 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Word to Sentence: A Large-Scale Multi-Instance Dataset for Open-Set Aerial Detection
May 06, 2025In recent years, language-guided open-world aerial object detection has gained significant attention due to its better alignment with real-world application needs. However, due to limited datasets, most existing language-guided methods primarily focus on vocabulary, which fails to meet the demands of more fine-grained open-world detection. To address this limitation, we propose constructing a large-scale language-guided open-set aerial detection dataset, encompassing three levels of language guidance: from words to phrases, and ultimately to sentences. Centered around an open-source large vision-language model and integrating image-operation-based preprocessing with BERT-based postprocessing, we present the OS-W2S Label Engine, an automatic annotation pipeline capable of handling diverse scene annotations for aerial images. Using this label engine, we expand existing aerial detection datasets with rich textual annotations and construct a novel benchmark dataset, called Multi-instance Open-set Aerial Dataset (MI-OAD), addressing the limitations of current remote sensing grounding data and enabling effective open-set aerial detection. Specifically, MI-OAD contains 163,023 images and 2 million image-caption pairs, approximately 40 times larger than comparable datasets. We also employ state-of-the-art open-set methods from the natural image domain, trained on our proposed dataset, to validate the model's open-set detection capabilities. For instance, when trained on our dataset, Grounding DINO achieves improvements of 29.5 AP_{50} and 33.7 Recall@10 for sentence inputs under zero-shot transfer conditions. Both the dataset and the label engine will be released publicly.
Bridging Sensor Gaps via Single-Direction Tuning for Hyperspectral Image Classification
Sep 22, 2023

