 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTInR: Exploring Tool-Internalized Reasoning in Large Language Models
Apr 12, 2026Tool-Integrated Reasoning (TIR) has emerged as a promising direction by extending Large Language Models' (LLMs) capabilities with external tools during reasoning. Existing TIR methods typically rely on external tool documentation during reasoning. However, this leads to tool mastery difficulty, tool size constraints, and inference inefficiency. To mitigate these issues, we explore Tool-Internalized Reasoning (TInR), aiming at facilitating reasoning with tool knowledge internalized into LLMs. Achieving this goal presents notable requirements, including tool internalization and tool-reasoning coordination. To address them, we propose TInR-U, a tool-internalized reasoning framework for unified reasoning and tool usage. TInR-U is trained through a three-phase pipeline: 1) tool internalization with a bidirectional knowledge alignment strategy; 2) supervised fine-tuning warm-up using high-quality reasoning annotations, and 3) reinforcement learning with TInR-specific rewards. We comprehensively evaluate our method across in-domain and out-of-domain settings. Experiment results show that TInR-U achieves superior performance in both settings, highlighting its effectiveness and efficiency.
One Adapts to Any: Meta Reward Modeling for Personalized LLM Alignment
Jan 26, 2026Alignment of Large Language Models (LLMs) aims to align outputs with human preferences, and personalized alignment further adapts models to individual users. This relies on personalized reward models that capture user-specific preferences and automatically provide individualized feedback. However, developing these models faces two critical challenges: the scarcity of feedback from individual users and the need for efficient adaptation to unseen users. We argue that addressing these constraints requires a paradigm shift from fitting data to learn user preferences to learn the process of preference adaptation. To realize this, we propose Meta Reward Modeling (MRM), which reformulates personalized reward modeling as a meta-learning problem. Specifically, we represent each user's reward model as a weighted combination of base reward functions, and optimize the initialization of these weights using a Model-Agnostic Meta-Learning (MAML)-style framework to support fast adaptation under limited feedback. To ensure robustness, we introduce the Robust Personalization Objective (RPO), which places greater emphasis on hard-to-learn users during meta optimization. Extensive experiments on personalized preference datasets validate that MRM enhances few-shot personalization, improves user robustness, and consistently outperforms baselines.
AR-Omni: A Unified Autoregressive Model for Any-to-Any Generation
Jan 25, 2026Real-world perception and interaction are inherently multimodal, encompassing not only language but also vision and speech, which motivates the development of "Omni" MLLMs that support both multimodal inputs and multimodal outputs. While a sequence of omni MLLMs has emerged, most existing systems still rely on additional expert components to achieve multimodal generation, limiting the simplicity of unified training and inference. Autoregressive (AR) modeling, with a single token stream, a single next-token objective, and a single decoder, is an elegant and scalable foundation in the text domain. Motivated by this, we present AR-Omni, a unified any-to-any model in the autoregressive paradigm without any expert decoders. AR-Omni supports autoregressive text and image generation, as well as streaming speech generation, all under a single Transformer decoder. We further address three practical issues in unified AR modeling: modality imbalance via task-aware loss reweighting, visual fidelity via a lightweight token-level perceptual alignment loss for image tokens, and stability-creativity trade-offs via a finite-state decoding mechanism. Empirically, AR-Omni achieves strong quality across three modalities while remaining real-time, achieving a 0.88 real-time factor for speech generation.
Omni-R1: Towards the Unified Generative Paradigm for Multimodal Reasoning
Jan 14, 2026Multimodal Large Language Models (MLLMs) are making significant progress in multimodal reasoning. Early approaches focus on pure text-based reasoning. More recent studies have incorporated multimodal information into the reasoning steps; however, they often follow a single task-specific reasoning pattern, which limits their generalizability across various multimodal tasks. In fact, there are numerous multimodal tasks requiring diverse reasoning skills, such as zooming in on a specific region or marking an object within an image. To address this, we propose unified generative multimodal reasoning, which unifies diverse multimodal reasoning skills by generating intermediate images during the reasoning process. We instantiate this paradigm with Omni-R1, a two-stage SFT+RL framework featuring perception alignment loss and perception reward, thereby enabling functional image generation. Additionally, we introduce Omni-R1-Zero, which eliminates the need for multimodal annotations by bootstrapping step-wise visualizations from text-only reasoning data. Empirical results show that Omni-R1 achieves unified generative reasoning across a wide range of multimodal tasks, and Omni-R1-Zero can match or even surpass Omni-R1 on average, suggesting a promising direction for generative multimodal reasoning.
