 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
Apr 03, 2026Competitive programming remains one of the last few human strongholds in coding against AI. The best AI system to date still underperforms the best humans competitive programming: the most recent best result, Google's Gemini~3 Deep Think, attained 8th place even not being evaluated under live competition conditions. In this work, we introduce GrandCode, a multi-agent RL system designed for competitive programming. The capability of GrandCode is attributed to two key factors: (1) It orchestrates a variety of agentic modules (hypothesis proposal, solver, test generator, summarization, etc) and jointly improves them through post-training and online test-time RL; (2) We introduce Agentic GRPO specifically designed for multi-stage agent rollouts with delayed rewards and the severe off-policy drift that is prevalent in agentic RL. GrandCode is the first AI system that consistently beats all human participants in live contests of competitive programming: in the most recent three Codeforces live competitions, i.e., Round~1087 (Mar 21, 2026), Round~1088 (Mar 28, 2026), and Round~1089 (Mar 29, 2026), GrandCode placed first in all of them, beating all human participants, including legendary grandmasters. GrandCode shows that AI systems have reached a point where they surpass the strongest human programmers on the most competitive coding tasks.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025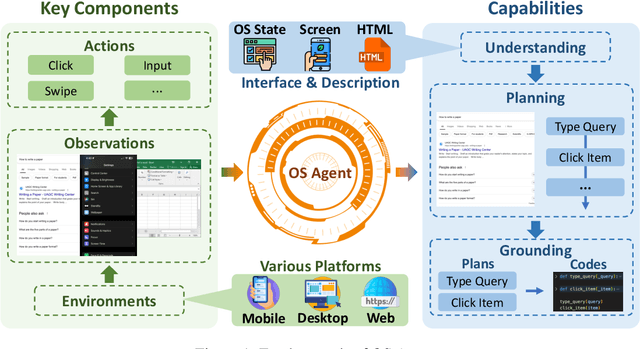
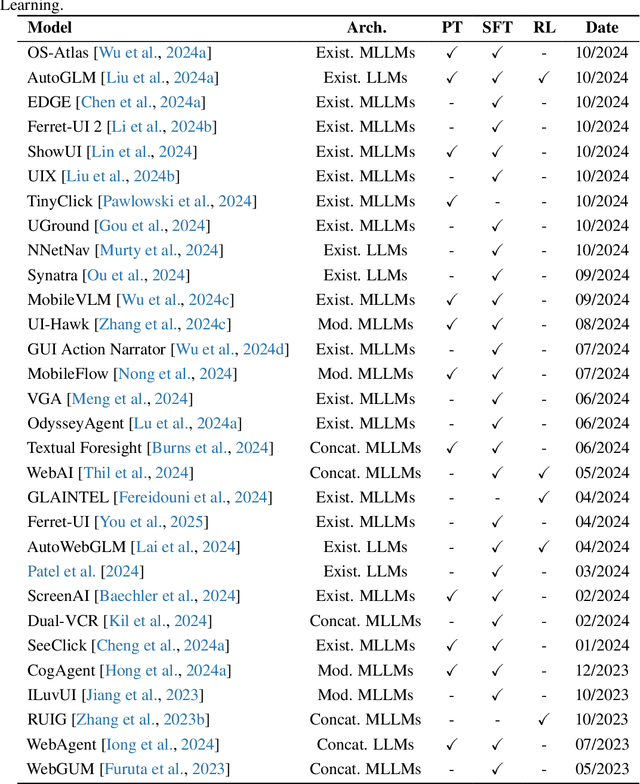
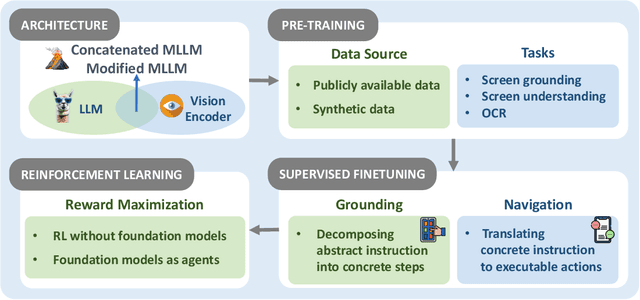
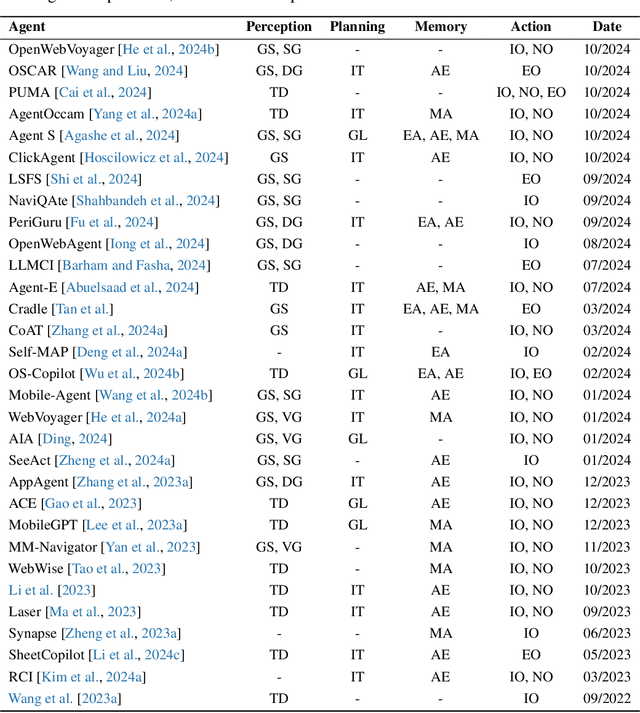
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
Jul 18, 2025The exponential growth in demand for GPU computing resources, driven by the rapid advancement of Large Language Models, has created an urgent need for automated CUDA optimization strategies. While recent advances in LLMs show promise for code generation, current SOTA models (e.g. R1, o1) achieve low success rates in improving CUDA speed. In this paper, we introduce CUDA-L1, an automated reinforcement learning framework for CUDA optimization. CUDA-L1 achieves performance improvements on the CUDA optimization task: trained on NVIDIA A100, it delivers an average speedup of x17.7 across all 250 CUDA kernels of KernelBench, with peak speedups reaching x449. Furthermore, the model also demonstrates excellent portability across GPU architectures, achieving average speedups of x17.8 on H100, x19.0 on RTX 3090, x16.5 on L40, x14.7 on H800, and x13.9 on H20 despite being optimized specifically