 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContiGuard: A Framework for Continual Toxicity Detection Against Evolving Evasive Perturbations
Mar 16, 2026Toxicity detection mitigates the dissemination of toxic content (e.g., hateful comments, posts, and messages within online social actions) to safeguard a healthy online social environment. However, malicious users persistently develop evasive perturbations to disguise toxic content and evade detectors. Traditional detectors or methods are static over time and are inadequate in addressing these evolving evasion tactics. Thus, continual learning emerges as a logical approach to dynamically update detection ability against evolving perturbations. Nevertheless, disparities across perturbations hinder the detector's continual learning on perturbed text. More importantly, perturbation-induced noises distort semantics to degrade comprehension and also impair critical feature learning to render detection sensitive to perturbations. These amplify the challenge of continual learning against evolving perturbations. In this work, we present ContiGuard, the first framework tailored for continual learning of the detector on time-evolving perturbed text (termed continual toxicity detection) to enable the detector to continually update capability and maintain sustained resilience against evolving perturbations. Specifically, to boost the comprehension, we present an LLM-powered semantic enriching strategy, where we dynamically incorporate possible meaning and toxicity-related clues excavated by LLM into the perturbed text to improve the comprehension. To mitigate non-critical features and amplify critical ones, we propose a discriminability-driven feature learning strategy, where we strengthen discriminative features while suppressing the less-discriminative ones to shape a robust classification boundary for detection...
What Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom
Feb 01, 2026Vision tool-use reinforcement learning (RL) can equip vision-language models with visual operators such as crop-and-zoom and achieves strong performance gains, yet it remains unclear whether these gains are driven by improvements in tool use or evolving intrinsic capabilities.We introduce MED (Measure-Explain-Diagnose), a coarse-to-fine framework that disentangles intrinsic capability changes from tool-induced effects, decomposes the tool-induced performance difference into gain and harm terms, and probes the mechanisms driving their evolution. Across checkpoint-level analyses on two VLMs with different tool priors and six benchmarks, we find that improvements are dominated by intrinsic learning, while tool-use RL mainly reduces tool-induced harm (e.g., fewer call-induced errors and weaker tool schema interference) and yields limited progress in tool-based correction of intrinsic failures. Overall, current vision tool-use RL learns to coexist safely with tools rather than master them.
Uni-RS: A Spatially Faithful Unified Understanding and Generation Model for Remote Sensing
Jan 25, 2026Unified remote sensing multimodal models exhibit a pronounced spatial reversal curse: Although they can accurately recognize and describe object locations in images, they often fail to faithfully execute the same spatial relations during text-to-image generation, where such relations constitute core semantic information in remote sensing. Motivated by this observation, we propose Uni-RS, the first unified multimodal model tailored for remote sensing, to explicitly address the spatial asymmetry between understanding and generation. Specifically, we first introduce explicit Spatial-Layout Planning to transform textual instructions into spatial layout plans, decoupling geometric planning from visual synthesis. We then impose Spatial-Aware Query Supervision to bias learnable queries toward spatial relations explicitly specified in the instruction. Finally, we develop Image-Caption Spatial Layout Variation to expose the model to systematic geometry-consistent spatial transformations. Extensive experiments across multiple benchmarks show that our approach substantially improves spatial faithfulness in text-to-image generation, while maintaining strong performance on multimodal understanding tasks like image captioning, visual grounding, and VQA tasks.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
A Gravity-informed Spatiotemporal Transformer for Human Activity Intensity Prediction
Jun 16, 2025Human activity intensity prediction is a crucial to many location-based services. Although tremendous progress has been made to model dynamic spatiotemporal patterns of human activity, most existing methods, including spatiotemporal graph neural networks (ST-GNNs), overlook physical constraints of spatial interactions and the over-smoothing phenomenon in spatial correlation modeling. To address these limitations, this work proposes a physics-informed deep learning framework, namely Gravity-informed Spatiotemporal Transformer (Gravityformer) by refining transformer attention to integrate the universal law of gravitation and explicitly incorporating constraints from spatial interactions. Specifically, it (1) estimates two spatially explicit mass parameters based on inflow and outflow, (2) models the likelihood of cross-unit interaction using closed-form solutions of spatial interactions to constrain spatial modeling randomness, and (3) utilizes the learned spatial interaction to guide and mitigate the over-smoothing phenomenon in transformer attention matrices. The underlying law of human activity can be explicitly modeled by the proposed adaptive gravity model. Moreover, a parallel spatiotemporal graph convolution transformer structure is proposed for achieving a balance between coupled spatial and temporal learning. Systematic experiments on six real-world large-scale activity datasets demonstrate the quantitative and qualitative superiority of our approach over state-of-the-art benchmarks. Additionally, the learned gravity attention matrix can be disentangled and interpreted based on geographical laws. This work provides a novel insight into integrating physical laws with deep learning for spatiotemporal predictive learning.
