 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacoMAS: Test-Time Co-Evolution of Topology and Capability in LLM-based Multi-Agent Systems
May 10, 2026Multi-agent systems (MAS) have emerged as a promising paradigm for solving complex tasks. Recent work has explored self-evolving MAS that automatically optimize agent capabilities or communication topologies. However, existing methods either learn a topology that remains fixed at inference time or adapt only the topology or capability during inference. We empirically and theoretically show that effective test-time evolution requires jointly adapting both axes, but on different time scales: capabilities should update rapidly to handle emerging subtasks, while the topology should evolve more slowly to preserve coordination stability. We then introduce TacoMAS, a test-time co-evolution framework for dynamic MAS. TacoMAS formulates MAS inference as a task of online graph adaptation, where nodes represent agents with role-specific capabilities and edges define their communication topology. During inference, a fast capability loop updates agent expertise using trajectory-level feedback, while a slow meta-LLM-driven topology loop performs agents' birth-death operations on MAS, including edge edit, agent addition, and agent removal. We further show that this fast-slow design drives MAS evolution toward a task-conditioned stable equilibrium. Experiments on four benchmarks demonstrate that TacoMAS outperforms nearly 20 multi-agent baselines, achieving an average improvement of 13.3% over the strongest baseline. The codes are released at https://github.com/chenxu2-gif/TacoMAS-MultiAgent.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
CAPSUL: A Comprehensive Human Protein Benchmark for Subcellular Localization
Mar 19, 2026Subcellular localization is a crucial biological task for drug target identification and function annotation. Although it has been biologically realized that subcellular localization is closely associated with protein structure, no existing dataset offers comprehensive 3D structural information with detailed subcellular localization annotations, thus severely hindering the application of promising structure-based models on this task. To address this gap, we introduce a new benchmark called $\mathbf{CAPSUL}$, a $\mathbf{C}$omprehensive hum$\mathbf{A}$n $\mathbf{P}$rotein benchmark for $\mathbf{SU}$bcellular $\mathbf{L}$ocalization. It features a dataset that integrates diverse 3D structural representations with fine-grained subcellular localization annotations carefully curated by domain experts. We evaluate this benchmark using a variety of state-of-the-art sequence-based and structure-based models, showcasing the importance of involving structural features in this task. Furthermore, we explore reweighting and single-label classification strategies to facilitate future investigation on structure-based methods for this task. Lastly, we showcase the powerful interpretability of structure-based methods through a case study on the Golgi apparatus, where we discover a decisive localization pattern $α$-helix from attention mechanisms, demonstrating the potential for bridging the gap with intuitive biological interpretability and paving the way for data-driven discoveries in cell biology.
Verifiable Reasoning for LLM-based Generative Recommendation
Mar 08, 2026Reasoning in Large Language Models (LLMs) has recently shown strong potential in enhancing generative recommendation through deep understanding of complex user preference. Existing approaches follow a {reason-then-recommend} paradigm, where LLMs perform step-by-step reasoning before item generation. However, this paradigm inevitably suffers from reasoning degradation (i.e., homogeneous or error-accumulated reasoning) due to the lack of intermediate verification, thus undermining the recommendation. To bridge this gap, we propose a novel \textbf{\textit{reason-verify-recommend}} paradigm, which interleaves reasoning with verification to provide reliable feedback, guiding the reasoning process toward more faithful user preference understanding. To enable effective verification, we establish two key principles for verifier design: 1) reliability ensures accurate evaluation of reasoning correctness and informative guidance generation; and 2) multi-dimensionality emphasizes comprehensive verification across multi-dimensional user preferences. Accordingly, we propose an effective implementation called VRec. It employs a mixture of verifiers to ensure multi-dimensionality, while leveraging a proxy prediction objective to pursue reliability. Experiments on four real-world datasets demonstrate that VRec substantially enhances recommendation effectiveness and scalability without compromising efficiency. The codes can be found at https://github.com/Linxyhaha/Verifiable-Rec.
