 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVLM: Benchmarking Video Language Model for Underwater World Understanding
Jul 03, 2025Recently, the remarkable success of large language models (LLMs) has achieved a profound impact on the field of artificial intelligence. Numerous advanced works based on LLMs have been proposed and applied in various scenarios. Among them, video language models (VidLMs) are particularly widely used. However, existing works primarily focus on terrestrial scenarios, overlooking the highly demanding application needs of underwater observation. To overcome this gap, we introduce UVLM, an under water observation benchmark which is build through a collaborative approach combining human expertise and AI models. To ensure data quality, we have conducted in-depth considerations from multiple perspectives. First, to address the unique challenges of underwater environments, we selected videos that represent typical underwater challenges including light variations, water turbidity, and diverse viewing angles to construct the dataset. Second, to ensure data diversity, the dataset covers a wide range of frame rates, resolutions, 419 classes of marine animals, and various static plants and terrains. Next, for task diversity, we adopted a structured design where observation targets are categorized into two major classes: biological and environmental. Each category includes content observation and change/action observation, totaling 20 distinct task types. Finally, we designed several challenging evaluation metrics to enable quantitative comparison and analysis of different methods. Experiments on two representative VidLMs demonstrate that fine-tuning VidLMs on UVLM significantly improves underwater world understanding while also showing potential for slight improvements on existing in-air VidLM benchmarks, such as VideoMME and Perception text. The dataset and prompt engineering will be released publicly.
From Word to Sentence: A Large-Scale Multi-Instance Dataset for Open-Set Aerial Detection
May 06, 2025In recent years, language-guided open-world aerial object detection has gained significant attention due to its better alignment with real-world application needs. However, due to limited datasets, most existing language-guided methods primarily focus on vocabulary, which fails to meet the demands of more fine-grained open-world detection. To address this limitation, we propose constructing a large-scale language-guided open-set aerial detection dataset, encompassing three levels of language guidance: from words to phrases, and ultimately to sentences. Centered around an open-source large vision-language model and integrating image-operation-based preprocessing with BERT-based postprocessing, we present the OS-W2S Label Engine, an automatic annotation pipeline capable of handling diverse scene annotations for aerial images. Using this label engine, we expand existing aerial detection datasets with rich textual annotations and construct a novel benchmark dataset, called Multi-instance Open-set Aerial Dataset (MI-OAD), addressing the limitations of current remote sensing grounding data and enabling effective open-set aerial detection. Specifically, MI-OAD contains 163,023 images and 2 million image-caption pairs, approximately 40 times larger than comparable datasets. We also employ state-of-the-art open-set methods from the natural image domain, trained on our proposed dataset, to validate the model's open-set detection capabilities. For instance, when trained on our dataset, Grounding DINO achieves improvements of 29.5 AP_{50} and 33.7 Recall@10 for sentence inputs under zero-shot transfer conditions. Both the dataset and the label engine will be released publicly.