SRLCG: Self-Rectified Large-Scale Code Generation with Multidimensional Chain-of-Thought and Dynamic Backtracking
Apr 01, 2025Large language models (LLMs) have revolutionized code generation, significantly enhancing developer productivity. However, for a vast number of users with minimal coding knowledge, LLMs provide little support, as they primarily generate isolated code snippets rather than complete, large-scale project code. Without coding expertise, these users struggle to interpret, modify, and iteratively refine the outputs of LLMs, making it impossible to assemble a complete project. To address this issue, we propose Self-Rectified Large-Scale Code Generator (SRLCG), a framework that generates complete multi-file project code from a single prompt. SRLCG employs a novel multidimensional chain-of-thought (CoT) and self-rectification to guide LLMs in generating correct and robust code files, then integrates them into a complete and coherent project using our proposed dynamic backtracking algorithm. Experimental results show that SRLCG generates code 15x longer than DeepSeek-V3, 16x longer than GPT-4, and at least 10x longer than other leading CoT-based baselines. Furthermore, they confirm its improved correctness, robustness, and performance compared to baselines in large-scale code generation.
Data driven discovery of human mobility models
Jan 10, 2025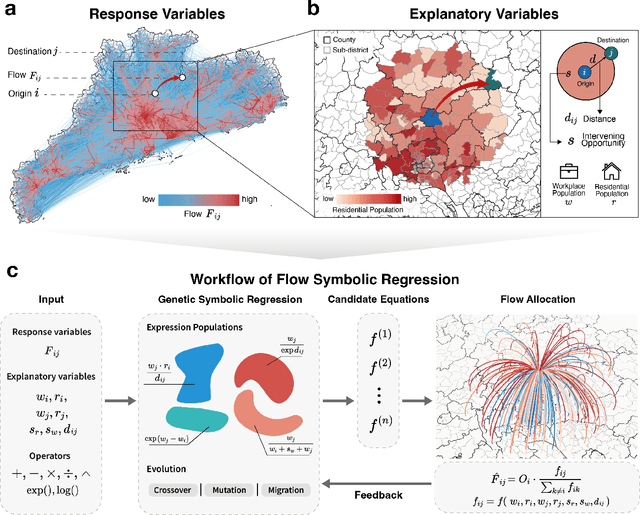
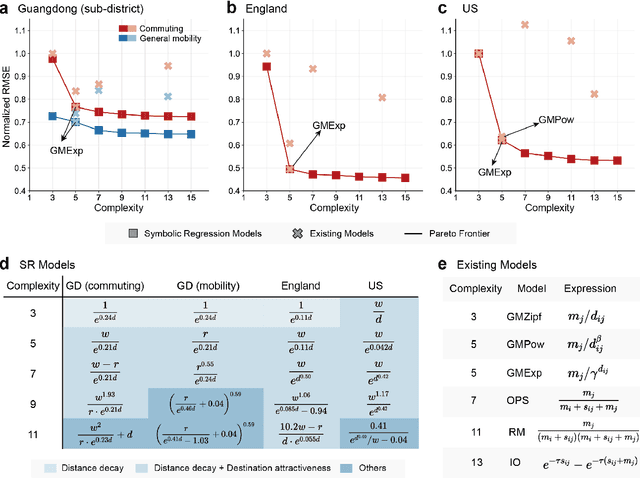
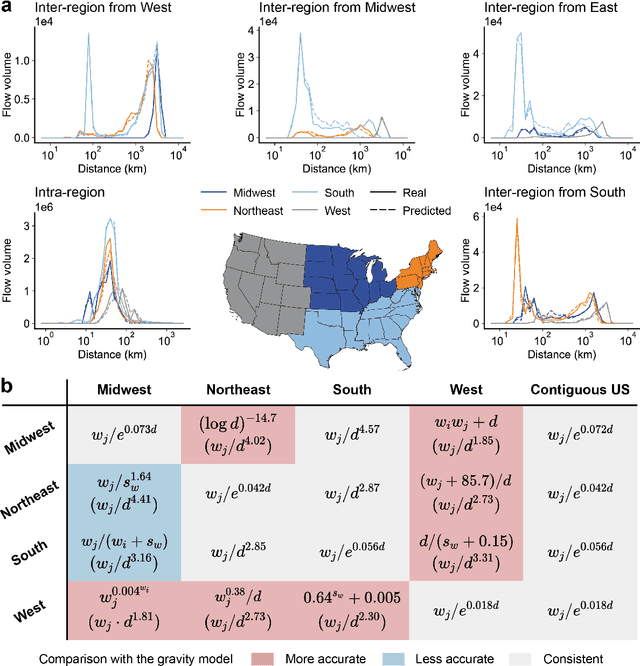
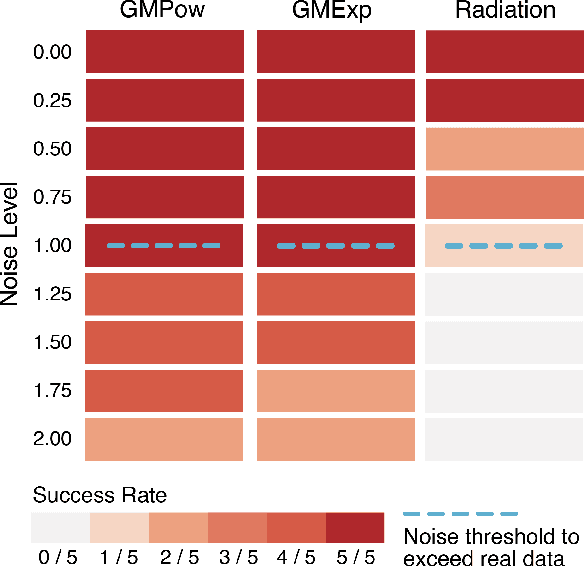
Human mobility is a fundamental aspect of social behavior, with broad applications in transportation, urban planning, and epidemic modeling. However, for decades new mathematical formulas to model mobility phenomena have been scarce and usually discovered by analogy to physical processes, such as the gravity model and the radiation model. These sporadic discoveries are often thought to rely on intuition and luck in fitting empirical data. Here, we