 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forecast After the Forecast: A Post-Processing Shift in Time Series
Jan 28, 2026Time series forecasting has long been dominated by advances in model architecture, with recent progress driven by deep learning and hybrid statistical techniques. However, as forecasting models approach diminishing returns in accuracy, a critical yet underexplored opportunity emerges: the strategic use of post-processing. In this paper, we address the last-mile gap in time-series forecasting, which is to improve accuracy and uncertainty without retraining or modifying a deployed backbone. We propose $δ$-Adapter, a lightweight, architecture-agnostic way to boost deployed time series forecasters without retraining. $δ$-Adapter learns tiny, bounded modules at two interfaces: input nudging (soft edits to covariates) and output residual correction. We provide local descent guarantees, $O(δ)$ drift bounds, and compositional stability for combined adapters. Meanwhile, it can act as a feature selector by learning a sparse, horizon-aware mask over inputs to select important features, thereby improving interpretability. In addition, it can also be used as a distribution calibrator to measure uncertainty. Thus, we introduce a Quantile Calibrator and a Conformal Corrector that together deliver calibrated, personalized intervals with finite-sample coverage. Our experiments across diverse backbones and datasets show that $δ$-Adapter improves accuracy and calibration with negligible compute and no interface changes.
* 30 Pages
DeepBooTS: Dual-Stream Residual Boosting for Drift-Resilient Time-Series Forecasting
Nov 10, 2025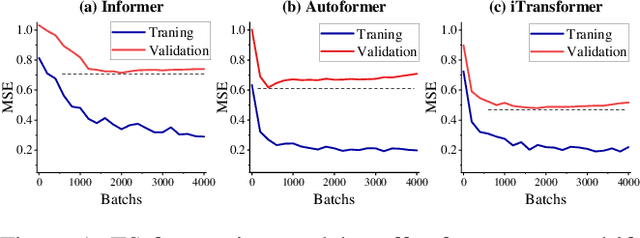
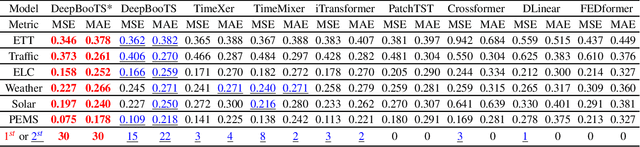
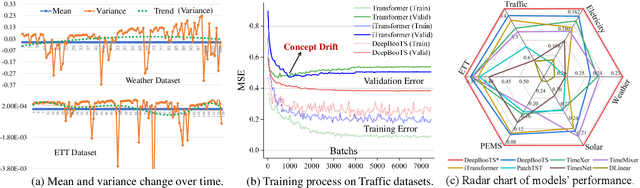
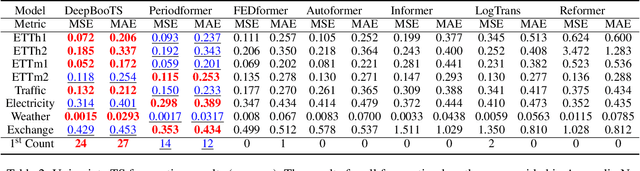
Time-Series (TS) exhibits pronounced non-stationarity. Consequently, most forecasting methods display compromised robustness to concept drift, despite the prevalent application of instance normalization. We tackle this challenge by first analysing concept drift through a bias-variance lens and proving that weighted ensemble reduces variance without increasing bias. These insights motivate DeepBooTS, a novel end-to-end dual-stream residual-decreasing boosting method that progressively reconstructs the intrinsic signal. In our design, each block of a deep model becomes an ensemble of learners with an auxiliary output branch forming a highway to the final prediction. The block-wise outputs correct the residuals of previous blocks, leading to a learning-driven decomposition of both inputs and targets. This method enhances versatility and interpretability while substantially improving robustness to concept drift. Extensive experiments, including those on large-scale datasets, show that the proposed method outperforms existing methods by a large margin, yielding an average performance improvement of 15.8% across various datasets, establishing a new benchmark for TS forecasting.
