantic features for an unseen environment, then extracts these features from the environment. Finally, it trains an Interpretable Control Tree via RL, mapping the extracted features to actions in a transparent and interpretable manner. To address the computational inefficiency of extracting features directly with VLMs, we develop a feature extraction pipeline that generates a dataset for training a lightweight convolutional network, which is subsequently used during RL. By leveraging VLMs to automate tree-based RL, SILVA removes the reliance on human annotation previously required by interpretable models while also overcoming the inability of VLMs alone to generate valid robot policies, enabling semantically interpretable reinforcement learning without human-in-the-loop.
SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint
Mar 17, 2025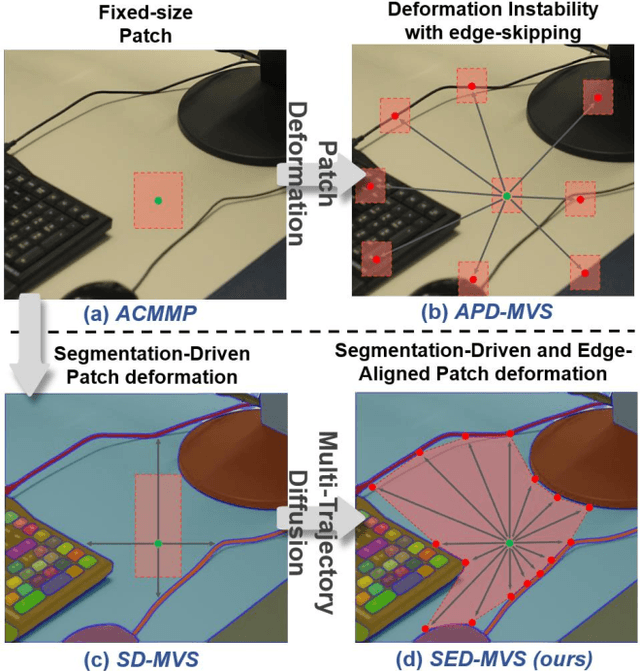
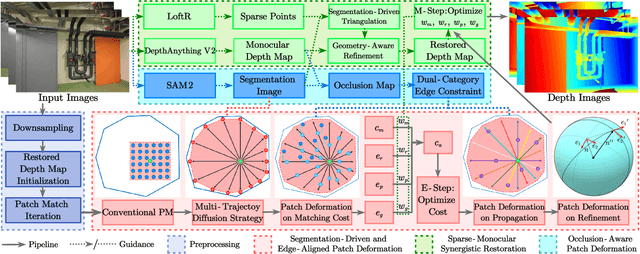
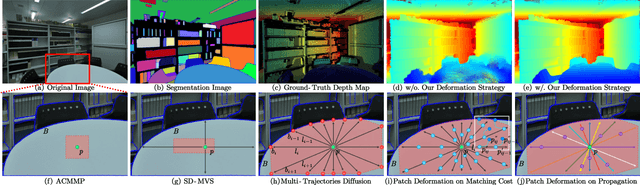