Regression in EO: Are VLMs Up to the Challenge?
Feb 19, 2025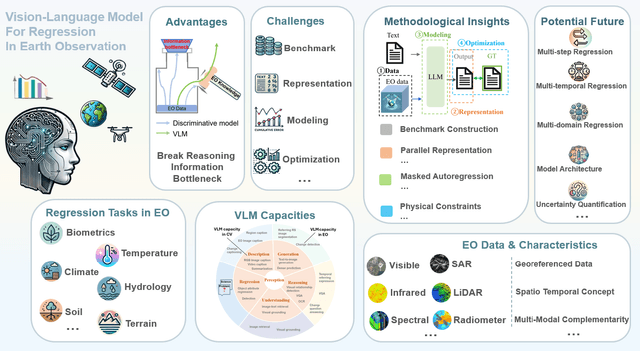
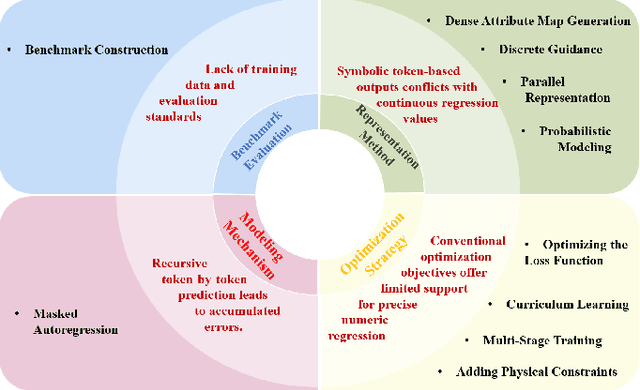
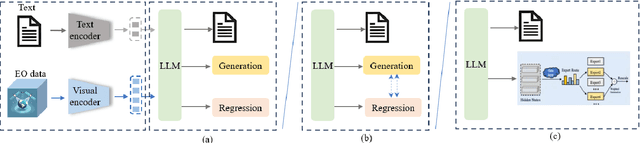
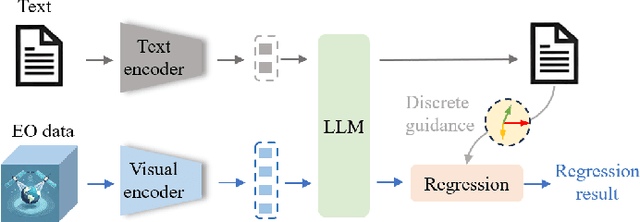
Earth Observation (EO) data encompass a vast range of remotely sensed information, featuring multi-sensor and multi-temporal, playing an indispensable role in understanding our planet's dynamics. Recently, Vision Language Models (VLMs) have achieved remarkable success in perception and reasoning tasks, bringing new insights and opportunities to the EO field. However, the potential for EO applications, especially for scientific regression related applications remains largely unexplored. This paper bridges that gap by systematically examining the challenges and opportunities of adapting VLMs for EO regression tasks. The discussion first contrasts the distinctive properties of EO data with conventional computer vision datasets, then identifies four core obstacles in applying VLMs to EO regression: 1) the absence of dedicated benchmarks, 2) the discrete-versus-continuous representation mismatch, 3) cumulative error accumulation, and 4) the suboptimal nature of text-centric training objectives for numerical tasks. Next, a series of methodological insights and potential subtle pitfalls are explored. Lastly, we offer some promising future directions for designing robust, domain-aware solutions. Our findings highlight the promise of VLMs for scientific regression in EO, setting the stage for more precise and interpretable modeling of critical environmental processes.
REO-VLM: Transforming VLM to Meet Regression Challenges in Earth Observation
Dec 21, 2024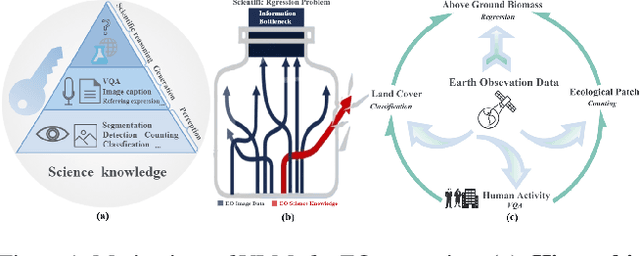


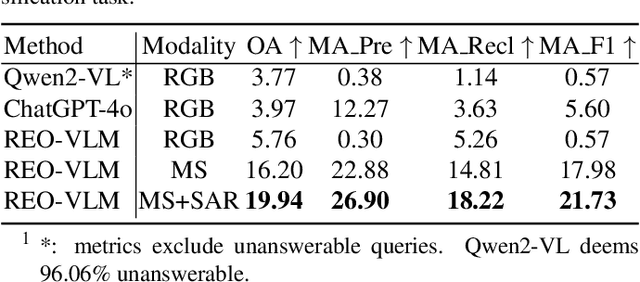
The rapid evolution of Vision Language Models (VLMs) has catalyzed significant advancements in artificial intelligence, expanding research across various disciplines, including Earth Observation (EO). While VLMs have enhanced image understanding and data processing within EO, their applications have predominantly focused on image content description. This limited focus overlooks their potential in geographic and scientific regression tasks, which are essential for diverse EO applications. To bridge this gap, this paper introduces a novel benchmark dataset, called \textbf{REO-Instruct} to unify regression and generation tasks specifically for the EO domain. Comprising 1.6 million multimodal EO imagery and language pairs, this dataset is designed to support both biomass regression and image content interpretation tasks. Leveraging this dataset, we develop \textbf{REO-VLM}, a groundbreaking model that seamlessly integrates regression capabilities with traditional generative functions. By utilizing language-driven reasoning to incorporate scientific domain knowledge, REO-VLM goes beyond solely relying on EO imagery, enabling comprehensive interpretation of complex scientific attributes from EO data. This approach establishes new performance benchmarks and significantly enhances the capabilities of environmental monitoring and resource management.
