 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIM: Frequency-Aware Multi-View Interest Modeling for Local-Life Service Recommendation
Apr 30, 2025People's daily lives involve numerous periodic behaviors, such as eating and traveling. Local-life platforms cater to these recurring needs by providing essential services tied to daily routines. Therefore, users' periodic intentions are reflected in their interactions with the platforms. There are two main challenges in modeling users' periodic behaviors in the local-life service recommendation systems: 1) the diverse demands of users exhibit varying periodicities, which are difficult to distinguish as they are mixed in the behavior sequences; 2) the periodic behaviors of users are subject to dynamic changes due to factors such as holidays and promotional events. Existing methods struggle to distinguish the periodicities of diverse demands and overlook the importance of dynamically capturing changes in users' periodic behaviors. To this end, we employ a Frequency-Aware Multi-View Interest Modeling framework (FIM). Specifically, we propose a multi-view search strategy that decomposes users' demands from different perspectives to separate their various periodic intentions. This allows the model to comprehensively extract their periodic features than category-searched-only methods. Moreover, we propose a frequency-domain perception and evolution module. This module uses the Fourier Transform to convert users' temporal behaviors into the frequency domain, enabling the model to dynamically perceive their periodic features. Extensive offline experiments demonstrate that FIM achieves significant improvements on public and industrial datasets, showing its capability to effectively model users' periodic intentions. Furthermore, the model has been deployed on the Kuaishou local-life service platform. Through online A/B experiments, the transaction volume has been significantly improved.
EANet: Expert Attention Network for Online Trajectory Prediction
Sep 11, 2023



Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
Reinforced Disentanglement for Face Swapping without Skip Connection
Aug 03, 2023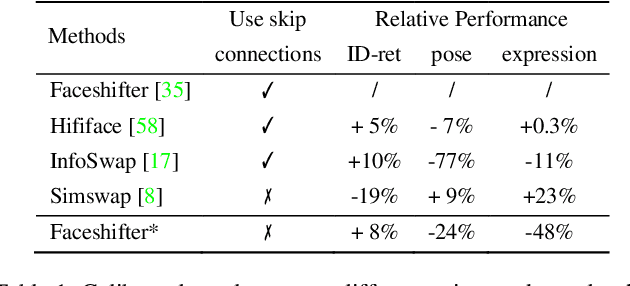
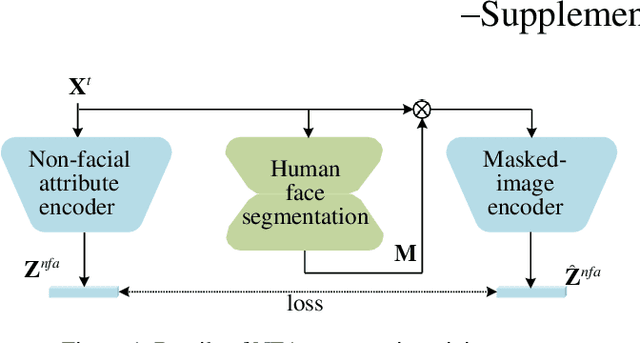
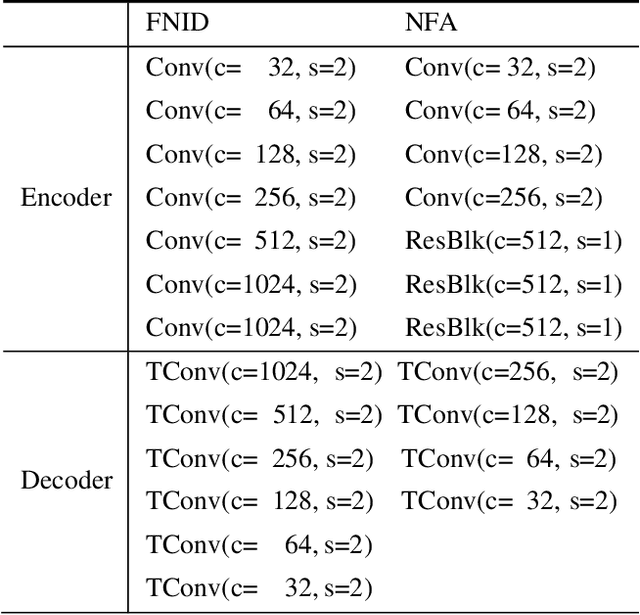

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a Single Color Image
Mar 28, 2019
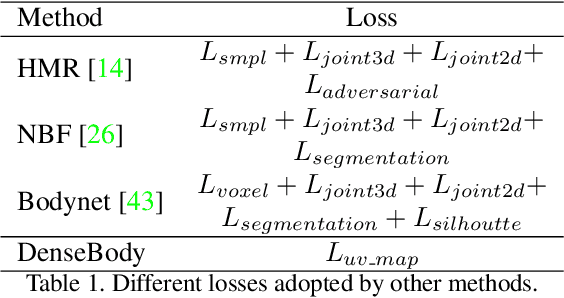
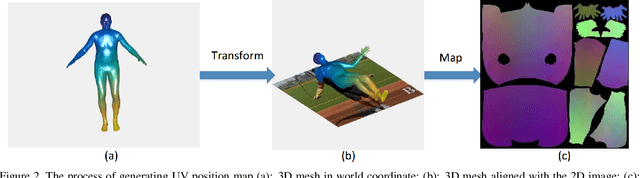

Recovering 3D human body shape and pose from 2D images is a challenging task due to high complexity and flexibility of human body, and relatively less 3D labeled data. Previous methods addressing these issues typically rely on predicting intermediate results such as body part segmentation, 2D/3D joints, silhouette mask to decompose the problem into multiple sub-tasks in order to utilize more 2D labels. Most previous works incorporated parametric body shape model in their methods and predict parameters in low-dimensional space to represent human body. In this paper, we propose to directly regress the 3D human mesh from a single color image using Convolutional Neural Network(CNN). We use an efficient representation of 3D human shape and pose which can be predicted through an encoder-decoder neural network. The proposed method achieves state-of-the-art performance on several 3D human body datasets including Human3.6M, SURREAL and UP-3D with even faster running speed.