Recently, patch-deformation methods have exhibited significant effectiveness in multi-view stereo owing to the deformable and expandable patches in reconstructing textureless areas. However, such methods primarily emphasize broadening the receptive field in textureless areas, while neglecting deformation instability caused by easily overlooked edge-skipping, potentially leading to matching distortions. To address this, we propose SED-MVS, which adopts panoptic segmentation and multi-trajectory diffusion strategy for segmentation-driven and edge-aligned patch deformation. Specifically, to prevent unanticipated edge-skipping, we first employ SAM2 for panoptic segmentation as depth-edge guidance to guide patch deformation, followed by multi-trajectory diffusion strategy to ensure patches are comprehensively aligned with depth edges. Moreover, to avoid potential inaccuracy of random initialization, we combine both sparse points from LoFTR and monocular depth map from DepthAnything V2 to restore reliable and realistic depth map for initialization and supervised guidance. Finally, we integrate segmentation image with monocular depth map to exploit inter-instance occlusion relationship, then further regard them as occlusion map to implement two distinct edge constraint, thereby facilitating occlusion-aware patch deformation. Extensive results on ETH3D, Tanks & Temples, BlendedMVS and Strecha datasets validate the state-of-the-art performance and robust generalization capability of our proposed method.
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
Dec 16, 2024Patch deformation-based methods have recently exhibited substantial effectiveness in multi-view stereo, due to the incorporation of deformable and expandable perception to reconstruct textureless areas. However, such approaches typically focus on exploring correlative reliable pixels to alleviate match ambiguity during patch deformation, but ignore the deformation instability caused by mistaken edge-skipping and visibility occlusion, leading to potential estimation deviation. To remedy the above issues, we propose DVP-MVS, which innovatively synergizes depth-edge aligned and cross-view prior for robust and visibility-aware patch deformation. Specifically, to avoid unexpected edge-skipping, we first utilize Depth Anything V2 followed by the Roberts operator to initialize coarse depth and edge maps respectively, both of which are further aligned through an erosion-dilation strategy to generate fine-grained homogeneous boundaries for guiding patch deformation. In addition, we reform view selection weights as visibility maps and restore visible areas by cross-view depth reprojection, then regard them as cross-view prior to facilitate visibility-aware patch deformation. Finally, we improve propagation and refinement with multi-view geometry consistency by introducing aggregated visible hemispherical normals based on view selection and local projection depth differences based on epipolar lines, respectively. Extensive evaluations on ETH3D and Tanks & Temples benchmarks demonstrate that our method can achieve state-of-the-art performance with excellent robustness and generalization.
Exploring Personality-Driven Personalization in XAI: Enhancing User Trust in Gameplay
Aug 08, 2024Tailoring XAI methods to individual needs is crucial for intuitive Human-AI interactions. While context and task goals are vital, factors like user personality traits could also influence method selection. Our study investigates using personality traits to predict user preferences among decision trees, texts, and factor graphs. We trained a Machine Learning model on responses to the Big Five personality test to predict preferences. Deploying these predicted preferences in a navigation game (n=6), we found users more receptive to personalized XAI recommendations, enhancing trust in the system. This underscores the significance of customization in XAI interfaces, impacting user engagement and confidence.
Faster Model Predictive Control via Self-Supervised Initialization Learning
Aug 06, 2024



Optimization for robot control tasks, spanning various methodologies, includes Model Predictive Control (MPC). However, the complexity of the system, such as non-convex and non-differentiable cost functions and prolonged planning horizons often drastically increases the computation time, limiting MPC's real-world applicability. Prior works in speeding up the optimization have limitations on solving convex problem and generalizing to hold out domains. To overcome this challenge, we develop a novel framework aiming at expediting optimization processes. In our framework, we combine offline self-supervised learning and online fine-tuning through reinforcement learning to improve the control performance and reduce optimization time. We demonstrate the effectiveness of our method on a novel, challenging Formula-1-track driving task, achieving 3.9\% higher performance in optimization time and 3.6\% higher performance in tracking accuracy on challenging holdout tracks.
MSP-MVS: Multi-granularity Segmentation Prior Guided Multi-View Stereo
Jul 27, 2024Reconstructing textureless areas in MVS poses challenges due to the absence of reliable pixel correspondences within fixed patch. Although certain methods employ patch deformation to expand the receptive field, their patches mistakenly skip depth edges to calculate areas with depth discontinuity, thereby causing ambiguity. Consequently, we introduce Multi-granularity Segmentation Prior Multi-View Stereo (MSP-MVS). Specifically, we first propose multi-granularity segmentation prior by integrating multi-granularity depth edges to restrict patch deformation within homogeneous areas. Moreover, we present anchor equidistribution that bring deformed patches with more uniformly distributed anchors to ensure an adequate coverage of their own homogeneous areas. Furthermore, we introduce iterative local search optimization to represent larger patch with sparse representative candidates, significantly boosting the expressive capacity for each patch. The state-of-the-art results on ETH3D and Tanks & Temples benchmarks demonstrate the effectiveness and robust generalization ability of our proposed method.
SD-MVS: Segmentation-Driven Deformation Multi-View Stereo with Spherical Refinement and EM optimization
Jan 12, 2024



In this paper, we introduce Segmentation-Driven Deformation Multi-View Stereo (SD-MVS), a method that can effectively tackle challenges in 3D reconstruction of textureless areas. We are the first to adopt the Segment Anything Model (SAM) to distinguish semantic instances in scenes and further leverage these constraints for pixelwise patch deformation on both matching cost and propagation. Concurrently, we propose a unique refinement strategy that combines spherical coordinates and gradient descent on normals and pixelwise search interval on depths, significantly improving the completeness of reconstructed 3D model. Furthermore, we adopt the Expectation-Maximization (EM) algorithm to alternately optimize the aggregate matching cost and hyperparameters, effectively mitigating the problem of parameters being excessively dependent on empirical tuning. Evaluations on the ETH3D high-resolution multi-view stereo benchmark and the Tanks and Temples dataset demonstrate that our method can achieve state-of-the-art results with less time consumption.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.