Controlling Multimodal Conversational Agents with Coverage-Enhanced Latent Actions
Jan 12, 2026Vision-language models are increasingly employed as multimodal conversational agents (MCAs) for diverse conversational tasks. Recently, reinforcement learning (RL) has been widely explored for adapting MCAs to various human-AI interaction scenarios. Despite showing great enhancement in generalization performance, fine-tuning MCAs via RL still faces challenges in handling the extremely large text token space. To address this, we learn a compact latent action space for RL fine-tuning instead. Specifically, we adopt the learning from observation mechanism to construct the codebook for the latent action space, where future observations are leveraged to estimate current latent actions that could further be used to reconstruct future observations. However, the scarcity of paired image-text data hinders learning a codebook with sufficient coverage. Thus, we leverage both paired image-text data and text-only data to construct the latent action space, using a cross-modal projector for transforming text embeddings into image-text embeddings. We initialize the cross-modal projector on paired image-text data, and further train it on massive text-only data with a novel cycle consistency loss to enhance its robustness. We show that our latent action based method outperforms competitive baselines on two conversation tasks across various RL algorithms.
Agent-as-a-Judge
Jan 08, 2026LLM-as-a-Judge has revolutionized AI evaluation by leveraging large language models for scalable assessments. However, as evaluands become increasingly complex, specialized, and multi-step, the reliability of LLM-as-a-Judge has become constrained by inherent biases, shallow single-pass reasoning, and the inability to verify assessments against real-world observations. This has catalyzed the transition to Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations. Despite the rapid proliferation of agentic evaluation systems, the field lacks a unified framework to navigate this shifting landscape. To bridge this gap, we present the first comprehensive survey tracing this evolution. Specifically, we identify key dimensions that characterize this paradigm shift and establish a developmental taxonomy. We organize core methodologies and survey applications across general and professional domains. Furthermore, we analyze frontier challenges and identify promising research directions, ultimately providing a clear roadmap for the next generation of agentic evaluation.
Understanding Generalization in Role-Playing Models via Information Theory
Dec 19, 2025Role-playing models (RPMs) are widely used in real-world applications but underperform when deployed in the wild. This degradation can be attributed to distribution shifts, including user, character, and dialogue compositional shifts. Existing methods like LLM-as-a-judge fall short in providing a fine-grained diagnosis of how these shifts affect RPM generalization, and thus there lack formal frameworks to characterize RPM generalization behaviors. To bridge these gaps, we introduce an information-theoretic metric, named reasoning-based effective mutual information difference (R-EMID), to measure RPM performance degradation in an interpretable way. We also derive an upper bound on R-EMID to predict the worst-case generalization performance of RPMs and theoretically reveal how various shifts contribute to the RPM performance degradation. Moreover, we propose a co-evolving reinforcement learning framework to adaptively model the connection among user, character, and dialogue context and thus enhance the estimation of dialogue response generation probability, which is critical for calculating R-EMID. Finally, we evaluate the generalization performance of various RPMs using R-EMID, finding that user shift poses the highest risk among all shifts and reinforcement learning is the most effective approach for enhancing RPM generalization.
