 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025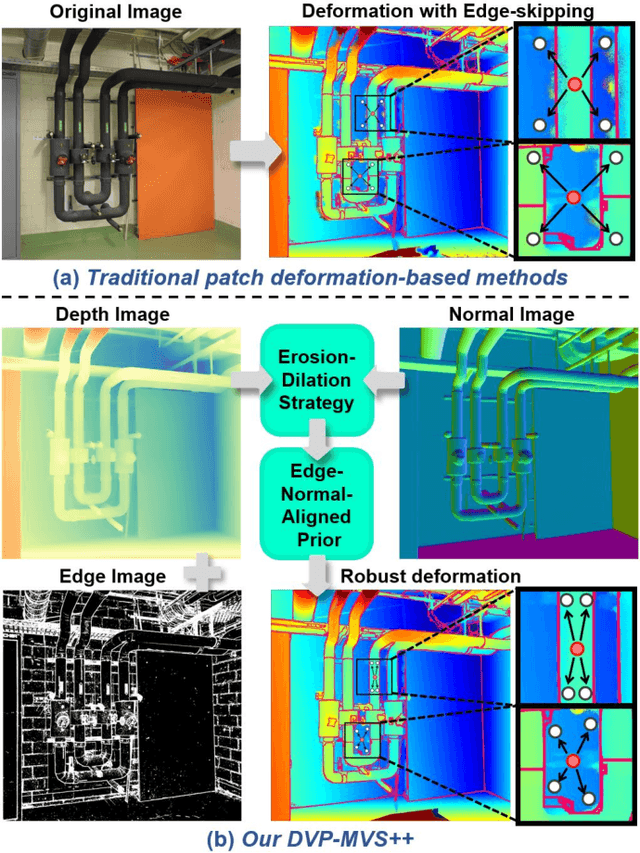
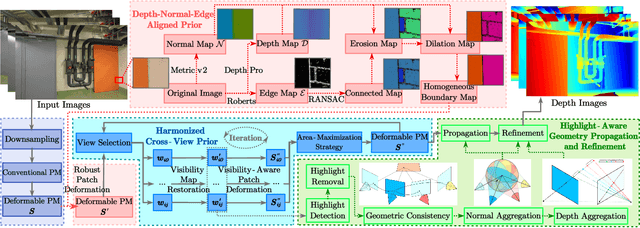
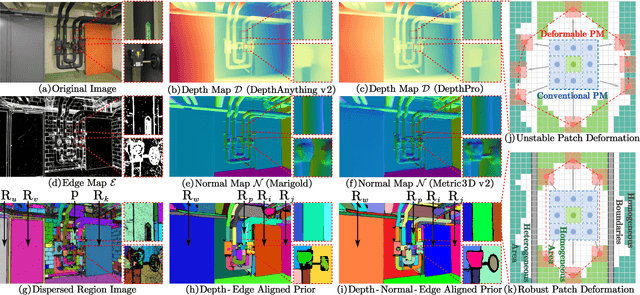
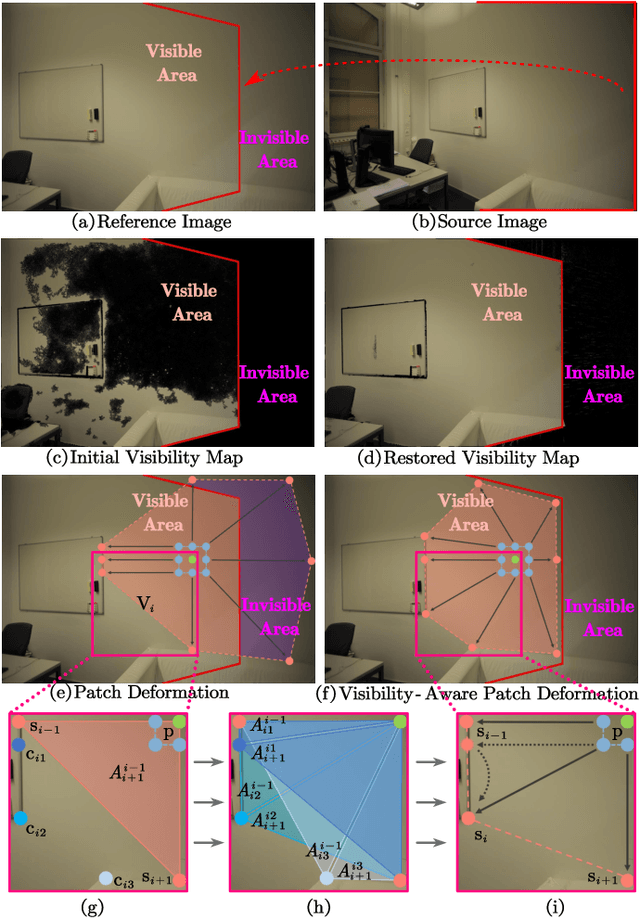
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
Jun 11, 2025Reconstructing dynamic 3D scenes from monocular videos remains a fundamental challenge in 3D vision. While 3D Gaussian Splatting (3DGS) achieves real-time rendering in static settings, extending it to dynamic scenes is challenging due to the difficulty of learning structured and temporally consistent motion representations. This challenge often manifests as three limitations in existing methods: redundant Gaussian updates, insufficient motion supervision, and weak modeling of complex non-rigid deformations. These issues collectively hinder coherent and efficient dynamic reconstruction. To address these limitations, we propose HAIF-GS, a unified framework that enables structured and consistent dynamic modeling through sparse anchor-driven deformation. It first identifies motion-relevant regions via an Anchor Filter to suppresses redundant updates in static areas. A self-supervised Induced Flow-Guided Deformation module induces anchor motion using multi-frame feature aggregation, eliminating the need for explicit flow labels. To further handle fine-grained deformations, a Hierarchical Anchor Propagation mechanism increases anchor resolution based on motion complexity and propagates multi-level transformations. Extensive experiments on synthetic and real-world benchmarks validate that HAIF-GS significantly outperforms prior dynamic 3DGS methods in rendering quality, temporal coherence, and reconstruction efficiency.
STDR: Spatio-Temporal Decoupling for Real-Time Dynamic Scene Rendering
May 28, 2025Although dynamic scene reconstruction has long been a fundamental challenge in 3D vision, the recent emergence of 3D Gaussian Splatting (3DGS) offers a promising direction by enabling high-quality, real-time rendering through explicit Gaussian primitives. However, existing 3DGS-based methods for dynamic reconstruction often suffer from \textit{spatio-temporal incoherence} during initialization, where canonical Gaussians are