Advancements in Visual Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques
Oct 15, 2024
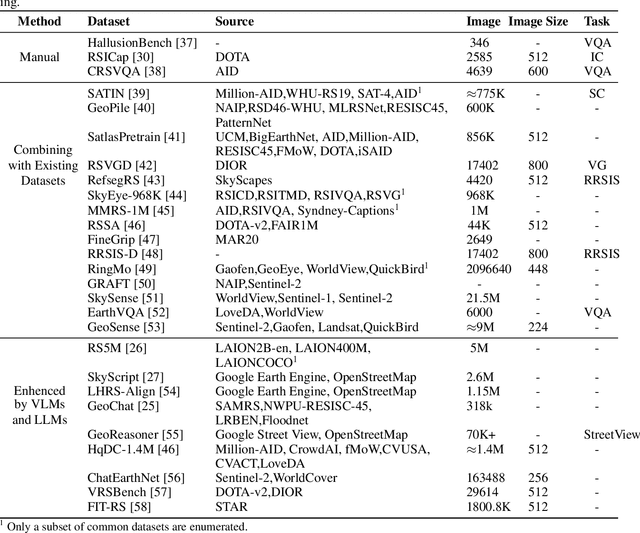
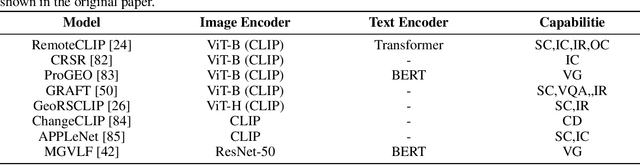
Recently, the remarkable success of ChatGPT has sparked a renewed wave of interest in artificial intelligence (AI), and the advancements in visual language models (VLMs) have pushed this enthusiasm to new heights. Differring from previous AI approaches that generally formulated different tasks as discriminative models, VLMs frame tasks as generative models and align language with visual information, enabling the handling of more challenging problems. The remote sensing (RS) field, a highly practical domain, has also embraced this new trend and introduced several VLM-based RS methods that have demonstrated promising performance and enormous potential. In this paper, we first review the fundamental theories related to VLM, then summarize the datasets constructed for VLMs in remote sensing and the various tasks they addressed. Finally, we categorize the improvement methods into three main parts according to the core components of VLMs and provide a detailed introduction and comparison of these methods.
3D-RCNet: Learning from Transformer to Build a 3D Relational ConvNet for Hyperspectral Image Classification
Aug 25, 2024Recently, the Vision Transformer (ViT) model has replaced the classical Convolutional Neural Network (ConvNet) in various computer vision tasks due to its superior performance. Even in hyperspectral image (HSI) classification field, ViT-based methods also show promising potential. Nevertheless, ViT encounters notable difficulties in processing HSI data. Its self-attention mechanism, which exhibits quadratic complexity, escalates computational costs. Additionally, ViT's substantial demand for training samples does not align with the practical constraints posed by the expensive labeling of HSI data. To overcome these challenges, we propose a 3D relational ConvNet named 3D-RCNet, which inherits both strengths of ConvNet and ViT, resulting in high performance in HSI classification. We embed the self-attention mechanism of Transformer into the convolutional operation of ConvNet to design 3D relational convolutional operation and use it to build the final 3D-RCNet. The proposed 3D-RCNet maintains the high computational efficiency of ConvNet while enjoying the flexibility of ViT. Additionally, the proposed 3D relational convolutional operation is a plug-and-play operation, which can be inserted into previous ConvNet-based HSI classification methods seamlessly. Empirical evaluations on three representative benchmark HSI datasets show that the proposed model outperforms previous ConvNet-based and ViT-based HSI approaches.
