 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference for Large Language Model-based Generative Recommendation
Paper and Code
Oct 07, 2024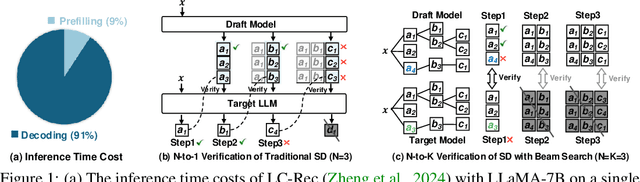

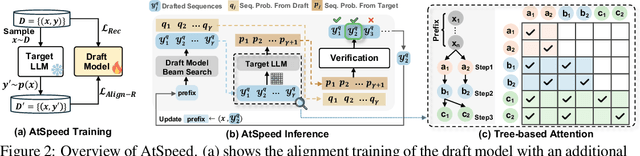

Large Language Model (LLM)-based generative recommendation has achieved notable success, yet its practical deployment is costly particularly due to excessive inference latency caused by autoregressive decoding. For lossless LLM decoding acceleration, Speculative Decoding (SD) has emerged as a promising solution. However, applying SD to generative recommendation presents unique challenges due to the requirement of generating top-K items (i.e., K distinct token sequences) as a recommendation list by beam search. This leads to more stringent verification in SD, where all the top-K sequences from the target LLM must be successfully drafted by the draft model at each decoding step. To alleviate this, we consider 1) boosting top-K sequence alignment between the draft model and the target LLM, and 2) relaxing the verification strategy to reduce trivial LLM calls. To this end, we propose an alignment framework named AtSpeed, which presents the AtSpeed-S optimization objective for top-K alignment under the strict top-K verification. Moreover, we introduce a relaxed sampling verification strategy that allows high-probability non-top-K drafted sequences to be accepted, significantly reducing LLM calls. Correspondingly, we propose AtSpeed-R for top-K alignment under this relaxed sampling verification. Empirical results on two real-world datasets demonstrate that AtSpeed significantly accelerates LLM-based generative recommendation, e.g., near 2x speedup under strict top-K verification and up to 2.5 speedup under relaxed sampling verification. The codes and datasets will be released in the near future.