for A100. Beyond these benchmark results, CUDA-L1 demonstrates several remarkable properties: 1) Discovers a variety of CUDA optimization techniques and learns to combine them strategically to achieve optimal performance; 2) Uncovers fundamental principles of CUDA optimization; 3) Identifies non-obvious performance bottlenecks and rejects seemingly beneficial optimizations that harm performance. The capabilities of CUDA-L1 demonstrate that reinforcement learning can transform an initially poor-performing LLM into an effective CUDA optimizer through speedup-based reward signals alone, without human expertise or domain knowledge. More importantly, the trained RL model extend the acquired reasoning abilities to new kernels. This paradigm opens possibilities for automated optimization of CUDA operations, and holds promise to substantially promote GPU efficiency and alleviate the rising pressure on GPU computing resources.
Device-Cloud Collaborative Correction for On-Device Recommendation
Jun 15, 2025With the rapid development of recommendation models and device computing power, device-based recommendation has become an important research area due to its better real-time performance and privacy protection. Previously, Transformer-based sequential recommendation models have been widely applied in this field because they outperform Recurrent Neural Network (RNN)-based recommendation models in terms of performance. However, as the length of interaction sequences increases, Transformer-based models introduce significantly more space and computational overhead compared to RNN-based models, posing challenges for device-based recommendation. To balance real-time performance and high performance on devices, we propose Device-Cloud \underline{Co}llaborative \underline{Corr}ection Framework for On-Device \underline{Rec}ommendation (CoCorrRec). CoCorrRec uses a self-correction network (SCN) to correct parameters with extremely low time cost. By updating model parameters during testing based on the input token, it achieves performance comparable to current optimal but more complex Transformer-based models. Furthermore, to prevent SCN from overfitting, we design a global correction network (GCN) that processes hidden states uploaded from devices and provides a global correction solution. Extensive experiments on multiple datasets show that CoCorrRec outperforms existing Transformer-based and RNN-based device recommendation models in terms of performance, with fewer parameters and lower FLOPs, thereby achieving a balance between real-time performance and high efficiency.