Bridging Sensor Gaps via Single-Direction Tuning for Hyperspectral Image Classification
Sep 22, 2023

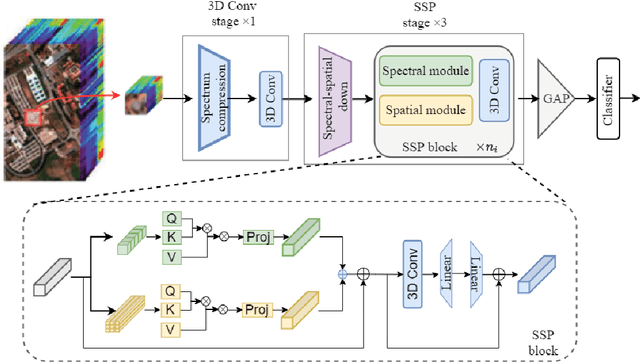

Recently, some researchers started exploring the use of ViTs in tackling HSI classification and achieved remarkable results. However, the training of ViT models requires a considerable number of training samples, while hyperspectral data, due to its high annotation costs, typically has a relatively small number of training samples. This contradiction has not been effectively addressed. In this paper, aiming to solve this problem, we propose the single-direction tuning (SDT) strategy, which serves as a bridge, allowing us to leverage existing labeled HSI datasets even RGB datasets to enhance the performance on new HSI datasets with limited samples. The proposed SDT inherits the idea of prompt tuning, aiming to reuse pre-trained models with minimal modifications for adaptation to new tasks. But unlike prompt tuning, SDT is custom-designed to accommodate the characteristics of HSIs. The proposed SDT utilizes a parallel architecture, an asynchronous cold-hot gradient update strategy, and unidirectional interaction. It aims to fully harness the potent representation learning capabilities derived from training on heterologous, even cross-modal datasets. In addition, we also introduce a novel Triplet-structured transformer (Tri-Former), where spectral attention and spatial attention modules are merged in parallel to construct the token mixing component for reducing computation cost and a 3D convolution-based channel mixer module is integrated to enhance stability and keep structure information. Comparison experiments conducted on three representative HSI datasets captured by different sensors demonstrate the proposed Tri-Former achieves better performance compared to several state-of-the-art methods. Homologous, heterologous and cross-modal tuning experiments verified the effectiveness of the proposed SDT.
Single-Stage Open-world Instance Segmentation with Cross-task Consistency Regularization
Aug 18, 2022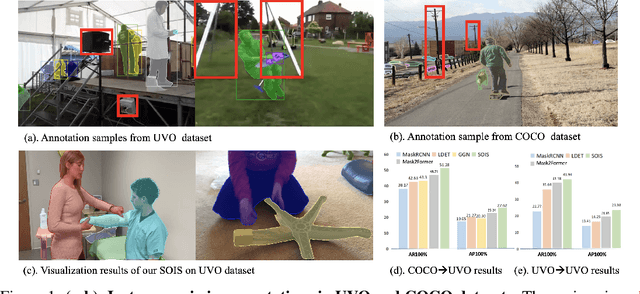
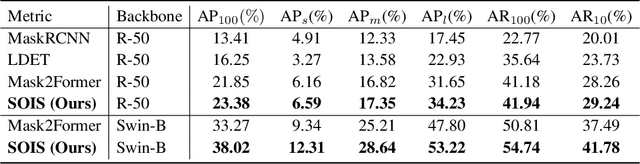
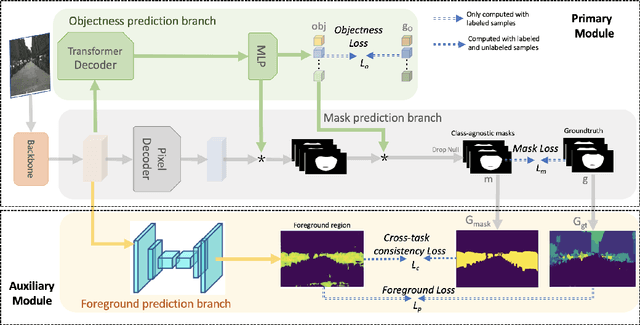

Open-world instance segmentation (OWIS) aims to segment class-agnostic instances from images, which has a wide range of real-world applications such as autonomous driving. Most existing approaches follow a two-stage pipeline: performing class-agnostic detection first and then class-specific mask segmentation. In contrast, this paper proposes a single-stage framework to produce a mask for each instance directly. Also, instance mask annotations could be noisy in the existing datasets; to overcome this issue, we introduce a new regularization loss. Specifically, we first train an extra branch to perform an auxiliary task of predicting foreground regions (i.e. regions belonging to any object instance), and then encourage the prediction from the auxiliary branch to be consistent with the predictions of the instance masks. The key insight is that such a cross-task consistency loss could act as an error-correcting mechanism to combat the errors in annotations. Further, we discover that the proposed cross-task consistency loss can be applied to images without any annotation, lending itself to a semi-supervised learning method. Through extensive experiments, we demonstrate that the proposed method can achieve impressive results in both fully-supervised and semi-supervised settings. Compared to SOTA methods, the proposed method significantly improves the $AP_{100}$ score by 4.75\% in UVO$\rightarrow$UVO setting and 4.05\% in COCO$\rightarrow$UVO setting. In the case of semi-supervised learning, our model learned with only 30\% labeled data, even outperforms its fully-supervised counterpart with 50\% labeled data. The code will be released soon.