NullSwap: Proactive Identity Cloaking Against Deepfake Face Swapping
Mar 24, 2025Suffering from performance bottlenecks in passively detecting high-quality Deepfake images due to the advancement of generative models, proactive perturbations offer a promising approach to disabling Deepfake manipulations by inserting signals into benign images. However, existing proactive perturbation approaches remain unsatisfactory in several aspects: 1) visual degradation due to direct element-wise addition; 2) limited effectiveness against face swapping manipulation; 3) unavoidable reliance on white- and grey-box settings to involve generative models during training. In this study, we analyze the essence of Deepfake face swapping and argue the necessity of protecting source identities rather than target images, and we propose NullSwap, a novel proactive defense approach that cloaks source image identities and nullifies face swapping under a pure black-box scenario. We design an Identity Extraction module to obtain facial identity features from the source image, while a Perturbation Block is then devised to generate identity-guided perturbations accordingly. Meanwhile, a Feature Block extracts shallow-level image features, which are then fused with the perturbation in the Cloaking Block for image reconstruction. Furthermore, to ensure adaptability across different identity extractors in face swapping algorithms, we propose Dynamic Loss Weighting to adaptively balance identity losses. Experiments demonstrate the outstanding ability of our approach to fool various identity recognition models, outperforming state-of-the-art proactive perturbations in preventing face swapping models from generating images with correct source identities.
BianCang: A Traditional Chinese Medicine Large Language Model
Nov 17, 2024



The rise of large language models (LLMs) has driven significant progress in medical applications, including traditional Chinese medicine (TCM). However, current medical LLMs struggle with TCM diagnosis and syndrome differentiation due to substantial differences between TCM and modern medical theory, and the scarcity of specialized, high-quality corpora. This paper addresses these challenges by proposing BianCang, a TCM-specific LLM, using a two-stage training process that first injects domain-specific knowledge and then aligns it through targeted stimulation. To enhance diagnostic and differentiation capabilities, we constructed pre-training corpora, instruction-aligned datasets based on real hospital records, and the ChP-TCM dataset derived from the Pharmacopoeia of the People's Republic of China. We compiled extensive TCM and medical corpora for continuous pre-training and supervised fine-tuning, building a comprehensive dataset to refine the model's understanding of TCM. Evaluations across 11 test sets involving 29 models and 4 tasks demonstrate the effectiveness of BianCang, offering valuable insights for future research. Code, datasets, and models are available at https://github.com/QLU-NLP/BianCang.
Robust Identity Perceptual Watermark Against Deepfake Face Swapping
Nov 02, 2023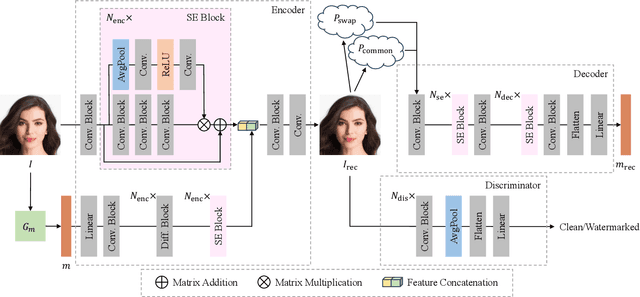
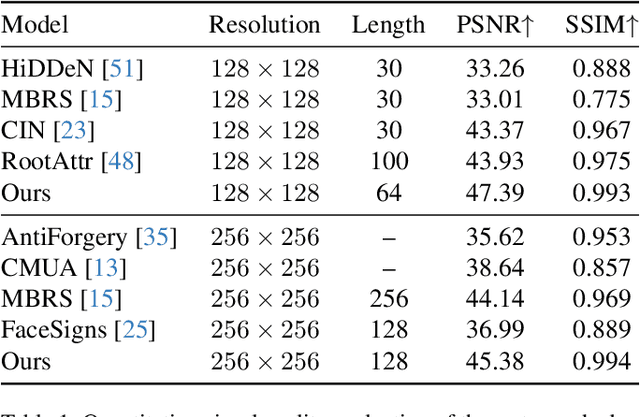

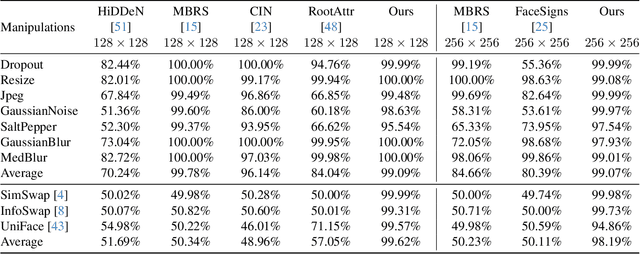
Notwithstanding offering convenience and entertainment to society, Deepfake face swapping has caused critical privacy issues with the rapid development of deep generative models. Due to imperceptible artifacts in high-quality synthetic images, passive detection models against face swapping in recent years usually suffer performance damping regarding the generalizability issue. Therefore, several studies have been attempted to proactively protect the original images against malicious manipulations by inserting invisible signals in advance. However, the existing proactive defense approaches demonstrate unsatisfactory results with respect to visual quality, detection accuracy, and source tracing ability. In this study, we propose the first robust identity perceptual watermarking framework that concurrently performs detection and source tracing against Deepfake face swapping proactively. We assign identity semantics regarding the image contents to the watermarks and devise an unpredictable and unreversible chaotic encryption system to ensure watermark confidentiality. The watermarks are encoded and recovered by jointly training an encoder-decoder framework along with adversarial image manipulations. Extensive experiments demonstrate state-of-the-art performance against Deepfake face swapping under both cross-dataset and cross-manipulation settings.
