 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Word to Sentence: A Large-Scale Multi-Instance Dataset for Open-Set Aerial Detection
May 06, 2025In recent years, language-guided open-world aerial object detection has gained significant attention due to its better alignment with real-world application needs. However, due to limited datasets, most existing language-guided methods primarily focus on vocabulary, which fails to meet the demands of more fine-grained open-world detection. To address this limitation, we propose constructing a large-scale language-guided open-set aerial detection dataset, encompassing three levels of language guidance: from words to phrases, and ultimately to sentences. Centered around an open-source large vision-language model and integrating image-operation-based preprocessing with BERT-based postprocessing, we present the OS-W2S Label Engine, an automatic annotation pipeline capable of handling diverse scene annotations for aerial images. Using this label engine, we expand existing aerial detection datasets with rich textual annotations and construct a novel benchmark dataset, called Multi-instance Open-set Aerial Dataset (MI-OAD), addressing the limitations of current remote sensing grounding data and enabling effective open-set aerial detection. Specifically, MI-OAD contains 163,023 images and 2 million image-caption pairs, approximately 40 times larger than comparable datasets. We also employ state-of-the-art open-set methods from the natural image domain, trained on our proposed dataset, to validate the model's open-set detection capabilities. For instance, when trained on our dataset, Grounding DINO achieves improvements of 29.5 AP_{50} and 33.7 Recall@10 for sentence inputs under zero-shot transfer conditions. Both the dataset and the label engine will be released publicly.
OVA-DETR: Open Vocabulary Aerial Object Detection Using Image-Text Alignment and Fusion
Aug 22, 2024



Aerial object detection has been a hot topic for many years due to its wide application requirements. However, most existing approaches can only handle predefined categories, which limits their applicability for the open scenarios in real-world. In this paper, we extend aerial object detection to open scenarios by exploiting the relationship between image and text, and propose OVA-DETR, a high-efficiency open-vocabulary detector for aerial images. Specifically, based on the idea of image-text alignment, we propose region-text contrastive loss to replace the category regression loss in the traditional detection framework, which breaks the category limitation. Then, we propose Bidirectional Vision-Language Fusion (Bi-VLF), which includes a dual-attention fusion encoder and a multi-level text-guided Fusion Decoder. The dual-attention fusion encoder enhances the feature extraction process in the encoder part. The multi-level text-guided Fusion Decoder is designed to improve the detection ability for small objects, which frequently appear in aerial object detection scenarios. Experimental results on three widely used benchmark datasets show that our proposed method significantly improves the mAP and recall, while enjoying faster inference speed. For instance, in zero shot detection experiments on DIOR, the proposed OVA-DETR outperforms DescReg and YOLO-World by 37.4% and 33.1%, respectively, while achieving 87 FPS inference speed, which is 7.9x faster than DescReg and 3x faster than YOLO-world. The code is available at https://github.com/GT-Wei/OVA-DETR.
Real-time Keypoints Detection for Autonomous Recovery of the Unmanned Ground Vehicle
Jul 27, 2021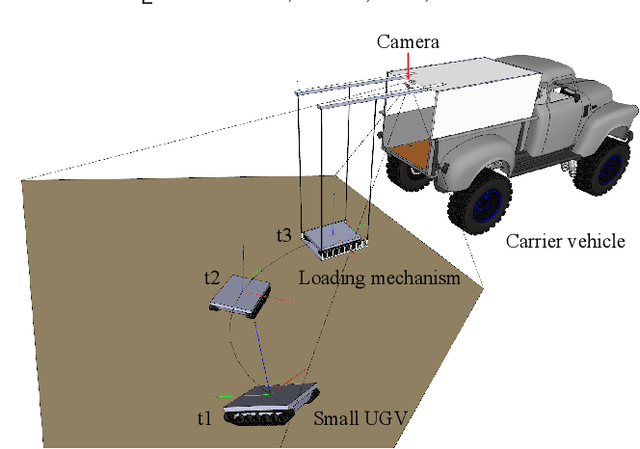