constructed by aggregating observations from multiple frames without temporal distinction. This results in spatio-temporally entangled representations, making it difficult to model dynamic motion accurately. To overcome this limitation, we propose \textbf{STDR} (Spatio-Temporal Decoupling for Real-time rendering), a plug-and-play module that learns spatio-temporal probability distributions for each Gaussian. STDR introduces a spatio-temporal mask, a separated deformation field, and a consistency regularization to jointly disentangle spatial and temporal patterns. Extensive experiments demonstrate that incorporating our module into existing 3DGS-based dynamic scene reconstruction frameworks leads to notable improvements in both reconstruction quality and spatio-temporal consistency across synthetic and real-world benchmarks.
Dual-Level Precision Edges Guided Multi-View Stereo with Accurate Planarization
Dec 29, 2024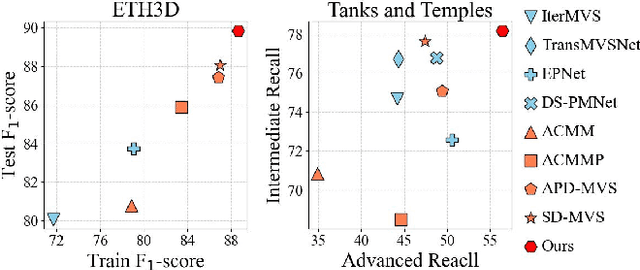
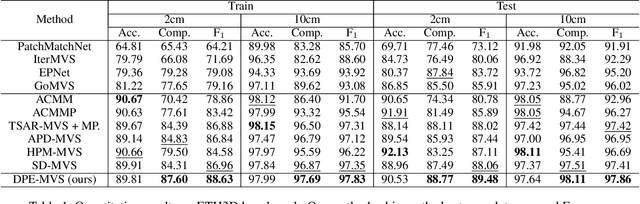

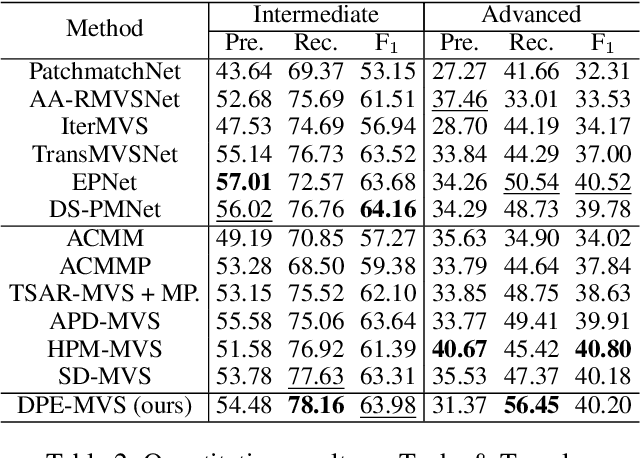
The reconstruction of low-textured areas is a prominent research focus in multi-view stereo (MVS). In recent years, traditional MVS methods have performed exceptionally well in reconstructing low-textured areas by constructing plane models. However, these methods often encounter issues such as crossing object boundaries and limited perception ranges, which undermine the robustness of plane model construction. Building on previous work (APD-MVS), we propose the DPE-MVS method. By introducing dual-level precision edge information, including fine and coarse edges, we enhance the robustness of plane model construction, thereby improving reconstruction accuracy in low-textured areas. Furthermore, by leveraging edge information, we refine the sampling strategy in conventional PatchMatch MVS and propose an adaptive patch size adjustment approach to optimize matching cost calculation in both stochastic and low-textured areas. This additional use of edge information allows for more precise and robust matching. Our method achieves state-of-the-art performance on the ETH3D and Tanks & Temples benchmarks. Notably, our method outperforms all published methods on the ETH3D benchmark.