Low-Light Image Enhancement with Illumination-Aware Gamma Correction and Complete Image Modelling Network
Aug 16, 2023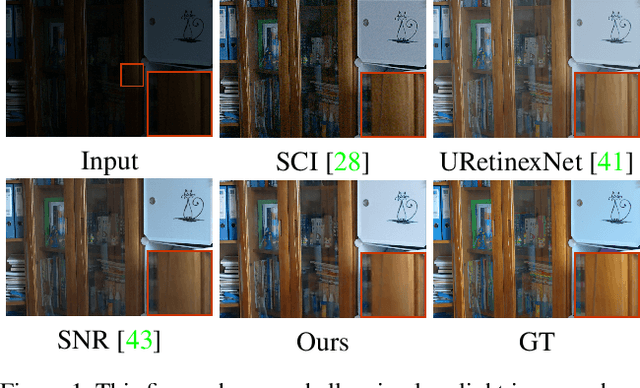

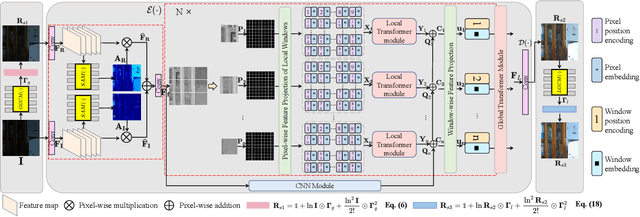
This paper presents a novel network structure with illumination-aware gamma correction and complete image modelling to solve the low-light image enhancement problem. Low-light environments usually lead to less informative large-scale dark areas, directly learning deep representations from low-light images is insensitive to recovering normal illumination. We propose to integrate the effectiveness of gamma correction with the strong modelling capacities of deep networks, which enables the correction factor gamma to be learned in a coarse to elaborate manner via adaptively perceiving the deviated illumination. Because exponential operation introduces high computational complexity, we propose to use Taylor Series to approximate gamma correction, accelerating the training and inference speed. Dark areas usually occupy large scales in low-light images, common local modelling structures, e.g., CNN, SwinIR, are thus insufficient to recover accurate illumination across whole low-light images. We propose a novel Transformer block to completely simulate the dependencies of all pixels across images via a local-to-global hierarchical attention mechanism, so that dark areas could be inferred by borrowing the information from far informative regions in a highly effective manner. Extensive experiments on several benchmark datasets demonstrate that our approach outperforms state-of-the-art methods.
Deepfake Detection: A Comprehensive Study from the Reliability Perspective
Nov 20, 2022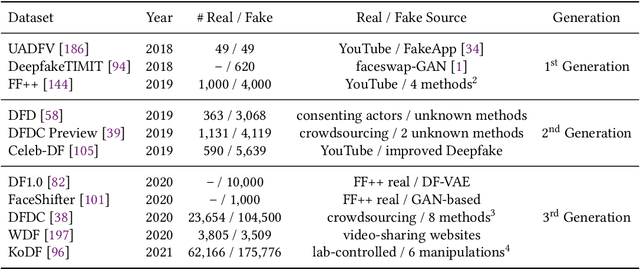
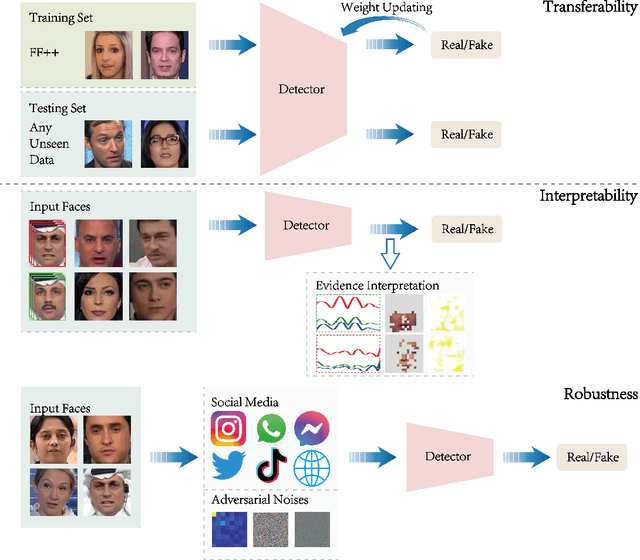
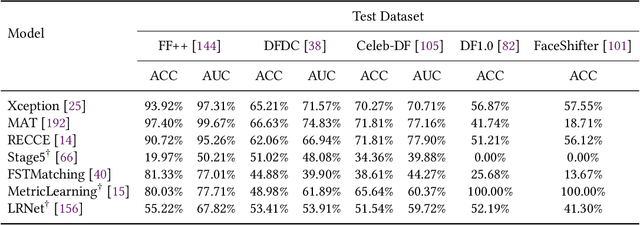

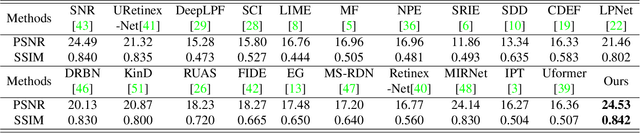
The mushroomed Deepfake synthetic materials circulated on the internet have raised serious social impact to politicians, celebrities, and every human being on earth. In this paper, we provide a thorough review of the existing models following the development history of the Deepfake detection studies and define the research challenges of Deepfake detection in three aspects, namely, transferability, interpretability, and reliability. While the transferability and interpretability challenges have both been frequently discussed and attempted to solve with quantitative evaluations, the reliability issue has been barely considered, leading to the lack of reliable evidence in real-life usages and even for prosecutions on Deepfake related cases in court. We therefore conduct a model reliability study scheme using statistical random sampling knowledge and the publicly available benchmark datasets to qualitatively validate the detection performance of the existing models on arbitrary Deepfake candidate suspects. A barely remarked systematic data pre-processing procedure is demonstrated along with the fair training and testing experiments on the existing detection models. Case studies are further executed to justify the real-life Deepfake cases including different groups of victims with the help of reliably qualified detection models. The model reliability study provides a workflow for the detection models to act as or assist evidence for Deepfake forensic investigation in court once approved by authentication experts or institutions.
Removing Rain Streaks via Task Transfer Learning
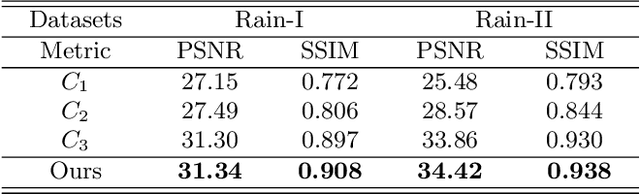
Aug 28, 2022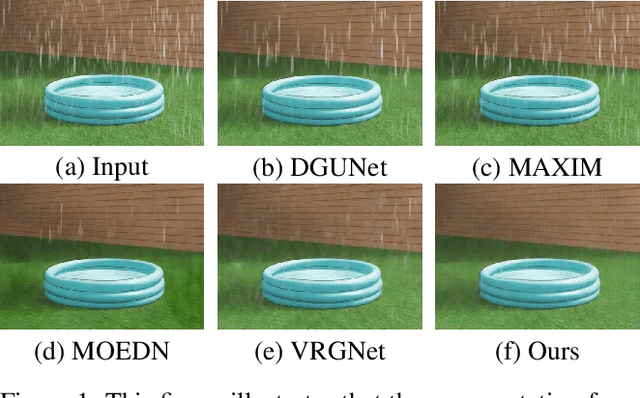
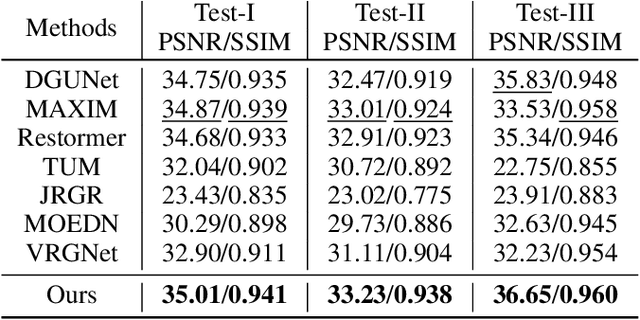


Due to the difficulty in collecting paired real-world training data, image deraining is currently dominated by supervised learning with synthesized data generated by e.g., Photoshop rendering. However, the generalization to real rainy scenes is usually limited due to the gap between synthetic and real-world data. In this paper, we first statistically explore why the supervised deraining models cannot generalize well to real rainy cases, and find the substantial difference of synthetic and real rainy data. Inspired by our studies, we propose to remove rain by learning favorable deraining representations from other connected tasks. In connected tasks, the label for real data can be easily obtained. Hence, our core idea is to learn representations from real data through task transfer to improve deraining generalization. We thus term our learning strategy as \textit{task transfer learning}. If there are more than one connected tasks, we propose to reduce model size by knowledge distillation. The pretrained models for the connected tasks are treated as teachers, all their knowledge is distilled to a student network, so that we reduce the model size, meanwhile preserve effective prior representations from all the connected tasks. At last, the student network is fine-tuned with minority of paired synthetic rainy data to guide the pretrained prior representations to remove rain. Extensive experiments demonstrate that proposed task transfer learning strategy is surprisingly successful and compares favorably with state-of-the-art supervised learning methods and apparently surpass other semi-supervised deraining methods on synthetic data. Particularly, it shows superior generalization over them to real-world scenes.
Ghost-free High Dynamic Range Imaging with Context-aware Transformer
Aug 10, 2022



High dynamic range (HDR) deghosting algorithms aim to generate ghost-free HDR images with realistic details. Restricted by the locality of the receptive field, existing CNN-based methods are typically prone to producing ghosting artifacts and intensity distortions in the presence of large motion and severe saturation. In this paper, we propose a novel Context-Aware Vision Transformer (CA-ViT) for ghost-free high dynamic range imaging. The CA-ViT is designed as a dual-branch architecture, which can jointly capture both global and local dependencies. Specifically, the global branch employs a window-based Transformer encoder to model long-range object movements and intensity variations to solve ghosting. For the local branch, we design a local context extractor (LCE) to capture short-range image features and use the channel attention mechanism to select informative local details across the extracted features to complement the global branch. By incorporating the CA-ViT as basic components, we further build the HDR-Transformer, a hierarchical network to reconstruct high-quality ghost-free HDR images. Extensive experiments on three benchmark datasets show that our approach outperforms state-of-the-art methods qualitatively and quantitatively with considerably reduced computational budgets. Codes are available at https://github.com/megvii-research/HDR-Transformer
Rethinking Image Deraining via Rain Streaks and Vapors
Aug 03, 2020
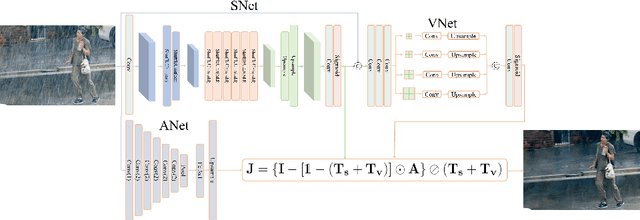

Single image deraining regards an input image as a fusion of a background image, a transmission map, rain streaks, and atmosphere light. While advanced models are proposed for image restoration (i.e., background image generation), they regard rain streaks with the same properties as background rather than transmission medium. As vapors (i.e., rain streaks accumulation or fog-like rain) are conveyed in the transmission map to model the veiling effect, the fusion of rain streaks and vapors do not naturally reflect the rain image formation. In this work, we reformulate rain streaks as transmission medium together with vapors to model rain imaging. We propose an encoder-decoder CNN named as SNet to learn the transmission map of rain streaks. As rain streaks appear with various shapes and directions, we use ShuffleNet units within SNet to capture their anisotropic representations. As vapors are brought by rain streaks, we propose a VNet containing spatial pyramid pooling (SSP) to predict the transmission map of vapors in multi-scales based on that of rain streaks. Meanwhile, we use an encoder CNN named ANet to estimate atmosphere light. The SNet, VNet, and ANet are jointly trained to predict transmission maps and atmosphere light for rain image restoration. Extensive experiments on the benchmark datasets demonstrate the effectiveness of the proposed visual model to predict rain streaks and vapors. The proposed deraining method performs favorably against state-of-the-art deraining approaches.