3D-ANAS v2: Grafting Transformer Module on Automatically Designed ConvNet for Hyperspectral Image Classification
Oct 21, 2021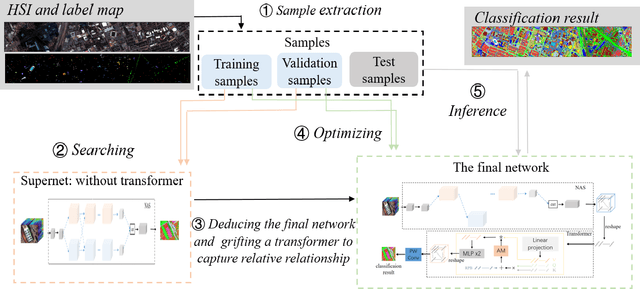
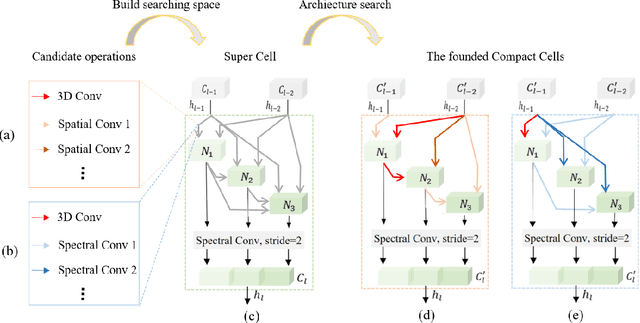
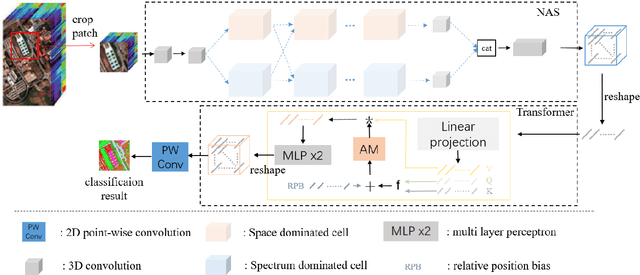
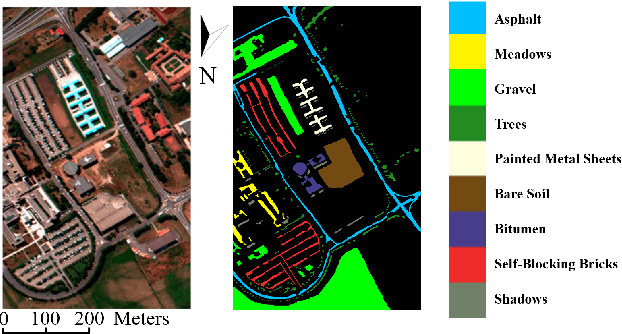
Hyperspectral image (HSI) classification has been a hot topic for decides, as Hyperspectral image has rich spatial and spectral information, providing strong basis for distinguishing different land-cover objects. Benefiting from the development of deep learning technologies, deep learning based HSI classification methods have achieved promising performance. Recently, several neural architecture search (NAS) algorithms are proposed for HSI classification, which further improve the accuracy of HSI classification to a new level. In this paper, we revisit the search space designed in previous HSI classification NAS methods and propose a novel hybrid search space, where 3D convolution, 2D spatial convolution and 2D spectral convolution are employed. Compared search space proposed in previous works, the serach space proposed in this paper is more aligned with characteristic of HSI data that is HSIs have a relatively low spatial resolution and an extremely high spectral resolution. In addition, to further improve the classification accuracy, we attempt to graft the emerging transformer module on the automatically designed ConvNet to adding global information to local region focused features learned by ConvNet. We carry out comparison experiments on three public HSI datasets which have different spectral characteristics to evaluate the proposed method. Experimental results show that the proposed method achieves much better performance than comparison approaches, and both adopting the proposed hybrid search space and grafting transformer module improves classification accuracy. Especially on the most recently captured dataset Houston University, overall accuracy is improved by up to nearly 6 percentage points. Code will be available at: https://github.com/xmm/3D-ANAS-V2.