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
Dec 16, 2024Patch deformation-based methods have recently exhibited substantial effectiveness in multi-view stereo, due to the incorporation of deformable and expandable perception to reconstruct textureless areas. However, such approaches typically focus on exploring correlative reliable pixels to alleviate match ambiguity during patch deformation, but ignore the deformation instability caused by mistaken edge-skipping and visibility occlusion, leading to potential estimation deviation. To remedy the above issues, we propose DVP-MVS, which innovatively synergizes depth-edge aligned and cross-view prior for robust and visibility-aware patch deformation. Specifically, to avoid unexpected edge-skipping, we first utilize Depth Anything V2 followed by the Roberts operator to initialize coarse depth and edge maps respectively, both of which are further aligned through an erosion-dilation strategy to generate fine-grained homogeneous boundaries for guiding patch deformation. In addition, we reform view selection weights as visibility maps and restore visible areas by cross-view depth reprojection, then regard them as cross-view prior to facilitate visibility-aware patch deformation. Finally, we improve propagation and refinement with multi-view geometry consistency by introducing aggregated visible hemispherical normals based on view selection and local projection depth differences based on epipolar lines, respectively. Extensive evaluations on ETH3D and Tanks & Temples benchmarks demonstrate that our method can achieve state-of-the-art performance with excellent robustness and generalization.
MSP-MVS: Multi-granularity Segmentation Prior Guided Multi-View Stereo
Jul 27, 2024Reconstructing textureless areas in MVS poses challenges due to the absence of reliable pixel correspondences within fixed patch. Although certain methods employ patch deformation to expand the receptive field, their patches mistakenly skip depth edges to calculate areas with depth discontinuity, thereby causing ambiguity. Consequently, we introduce Multi-granularity Segmentation Prior Multi-View Stereo (MSP-MVS). Specifically, we first propose multi-granularity segmentation prior by integrating multi-granularity depth edges to restrict patch deformation within homogeneous areas. Moreover, we present anchor equidistribution that bring deformed patches with more uniformly distributed anchors to ensure an adequate coverage of their own homogeneous areas. Furthermore, we introduce iterative local search optimization to represent larger patch with sparse representative candidates, significantly boosting the expressive capacity for each patch. The state-of-the-art results on ETH3D and Tanks & Temples benchmarks demonstrate the effectiveness and robust generalization ability of our proposed method.
EANet: Expert Attention Network for Online Trajectory Prediction
Sep 11, 2023



Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
XVTP3D: Cross-view Trajectory Prediction Using Shared 3D Queries for Autonomous Driving
Aug 17, 2023Trajectory prediction with uncertainty is a critical and challenging task for autonomous driving. Nowadays, we can easily access sensor data represented in multiple views. However, cross-view consistency has not been evaluated by the existing models, which might lead to divergences between the multimodal predictions from different views. It is not practical and effective when the network does not comprehend the 3D scene, which could cause the downstream module in a dilemma. Instead, we predicts multimodal trajectories while maintaining cross-view consistency. We presented a cross-view trajectory prediction method using shared 3D Queries (XVTP3D). We employ a set of 3D queries shared across views to generate multi-goals that are cross-view consistent. We also proposed a random mask method and coarse-to-fine cross-attention to capture robust cross-view features. As far as we know, this is the first work that introduces the outstanding top-down paradigm in BEV detection field to a trajectory prediction problem. The results of experiments on two publicly available datasets show that XVTP3D achieved state-of-the-art performance with consistent cross-view predictions.