Reasoning in the Dark: Interleaved Vision-Text Reasoning in Latent Space
Oct 14, 2025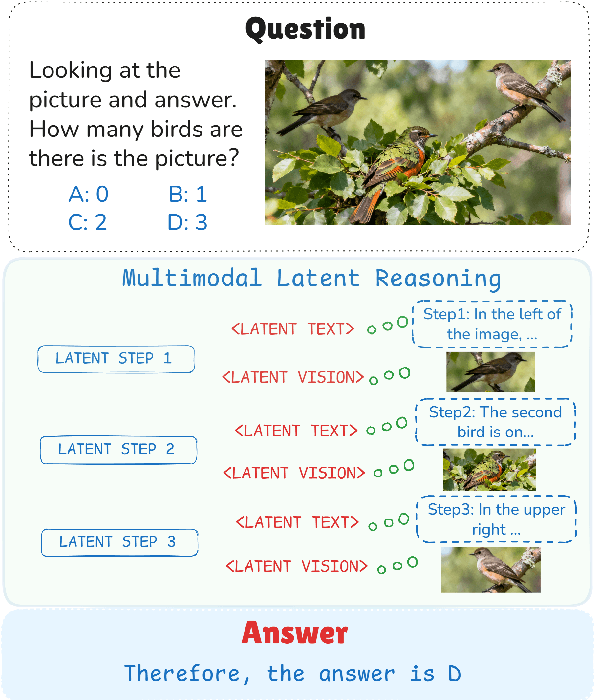
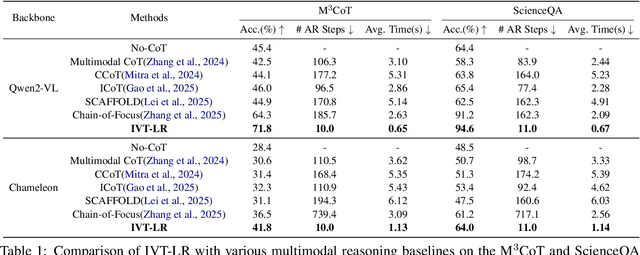
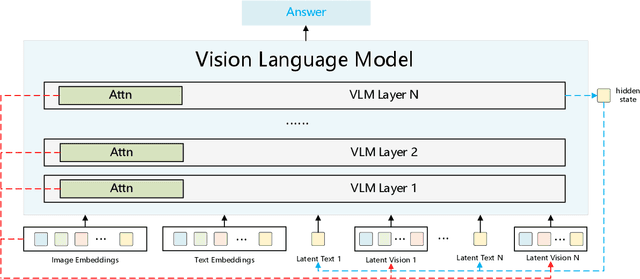
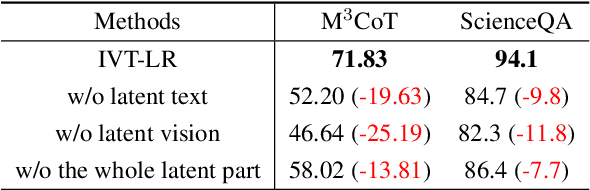
Multimodal reasoning aims to enhance the capabilities of MLLMs by incorporating intermediate reasoning steps before reaching the final answer. It has evolved from text-only reasoning to the integration of visual information, enabling the thought process to be conveyed through both images and text. Despite its effectiveness, current multimodal reasoning methods depend on explicit reasoning steps that require labor-intensive vision-text annotations and inherently introduce significant inference latency. To address these issues, we introduce multimodal latent reasoning with the advantages of multimodal representation, reduced annotation, and inference efficiency. To facilicate it, we propose Interleaved Vision-Text Latent Reasoning (IVT-LR), which injects both visual and textual information in the reasoning process within the latent space. Specifically, IVT-LR represents each reasoning step by combining two implicit parts: latent text (the hidden states from the previous step) and latent vision (a set of selected image embeddings). We further introduce a progressive multi-stage training strategy to enable MLLMs to perform the above multimodal latent reasoning steps. Experiments on M3CoT and ScienceQA demonstrate that our IVT-LR method achieves an average performance increase of 5.45% in accuracy, while simultaneously achieving a speed increase of over 5 times compared to existing approaches. Code available at https://github.com/FYYDCC/IVT-LR.
Parallel Test-Time Scaling for Latent Reasoning Models
Oct 09, 2025Parallel test-time scaling (TTS) is a pivotal approach for enhancing large language models (LLMs), typically by sampling multiple token-based chains-of-thought in parallel and aggregating outcomes through voting or search. Recent advances in latent reasoning, where intermediate reasoning unfolds in continuous vector spaces, offer a more efficient alternative to explicit Chain-of-Thought, yet whether such latent models can similarly benefit from parallel TTS remains open, mainly due to the absence of sampling mechanisms in continuous space, and the lack of probabilistic signals for advanced trajectory aggregation. \ This work enables parallel TTS for latent reasoning models by addressing the above issues. For sampling, we introduce two uncertainty-inspired stochastic strategies: Monte Carlo Dropout and Additive Gaussian Noise. For aggregation, we design a Latent Reward Model (LatentRM) trained with step-wise contrastive objective to score and guide latent reasoning. Extensive experiments and visualization analyses show that both sampling strategies scale effectively with compute and exhibit distinct exploration dynamics, while LatentRM enables effective trajectory selection. Together, our explorations open a new direction for scalable inference in continuous spaces. Code released at https://github.com/YRYangang/LatentTTS.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.