DCF-ASN: Coarse-to-fine Real-time Visual Tracking via Discriminative Correlation Filter and Attentional Siamese Network
Mar 19, 2021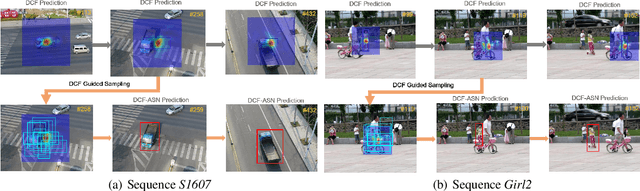
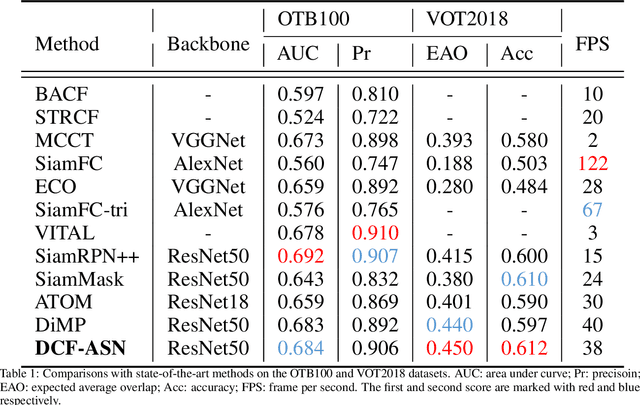
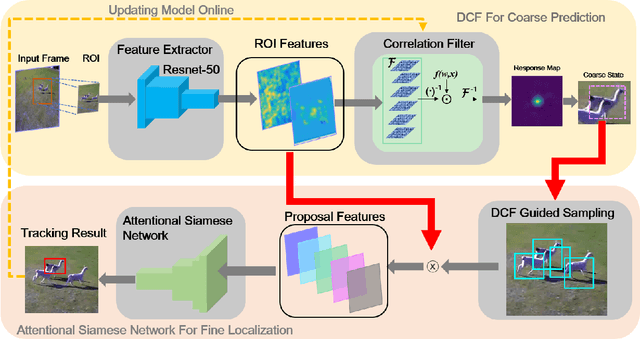

Discriminative correlation filters (DCF) and siamese networks have achieved promising performance on visual tracking tasks thanks to their superior computational efficiency and reliable similarity metric learning, respectively. However, how to effectively take advantages of powerful deep networks, while maintaining the real-time response of DCF, remains a challenging problem. Embedding the cross-correlation operator as a separate layer into siamese networks is a popular choice to enhance the tracking accuracy. Being a key component of such a network, the correlation layer is updated online together with other parts of the network. Yet, when facing serious disturbance, fused trackers may still drift away from the target completely due to accumulated errors. To address these issues, we propose a coarse-to-fine tracking framework, which roughly infers the target state via an online-updating DCF module first and subsequently, finely locates the target through an offline-training asymmetric siamese network (ASN). Benefitting from the guidance of DCF and the learned channel weights obtained through exploiting the given ground-truth template, ASN refines feature representation and implements precise target localization. Systematic experiments on five popular tracking datasets demonstrate that the proposed DCF-ASN achieves the state-of-the-art performance while exhibiting good tracking efficiency.