propose a systematic approach that leverages symbolic regression to automatically discover interpretable models from human mobility data. Our approach finds several well-known formulas, such as the distance decay effect and classical gravity models, as well as previously unknown ones, such as an exponential-power-law decay that can be explained by the maximum entropy principle. By relaxing the constraints on the complexity of model expressions, we further show how key variables of human mobility are progressively incorporated into the model, making this framework a powerful tool for revealing the underlying mathematical structures of complex social phenomena directly from observational data.
BianCang: A Traditional Chinese Medicine Large Language Model
Nov 17, 2024



The rise of large language models (LLMs) has driven significant progress in medical applications, including traditional Chinese medicine (TCM). However, current medical LLMs struggle with TCM diagnosis and syndrome differentiation due to substantial differences between TCM and modern medical theory, and the scarcity of specialized, high-quality corpora. This paper addresses these challenges by proposing BianCang, a TCM-specific LLM, using a two-stage training process that first injects domain-specific knowledge and then aligns it through targeted stimulation. To enhance diagnostic and differentiation capabilities, we constructed pre-training corpora, instruction-aligned datasets based on real hospital records, and the ChP-TCM dataset derived from the Pharmacopoeia of the People's Republic of China. We compiled extensive TCM and medical corpora for continuous pre-training and supervised fine-tuning, building a comprehensive dataset to refine the model's understanding of TCM. Evaluations across 11 test sets involving 29 models and 4 tasks demonstrate the effectiveness of BianCang, offering valuable insights for future research. Code, datasets, and models are available at https://github.com/QLU-NLP/BianCang.