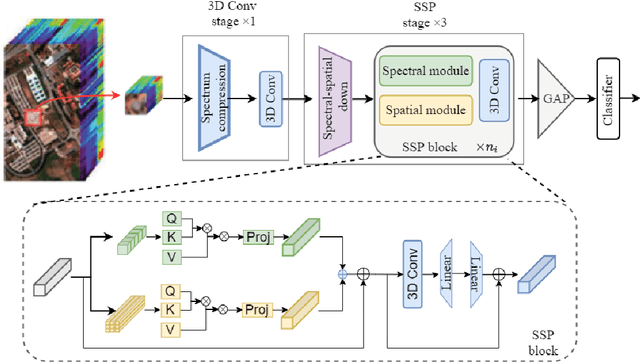

Recently, some researchers started exploring the use of ViTs in tackling HSI classification and achieved remarkable results. However, the training of ViT models requires a considerable number of training samples, while hyperspectral data, due to its high annotation costs, typically has a relatively small number of training samples. This contradiction has not been effectively addressed. In this paper, aiming to solve this problem, we propose the single-direction tuning (SDT) strategy, which serves as a bridge, allowing us to leverage existing labeled HSI datasets even RGB datasets to enhance the performance on new HSI datasets with limited samples. The proposed SDT inherits the idea of prompt tuning, aiming to reuse pre-trained models with minimal modifications for adaptation to new tasks. But unlike prompt tuning, SDT is custom-designed to accommodate the characteristics of HSIs. The proposed SDT utilizes a parallel architecture, an asynchronous cold-hot gradient update strategy, and unidirectional interaction. It aims to fully harness the potent representation learning capabilities derived from training on heterologous, even cross-modal datasets. In addition, we also introduce a novel Triplet-structured transformer (Tri-Former), where spectral attention and spatial attention modules are merged in parallel to construct the token mixing component for reducing computation cost and a 3D convolution-based channel mixer module is integrated to enhance stability and keep structure information. Comparison experiments conducted on three representative HSI datasets captured by different sensors demonstrate the proposed Tri-Former achieves better performance compared to several state-of-the-art methods. Homologous, heterologous and cross-modal tuning experiments verified the effectiveness of the proposed SDT.
3D-ANAS v2: Grafting Transformer Module on Automatically Designed ConvNet for Hyperspectral Image Classification
Oct 21, 2021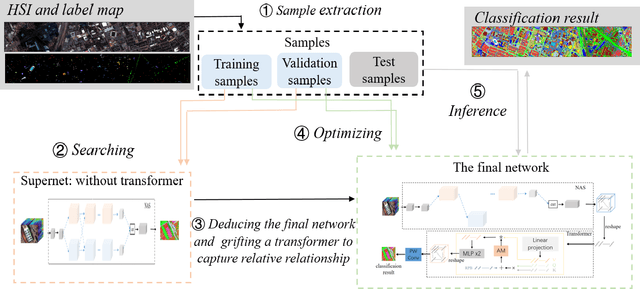
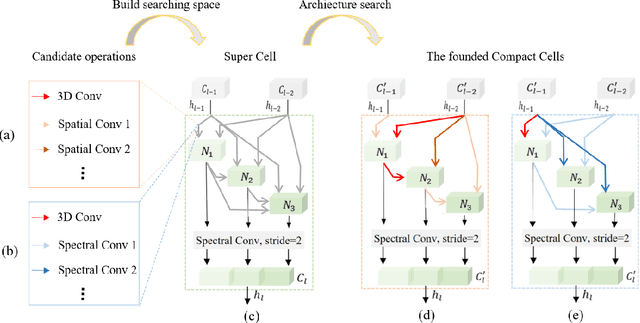
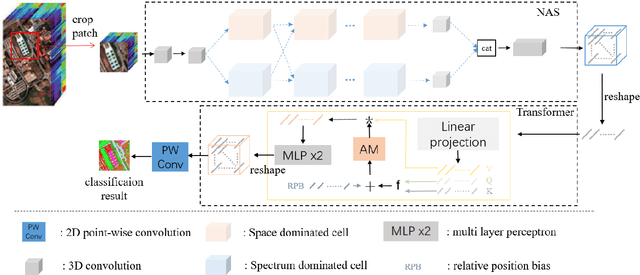
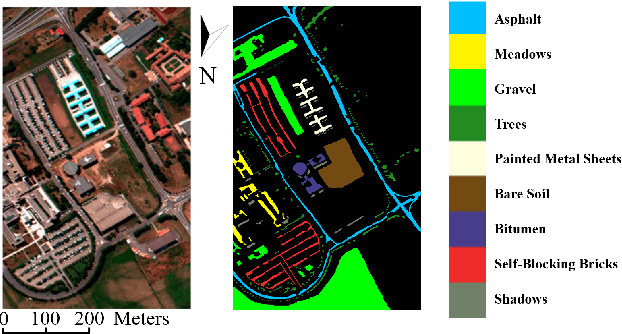
Hyperspectral image (HSI) classification has been a hot topic for decides, as Hyperspectral image has rich spatial and spectral information, providing strong basis for distinguishing different land-cover objects. Benefiting from the development of deep learning technologies, deep learning based HSI classification methods have achieved promising performance. Recently, several neural architecture search (NAS) algorithms are proposed for HSI classification, which further improve the accuracy of HSI classification to a new level. In this paper, we revisit the search space designed in previous HSI classification NAS methods and propose a novel hybrid search space, where 3D convolution, 2D spatial convolution and 2D spectral convolution are employed. Compared search space proposed in previous works, the serach space proposed in this paper is more aligned with characteristic of HSI data that is HSIs have a relatively low spatial resolution and an extremely high spectral resolution. In addition, to further improve the classification accuracy, we attempt to graft the emerging transformer module on the automatically designed ConvNet to adding global information to local region focused features learned by ConvNet. We carry out comparison experiments on three public HSI datasets which have different spectral characteristics to evaluate the proposed method. Experimental results show that the proposed method achieves much better performance than comparison approaches, and both adopting the proposed hybrid search space and grafting transformer module improves classification accuracy. Especially on the most recently captured dataset Houston University, overall accuracy is improved by up to nearly 6 percentage points. Code will be available at: https://github.com/xmm/3D-ANAS-V2.
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021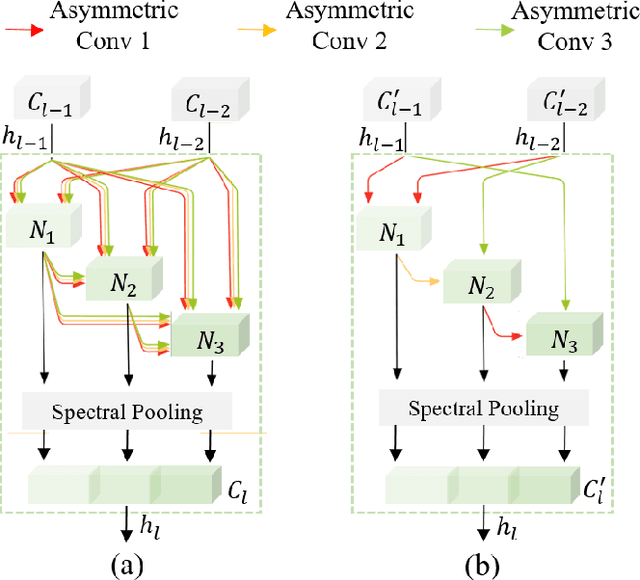

Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Memory-Efficient Hierarchical Neural Architecture Search for Image Restoration
Dec 28, 2020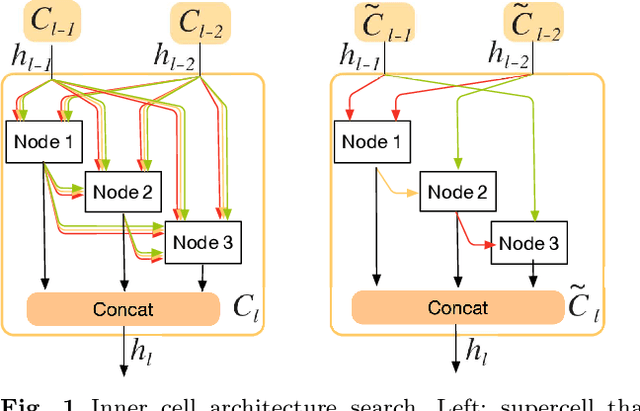

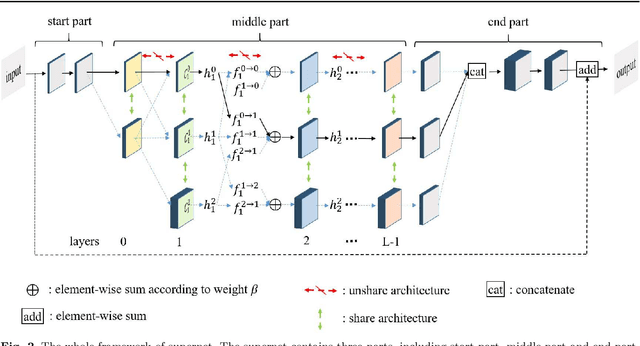

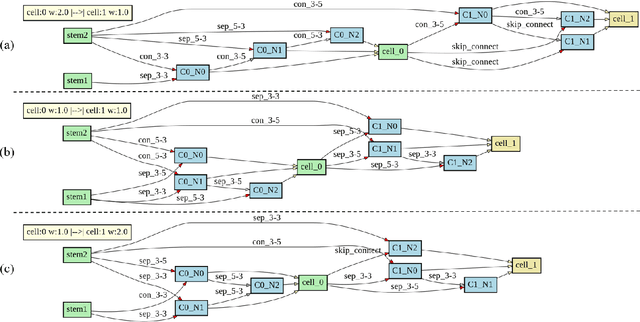
Recently, much attention has been spent on neural architecture search (NAS) approaches, which often outperform manually designed architectures on highlevel vision tasks. Inspired by this, we attempt to leverage NAS technique to automatically design efficient network architectures for low-level image restoration tasks. In this paper, we propose a memory-efficient hierarchical NAS HiNAS (HiNAS) and apply to two such tasks: image denoising and image super-resolution. HiNAS adopts gradient based search strategies and builds an flexible hierarchical search space, including inner search space and outer search space, which in charge of designing cell architectures and deciding cell widths, respectively. For inner search space, we propose layerwise architecture sharing strategy (LWAS), resulting in more flexible architectures and better performance. For outer search space, we propose cell sharing strategy to save memory, and considerably accelerate the search speed. The proposed HiNAS is both memory and computation efficient. With a single GTX1080Ti GPU, it takes only about 1 hour for searching for denoising network on BSD 500 and 3.5 hours for searching for the super-resolution structure on DIV2K. Experimental results show that the architectures found by HiNAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods.