 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$: Dual-Memory Augmentation for Long-Horizon Web Agents via Trajectory Summarization and Insight Retrieval
Feb 28, 2026Multimodal Large Language Models (MLLMs) based agents have demonstrated remarkable potential in autonomous web navigation. However, handling long-horizon tasks remains a critical bottleneck. Prevailing strategies often rely heavily on extensive data collection and model training, yet still struggle with high computational costs and insufficient reasoning capabilities when facing complex, long-horizon scenarios. To address this, we propose M$^2$, a training-free, memory-augmented framework designed to optimize context efficiency and decision-making robustness. Our approach incorporates a dual-tier memory mechanism that synergizes Dynamic Trajectory Summarization (Internal Memory) to compress verbose interaction history into concise state updates, and Insight Retrieval Augmentation (External Memory) to guide the agent with actionable guidelines retrieved from an offline insight bank. Extensive evaluations across WebVoyager and OnlineMind2Web demonstrate that M$^2$ consistently surpasses baselines, yielding up to a 19.6% success rate increase and 58.7% token reduction for Qwen3-VL-32B, while proprietary models like Claude achieve accuracy gains up to 12.5% alongside significantly lower computational overhead.
Open-Text Aerial Detection: A Unified Framework For Aerial Visual Grounding And Detection
Feb 08, 2026Open-Vocabulary Aerial Detection (OVAD) and Remote Sensing Visual Grounding (RSVG) have emerged as two key paradigms for aerial scene understanding. However, each paradigm suffers from inherent limitations when operating in isolation: OVAD is restricted to coarse category-level semantics, while RSVG is structurally limited to single-target localization. These limitations prevent existing methods from simultaneously supporting rich semantic understanding and multi-target detection. To address this, we propose OTA-Det, the first unified framework that bridges both paradigms into a cohesive architecture. Specifically, we introduce a task reformulation strategy that unifies task objectives and supervision mechanisms, enabling joint training across datasets from both paradigms with dense supervision signals. Furthermore, we propose a dense semantic alignment strategy that establishes explicit correspondence at multiple granularities, from holistic expressions to individual attributes, enabling fine-grained semantic understanding. To ensure real-time efficiency, OTA-Det builds upon the RT-DETR architecture, extending it from closed-set detection to open-text detection by introducing several high efficient modules, achieving state-of-the-art performance on six benchmarks spanning both OVAD and RSVG tasks while maintaining real-time inference at 34 FPS.
Rethinking Practical and Efficient Quantization Calibration for Vision-Language Models
Feb 08, 2026Post-training quantization (PTQ) is a primary approach for deploying large language models without fine-tuning, and the quantized performance is often strongly affected by the calibration in PTQ. By contrast, in vision-language models (VLMs), substantial differences between visual and text tokens in their activation distributions and sensitivities to quantization error pose significant challenges for effective calibration during PTQ. In this work, we rethink what PTQ calibration should align with in VLMs and propose the Token-level Importance-aware Layer-wise Quantization framework (TLQ). Guided by gradient information, we design a token-level importance integration mechanism for quantization error, and use it to construct a token-level calibration set, enabling a more fine-grained calibration strategy. Furthermore, TLQ introduces a multi-GPU, quantization-exposed layer-wise calibration scheme. This scheme keeps the layer-wise calibration procedure consistent with the true quantized inference path and distributes the complex layer-wise calibration workload across multiple RTX3090 GPUs, thereby reducing reliance on the large memory of A100 GPUs. TLQ is evaluated across two models, three model scales, and two quantization settings, consistently achieving performance improvements across all settings, indicating its strong quantization stability. The code will be released publicly.
Unlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
PIO-FVLM: Rethinking Training-Free Visual Token Reduction for VLM Acceleration from an Inference-Objective Perspective
Feb 05, 2026Recently, reducing redundant visual tokens in vision-language models (VLMs) to accelerate VLM inference has emerged as a hot topic. However, most existing methods rely on heuristics constructed based on inter-visual-token similarity or cross-modal visual-text similarity, which gives rise to certain limitations in compression performance and practical deployment. In contrast, we propose PIO-FVLM from the perspective of inference objectives, which transforms visual token compression into preserving output result invariance and selects tokens primarily by their importance to this goal. Specially, vision tokens are reordered with the guidance of token-level gradient saliency generated by our designed layer-local proxy loss, a coarse constraint from the current layer to the final result. Then the most valuable vision tokens are selected following the non-maximum suppression (NMS) principle. The proposed PIO-FVLM is training-free and compatible with FlashAttention, friendly to practical application and deployment. It can be deployed independently as an encoder-free method, or combined with encoder compression approaches like VisionZip for use as an encoder-involved method. On LLaVA-Next-7B, PIO-FVLM retains just 11.1% of visual tokens but maintains 97.2% of the original performance, with a 2.67$\times$ prefill speedup, 2.11$\times$ inference speedup, 6.22$\times$ lower FLOPs, and 6.05$\times$ reduced KV Cache overhead. Our code is available at https://github.com/ocy1/PIO-FVLM.
SALAD-Pan: Sensor-Agnostic Latent Adaptive Diffusion for Pan-Sharpening
Feb 04, 2026Recently, diffusion models bring novel insights for Pan-sharpening and notably boost fusion precision. However, most existing models perform diffusion in the pixel space and train distinct models for different multispectral (MS) imagery, suffering from high latency and sensor-specific limitations. In this paper, we present SALAD-Pan, a sensor-agnostic latent space diffusion method for efficient pansharpening. Specifically, SALAD-Pan trains a band-wise single-channel VAE to encode high-resolution multispectral (HRMS) into compact latent representations, supporting MS images with various channel counts and establishing a basis for acceleration. Then spectral physical properties, along with PAN and MS images, are injected into the diffusion backbone through unidirectional and bidirectional interactive control structures respectively, achieving high-precision fusion in the diffusion process. Finally, a lightweight cross-spectral attention module is added to the central layer of diffusion model, reinforcing spectral connections to boost spectral consistency and further elevate fusion precision. Experimental results on GaoFen-2, QuickBird, and WorldView-3 demonstrate that SALAD-Pan outperforms state-of-the-art diffusion-based methods across all three datasets, attains a 2-3x inference speedup, and exhibits robust zero-shot (cross-sensor) capability.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025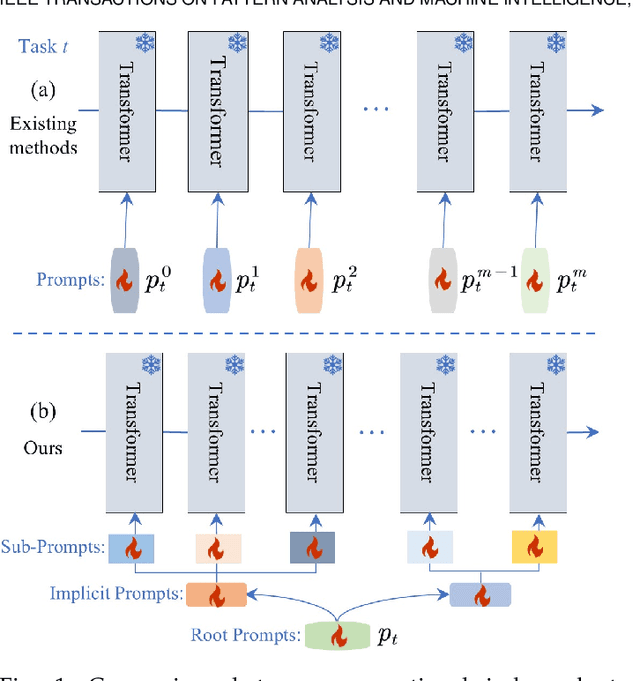
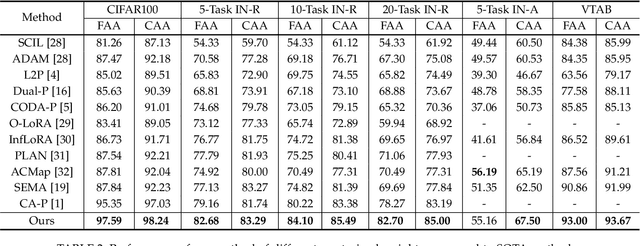
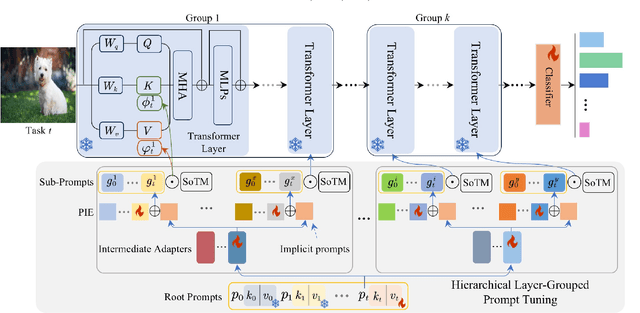
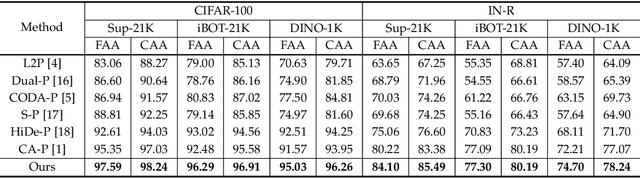
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.
UVLM: Benchmarking Video Language Model for Underwater World Understanding
Jul 03, 2025Recently, the remarkable success of large language models (LLMs) has achieved a profound impact on the field of artificial intelligence. Numerous advanced works based on LLMs have been proposed and applied in various scenarios. Among them, video language models (VidLMs) are particularly widely used. However, existing works primarily focus on terrestrial scenarios, overlooking the highly demanding application needs of underwater observation. To overcome this gap, we introduce UVLM, an under water observation benchmark which is build through a collaborative approach combining human expertise and AI models. To ensure data quality, we have conducted in-depth considerations from multiple perspectives. First, to address the unique challenges of underwater environments, we selected videos that represent typical underwater challenges including light variations, water turbidity, and diverse viewing angles to construct the dataset. Second, to ensure data diversity, the dataset covers a wide range of frame rates, resolutions, 419 classes of marine animals, and various static plants and terrains. Next, for task diversity, we adopted a structured design where observation targets are categorized into two major classes: biological and environmental. Each category includes content observation and change/action observation, totaling 20 distinct task types. Finally, we designed several challenging evaluation metrics to enable quantitative comparison and analysis of different methods. Experiments on two representative VidLMs demonstrate that fine-tuning VidLMs on UVLM significantly improves underwater world understanding while also showing potential for slight improvements on existing in-air VidLM benchmarks, such as VideoMME and Perception text. The dataset and prompt engineering will be released publicly.
NN-Former: Rethinking Graph Structure in Neural Architecture Representation
Jul 01, 2025
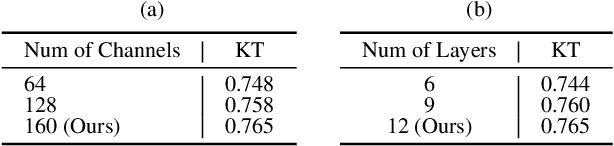
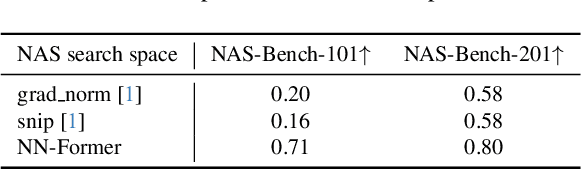
The growing use of deep learning necessitates efficient network design and deployment, making neural predictors vital for estimating attributes such as accuracy and latency. Recently, Graph Neural Networks (GNNs) and transformers have shown promising performance in representing neural architectures. However, each of both methods has its disadvantages. GNNs lack the capabilities to represent complicated features, while transformers face poor generalization when the depth of architecture grows. To mitigate the above issues, we rethink neural architecture topology and show that sibling nodes are pivotal while overlooked in previous research. We thus propose a novel predictor leveraging the strengths of GNNs and transformers to learn the enhanced topology. We introduce a novel token mixer that considers siblings, and a new channel mixer named bidirectional graph isomorphism feed-forward network. Our approach consistently achieves promising performance in both accuracy and latency prediction, providing valuable insights for learning Directed Acyclic Graph (DAG) topology. The code is available at https://github.com/XuRuihan/NNFormer.
Language Embedding Meets Dynamic Graph: A New Exploration for Neural Architecture Representation Learning
Jun 09, 2025Neural Architecture Representation Learning aims to transform network models into feature representations for predicting network attributes, playing a crucial role in deploying and designing networks for real-world applications. Recently, inspired by the success of transformers, transformer-based models integrated with Graph Neural Networks (GNNs) have achieved significant progress in representation learning. However, current methods still have some limitations. First, existing methods overlook hardware attribute information, which conflicts with the current trend of diversified deep learning hardware and limits the practical applicability of models. Second, current encoding approaches rely on static adjacency matrices to represent topological structures, failing to capture the structural differences between computational nodes, which ultimately compromises encoding effectiveness. In this paper, we introduce LeDG-Former, an innovative framework that addresses these limitations through the synergistic integration of language-based semantic embedding and dynamic graph representation learning. Specifically, inspired by large language models (LLMs), we propose a language embedding framework where both neural architectures and hardware platform specifications are projected into a unified semantic space through tokenization and LLM processing, enabling zero-shot prediction across different hardware platforms for the first time. Then, we propose a dynamic graph-based transformer for modeling neural architectures, resulting in improved neural architecture modeling performance. On the NNLQP benchmark, LeDG-Former surpasses previous methods, establishing a new SOTA while demonstrating the first successful cross-hardware latency prediction capability. Furthermore, our framework achieves superior performance on the cell-structured NAS-Bench-101 and NAS-Bench-201 datasets.