Medical Question Summarization with Entity-driven Contrastive Learning
Apr 15, 2023By summarizing longer consumer health questions into shorter and essential ones, medical question answering (MQA) systems can more accurately understand consumer intentions and retrieve suitable answers. However, medical question summarization is very challenging due to obvious distinctions in health trouble descriptions from patients and doctors. Although existing works have attempted to utilize Seq2Seq, reinforcement learning, or contrastive learning to solve the problem, two challenges remain: how to correctly capture question focus to model its semantic intention, and how to obtain reliable datasets to fairly evaluate performance. To address these challenges, this paper proposes a novel medical question summarization framework using entity-driven contrastive learning (ECL). ECL employs medical entities in frequently asked questions (FAQs) as focuses and devises an effective mechanism to generate hard negative samples. This approach forces models to pay attention to the crucial focus information and generate more ideal question summarization. Additionally, we find that some MQA datasets suffer from serious data leakage problems, such as the iCliniq dataset's 33% duplicate rate. To evaluate the related methods fairly, this paper carefully checks leaked samples to reorganize more reasonable datasets. Extensive experiments demonstrate that our ECL method outperforms state-of-the-art methods by accurately capturing question focus and generating medical question summaries. The code and datasets are available at https://github.com/yrbobo/MQS-ECL.
Learning Node Representations from Noisy Graph Structures
Dec 04, 2020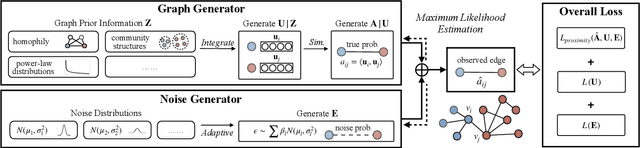
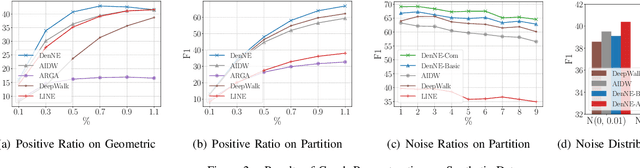
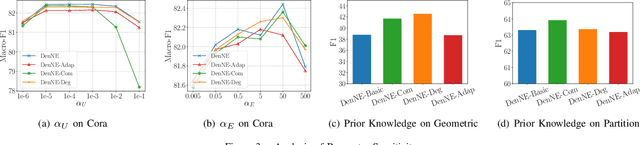
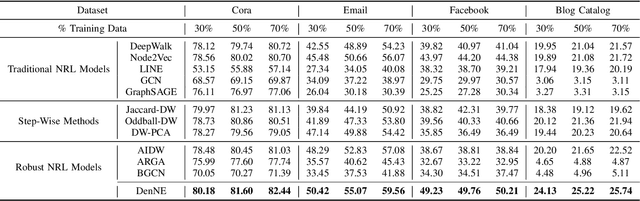
Learning low-dimensional representations on graphs has proved to be effective in various downstream tasks. However, noises prevail in real-world networks, which compromise networks to a large extent in that edges in networks propagate noises through the whole network instead of only the node itself. While existing methods tend to focus on preserving structural properties, the robustness of the learned representations against noises is generally ignored. In this paper, we propose a novel framework to learn noise-free node representations and eliminate noises simultaneously. Since noises are often unknown on real graphs, we design two generators, namely a graph generator and a noise generator, to identify normal structures and noises in an unsupervised setting. On the one hand, the graph generator serves as a unified scheme to incorporate any useful graph prior knowledge to generate normal structures. We illustrate the generative process with community structures and power-law degree distributions as examples. On the other hand, the noise generator generates graph noises not only satisfying some fundamental properties but also in an adaptive way. Thus, real noises with arbitrary distributions can be handled successfully. Finally, in order to eliminate noises and obtain noise-free node representations, two generators need to be optimized jointly, and through maximum likelihood estimation, we equivalently convert the model into imposing different regularization constraints on the true graph and noises respectively. Our model is evaluated on both real-world and synthetic data. It outperforms other strong baselines for node classification and graph reconstruction tasks, demonstrating its ability to eliminate graph noises.