K2MUSE: A human lower limb multimodal dataset under diverse conditions for facilitating rehabilitation robotics
Apr 20, 2025The natural interaction and control performance of lower limb rehabilitation robots are closely linked to biomechanical information from various human locomotion activities. Multidimensional human motion data significantly deepen the understanding of the complex mechanisms governing neuromuscular alterations, thereby facilitating the development and application of rehabilitation robots in multifaceted real-world environments. However, currently available lower limb datasets are inadequate for supplying the essential multimodal data and large-scale gait samples necessary for effective data-driven approaches, and they neglect the significant effects of acquisition interference in real applications.To fill this gap, we present the K2MUSE dataset, which includes a comprehensive collection of multimodal data, comprising kinematic, kinetic, amplitude-mode ultrasound (AUS), and surface electromyography (sEMG) measurements. The proposed dataset includes lower limb multimodal data from 30 able-bodied participants walking under different inclines (0$^\circ$, $\pm$5$^\circ$, and $\pm$10$^\circ$), various speeds (0.5 m/s, 1.0 m/s, and 1.5 m/s), and different nonideal acquisition conditions (muscle fatigue, electrode shifts, and inter-day differences). The kinematic and ground reaction force data were collected via a Vicon motion capture system and an instrumented treadmill with embedded force plates, whereas the sEMG and AUS data were synchronously recorded for thirteen muscles on the bilateral lower limbs. This dataset offers a new resource for designing control frameworks for rehabilitation robots and conducting biomechanical analyses of lower limb locomotion. The dataset is available at https://k2muse.github.io/.
Mask Image Watermarking
Apr 17, 2025
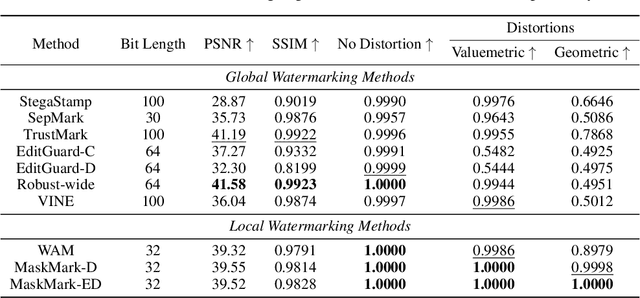
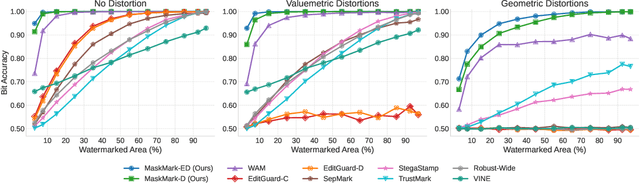

We present MaskMark, a simple, efficient and flexible framework for image watermarking. MaskMark has two variants: MaskMark-D, which supports global watermark embedding, watermark localization, and local watermark extraction for applications such as tamper detection, and MaskMark-ED, which focuses on local watermark embedding and extraction with enhanced robustness in small regions, enabling localized image protection. Built upon the classical Encoder- Distortion-Decoder training paradigm, MaskMark-D introduces a simple masking mechanism during the decoding stage to support both global and local watermark extraction. A mask is applied to the watermarked image before extraction, allowing the decoder to focus on selected regions and learn local extraction. A localization module is also integrated into the decoder to identify watermark regions during inference, reducing interference from irrelevant content and improving accuracy. MaskMark-ED extends this design by incorporating the mask into the encoding stage as well, guiding the encoder to embed the watermark in designated local regions for enhanced robustness. Comprehensive experiments show that MaskMark achieves state-of-the-art performance in global watermark extraction, local watermark extraction, watermark localization, and multi-watermark embedding. It outperforms all existing baselines, including the recent leading model WAM for local watermarking, while preserving high visual quality of the watermarked images. MaskMark is also flexible, by adjusting the distortion layer, it can adapt to different robustness requirements with just a few steps of fine-tuning. Moreover, our approach is efficient and easy to optimize, requiring only 20 hours on a single A6000 GPU with just 1/15 the computational cost of WAM.
FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
Mar 11, 2025Due to the data-driven nature of current face identity (FaceID) customization methods, all state-of-the-art models rely on large-scale datasets containing millions of high-quality text-image pairs for training. However, none of these datasets are publicly available, which restricts transparency and hinders further advancements in the field. To address this issue, in this paper, we collect and release FaceID-6M, the first large-scale, open-source FaceID dataset containing 6 million high-quality text-image pairs. Filtered from LAION-5B \cite{schuhmann2022laion}, FaceID-6M undergoes a rigorous image and text filtering steps to ensure dataset quality, including resolution filtering to maintain high-quality images and faces, face filtering to remove images that lack human faces, and keyword-based strategy to retain descriptions containing human-related terms (e.g., nationality, professions and names). Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development. We conduct extensive experiments to show the effectiveness of our FaceID-6M, demonstrating that models trained on our FaceID-6M dataset achieve performance that is comparable to, and slightly better than currently available industrial models. Additionally, to support and advance research in the FaceID customization community, we make our code, datasets, and models fully publicly available. Our codes, models, and datasets are available at: https://github.com/ShuheSH/FaceID-6M.
Picky LLMs and Unreliable RMs: An Empirical Study on Safety Alignment after Instruction Tuning
Feb 03, 2025Large language models (LLMs) have emerged as powerful tools for addressing a wide range of general inquiries and tasks. Despite this, fine-tuning aligned LLMs on smaller, domain-specific datasets, critical to adapting them to specialized tasks, can inadvertently degrade their safety alignment, even when the datasets are benign. This phenomenon makes models more susceptible to providing inappropriate responses. In this study, we systematically examine the factors contributing to safety alignment degradation in benign fine-tuning scenarios. Our analysis identifies three critical factors affecting aligned LLMs: answer structure, identity calibration, and role-play. Additionally, we evaluate the reliability of state-of-the-art reward models (RMs), which are often used to guide alignment processes. Our findings reveal that these RMs frequently fail to accurately reflect human preferences regarding safety, underscoring their limitations in practical applications. By uncovering these challenges, our work highlights the complexities of maintaining safety alignment during fine-tuning and offers guidance to help developers balance utility and safety in LLMs. Datasets and fine-tuning code used in our experiments can be found in https://github.com/GuanlinLee/llm_instruction_tuning.
Turn That Frown Upside Down: FaceID Customization via Cross-Training Data
Jan 26, 2025



Existing face identity (FaceID) customization methods perform well but are limited to generating identical faces as the input, while in real-world applications, users often desire images of the same person but with variations, such as different expressions (e.g., smiling, angry) or angles (e.g., side profile). This limitation arises from the lack of datasets with controlled input-output facial variations, restricting models' ability to learn effective modifications. To address this issue, we propose CrossFaceID, the first large-scale, high-quality, and publicly available dataset specifically designed to improve the facial modification capabilities of FaceID customization models. Specifically, CrossFaceID consists of 40,000 text-image pairs from approximately 2,000 persons, with each person represented by around 20 images showcasing diverse facial attributes such as poses, expressions, angles, and adornments. During the training stage, a specific face of a person is used as input, and the FaceID customization model is forced to generate another image of the same person but with altered facial features. This allows the FaceID customization model to acquire the ability to personalize and modify known facial features during the inference stage. Experiments show that models fine-tuned on the CrossFaceID dataset retain its performance in preserving FaceID fidelity while significantly improving its face customization capabilities. To facilitate further advancements in the FaceID customization field, our code, constructed datasets, and trained models are fully available to the public.
VideoShield: Regulating Diffusion-based Video Generation Models via Watermarking
Jan 24, 2025



Artificial Intelligence Generated Content (AIGC) has advanced significantly, particularly with the development of video generation models such as text-to-video (T2V) models and image-to-video (I2V) models. However, like other AIGC types, video generation requires robust content control. A common approach is to embed watermarks, but most research has focused on images, with limited attention given to videos. Traditional methods, which embed watermarks frame-by-frame in a post-processing manner, often degrade video quality. In this paper, we propose VideoShield, a novel watermarking framework specifically designed for popular diffusion-based video generation models. Unlike post-processing methods, VideoShield embeds watermarks directly during video generation, eliminating the need for additional training. To ensure video integrity, we introduce a tamper localization feature that can detect changes both temporally (across frames) and spatially (within individual frames). Our method maps watermark bits to template bits, which are then used to generate watermarked noise during the denoising process. Using DDIM Inversion, we can reverse the video to its original watermarked noise, enabling straightforward watermark extraction. Additionally, template bits allow precise detection for potential temporal and spatial modification. Extensive experiments across various video models (both T2V and I2V models) demonstrate that our method effectively extracts watermarks and detects tamper without compromising video quality. Furthermore, we show that this approach is applicable to image generation models, enabling tamper detection in generated images as well. Codes and models are available at \href{https://github.com/hurunyi/VideoShield}{https://github.com/hurunyi/VideoShield}.