Bringing Reasoning to Generative Recommendation Through the Lens of Cascaded Ranking
Feb 03, 2026Generative Recommendation (GR) has become a promising end-to-end approach with high FLOPS utilization for resource-efficient recommendation. Despite the effectiveness, we show that current GR models suffer from a critical \textbf{bias amplification} issue, where token-level bias escalates as token generation progresses, ultimately limiting the recommendation diversity and hurting the user experience. By comparing against the key factor behind the success of traditional multi-stage pipelines, we reveal two limitations in GR that can amplify the bias: homogeneous reliance on the encoded history, and fixed computational budgets that prevent deeper user preference understanding. To combat the bias amplification issue, it is crucial for GR to 1) incorporate more heterogeneous information, and 2) allocate greater computational resources at each token generation step. To this end, we propose CARE, a simple yet effective cascaded reasoning framework for debiased GR. To incorporate heterogeneous information, we introduce a progressive history encoding mechanism, which progressively incorporates increasingly fine-grained history information as the generation process advances. To allocate more computations, we propose a query-anchored reasoning mechanism, which seeks to perform a deeper understanding of historical information through parallel reasoning steps. We instantiate CARE on three GR backbones. Empirical results on four datasets show the superiority of CARE in recommendation accuracy, diversity, efficiency, and promising scalability. The codes and datasets are available at https://github.com/Linxyhaha/CARE.
Navigating Through Paper Flood: Advancing LLM-based Paper Evaluation through Domain-Aware Retrieval and Latent Reasoning
Aug 07, 2025With the rapid and continuous increase in academic publications, identifying high-quality research has become an increasingly pressing challenge. While recent methods leveraging Large Language Models (LLMs) for automated paper evaluation have shown great promise, they are often constrained by outdated domain knowledge and limited reasoning capabilities. In this work, we present PaperEval, a novel LLM-based framework for automated paper evaluation that addresses these limitations through two key components: 1) a domain-aware paper retrieval module that retrieves relevant concurrent work to support contextualized assessments of novelty and contributions, and 2) a latent reasoning mechanism that enables deep understanding of complex motivations and methodologies, along with comprehensive comparison against concurrently related work, to support more accurate and reliable evaluation. To guide the reasoning process, we introduce a progressive ranking optimization strategy that encourages the LLM to iteratively refine its predictions with an emphasis on relative comparison. Experiments on two datasets demonstrate that PaperEval consistently outperforms existing methods in both academic impact and paper quality evaluation. In addition, we deploy PaperEval in a real-world paper recommendation system for filtering high-quality papers, which has gained strong engagement on social media -- amassing over 8,000 subscribers and attracting over 10,000 views for many filtered high-quality papers -- demonstrating the practical effectiveness of PaperEval.
Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
Jul 22, 2025
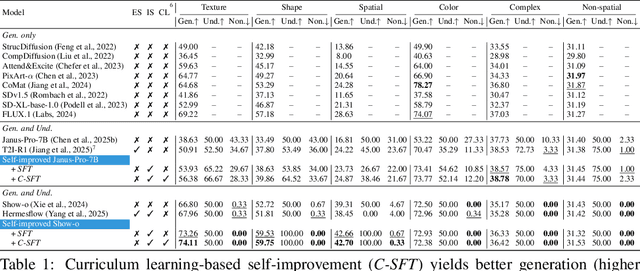
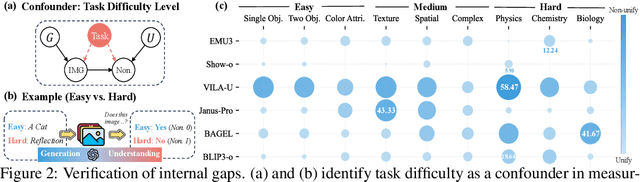

Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
$\text{R}^2\text{ec}$: Towards Large Recommender Models with Reasoning
May 22, 2025Large recommender models have extended LLMs as powerful recommenders via encoding or item generation, and recent breakthroughs in LLM reasoning synchronously motivate the exploration of reasoning in recommendation. Current studies usually position LLMs as external reasoning modules to yield auxiliary thought for augmenting conventional recommendation pipelines. However, such decoupled designs are limited in significant resource cost and suboptimal joint optimization. To address these issues, we propose \name, a unified large recommender model with intrinsic reasoning capabilities. Initially, we reconceptualize the model architecture to facilitate interleaved reasoning and recommendation in the autoregressive process. Subsequently, we propose RecPO, a corresponding reinforcement learning framework that optimizes \name\ both the reasoning and recommendation capabilities simultaneously in a single policy update; RecPO introduces a fused reward scheme that solely leverages recommendation labels to simulate the reasoning capability, eliminating dependency on specialized reasoning annotations. Experiments on three datasets with various baselines verify the effectiveness of \name, showing relative improvements of 68.67\% in Hit@5 and 45.21\% in NDCG@20. Code available at https://github.com/YRYangang/RRec.
Collaboration of Large Language Models and Small Recommendation Models for Device-Cloud Recommendation
Jan 10, 2025Large Language Models (LLMs) for Recommendation (LLM4Rec) is a promising research direction that has demonstrated exceptional performance in this field. However, its inability to capture real-time user preferences greatly limits the practical application of LLM4Rec because (i) LLMs are costly to train and infer frequently, and (ii) LLMs struggle to access real-time data (its large number of parameters poses an obstacle to deployment on devices). Fortunately, small recommendation models (SRMs) can effectively supplement these shortcomings of LLM4Rec diagrams by consuming minimal resources for frequent training and inference, and by conveniently accessing real-time data on devices. In light of this, we designed the Device-Cloud LLM-SRM Collaborative Recommendation Framework (LSC4Rec) under a device-cloud collaboration setting. LSC4Rec aims to integrate the advantages of both LLMs and SRMs, as well as the benefits of cloud and edge computing, achieving a complementary synergy. We enhance the practicability of LSC4Rec by designing three strategies: collaborative training, collaborative inference, and intelligent request. During training, LLM generates candidate lists to enhance the ranking ability of SRM in collaborative scenarios and enables SRM to update adaptively to capture real-time user interests. During inference, LLM and SRM are deployed on the cloud and on the device, respectively. LLM generates candidate lists and initial ranking results based on user behavior, and SRM get reranking results based on the candidate list, with final results integrating both LLM's and SRM's scores. The device determines whether a new candidate list is needed by comparing the consistency of the LLM's and SRM's sorted lists. Our comprehensive and extensive experimental analysis validates the effectiveness of each strategy in LSC4Rec.
Node Importance Estimation Leveraging LLMs for Semantic Augmentation in Knowledge Graphs
Nov 30, 2024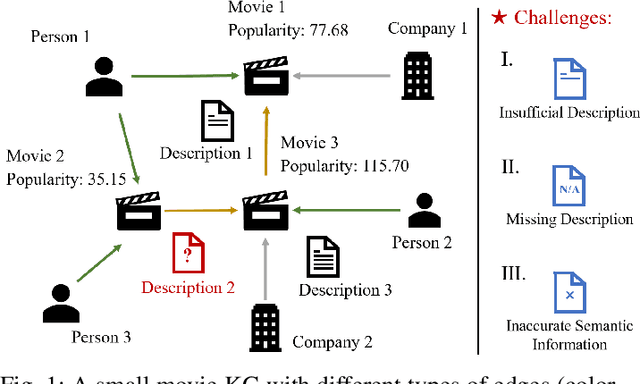
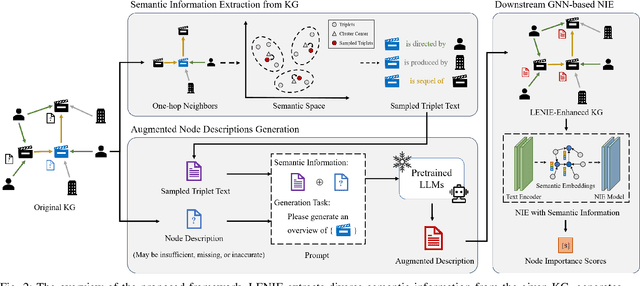


Node Importance Estimation (NIE) is a task that quantifies the importance of node in a graph. Recent research has investigated to exploit various information from Knowledge Graphs (KGs) to estimate node importance scores. However, the semantic information in KGs could be insufficient, missing, and inaccurate, which would limit the performance of existing NIE models. To address these issues, we leverage Large Language Models (LLMs) for semantic augmentation thanks to the LLMs' extra knowledge and ability of integrating knowledge from both LLMs and KGs. To this end, we propose the LLMs Empowered Node Importance Estimation (LENIE) method to enhance the semantic information in KGs for better supporting NIE tasks. To our best knowledge, this is the first work incorporating LLMs into NIE. Specifically, LENIE employs a novel clustering-based triplet sampling strategy to extract diverse knowledge of a node sampled from the given KG. After that, LENIE adopts the node-specific adaptive prompts to integrate the sampled triplets and the original node descriptions, which are then fed into LLMs for generating richer and more precise augmented node descriptions. These augmented descriptions finally initialize node embeddings for boosting the downstream NIE model performance. Extensive experiments demonstrate LENIE's effectiveness in addressing semantic deficiencies in KGs, enabling more informative semantic augmentation and enhancing existing NIE models to achieve the state-of-the-art performance. The source code of LENIE is freely available at \url{https://github.com/XinyuLin-FZ/LENIE}.