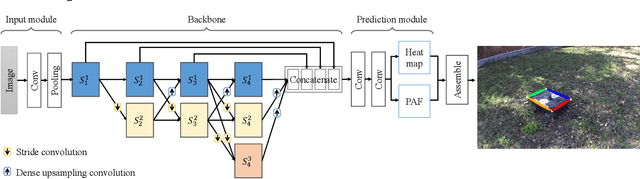

The combination of a small unmanned ground vehicle (UGV) and a large unmanned carrier vehicle allows more flexibility in real applications such as rescue in dangerous scenarios. The autonomous recovery system, which is used to guide the small UGV back to the carrier vehicle, is an essential component to achieve a seamless combination of the two vehicles. This paper proposes a novel autonomous recovery framework with a low-cost monocular vision system to provide accurate positioning and attitude estimation of the UGV during navigation. First, we introduce a light-weight convolutional neural network called UGV-KPNet to detect the keypoints of the small UGV from the images captured by a monocular camera. UGV-KPNet is computationally efficient with a small number of parameters and provides pixel-level accurate keypoints detection results in real-time. Then, six degrees of freedom pose is estimated using the detected keypoints to obtain positioning and attitude information of the UGV. Besides, we are the first to create a large-scale real-world keypoints dataset of the UGV. The experimental results demonstrate that the proposed system achieves state-of-the-art performance in terms of both accuracy and speed on UGV keypoint detection, and can further boost the 6-DoF pose estimation for the UGV.
3D Gated Recurrent Fusion for Semantic Scene Completion
Feb 17, 2020
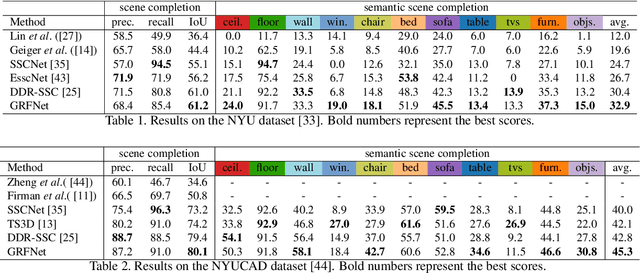


This paper tackles the problem of data fusion in the semantic scene completion (SSC) task, which can simultaneously deal with semantic labeling and scene completion. RGB images contain texture details of the object(s) which are vital for semantic scene understanding. Meanwhile, depth images capture geometric clues of high relevance for shape completion. Using both RGB and depth images can further boost the accuracy of SSC over employing one modality in isolation. We propose a 3D gated recurrent fusion network (GRFNet), which learns to adaptively select and fuse the relevant information from depth and RGB by making use of the gate and memory modules. Based on the single-stage fusion, we further propose a multi-stage fusion strategy, which could model the correlations among different stages within the network. Extensive experiments on two benchmark datasets demonstrate the superior performance and the effectiveness of the proposed GRFNet for data fusion in SSC. Code will be made available.
Depth Based Semantic Scene Completion with Position Importance Aware Loss
Jan 30, 2020
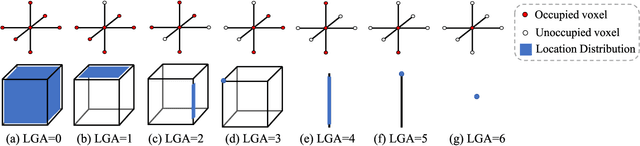
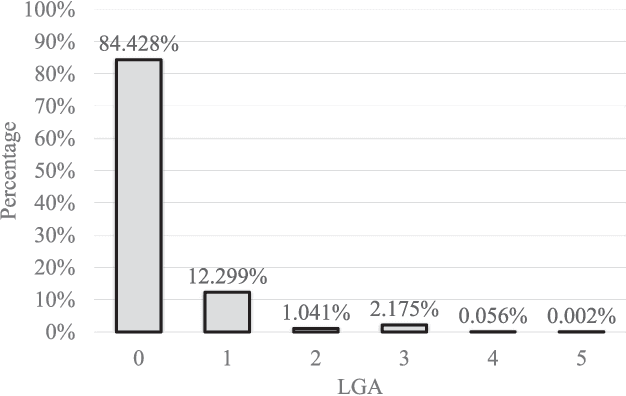
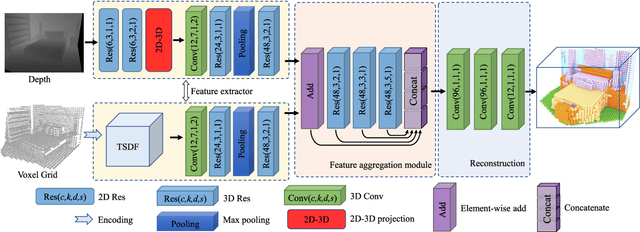
Semantic Scene Completion (SSC) refers to the task of inferring the 3D semantic segmentation of a scene while simultaneously completing the 3D shapes. We propose PALNet, a novel hybrid network for SSC based on single depth. PALNet utilizes a two-stream network to extract both 2D and 3D features from multi-stages using fine-grained depth information to efficiently captures the context, as well as the geometric cues of the scene. Current methods for SSC treat all parts of the scene equally causing unnecessary attention to the interior of objects. To address this problem, we propose Position Aware Loss(PA-Loss) which is position importance aware while training the network. Specifically, PA-Loss considers Local Geometric Anisotropy to determine the importance of different positions within the scene. It is beneficial for recovering key details like the boundaries of objects and the corners of the scene. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed method and its superior performance. Models and Video demo can be found at: https://github.com/UniLauX/PALNet.
RGBD Based Dimensional Decomposition Residual Network for 3D Semantic Scene Completion
Mar 02, 2019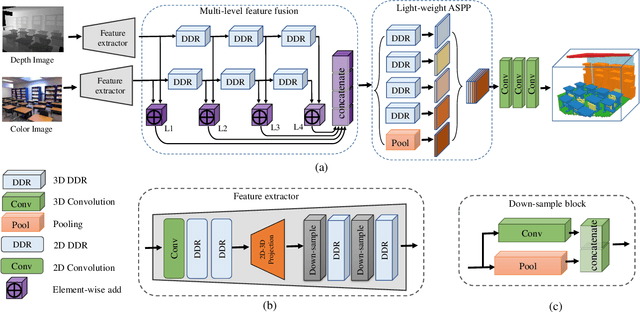

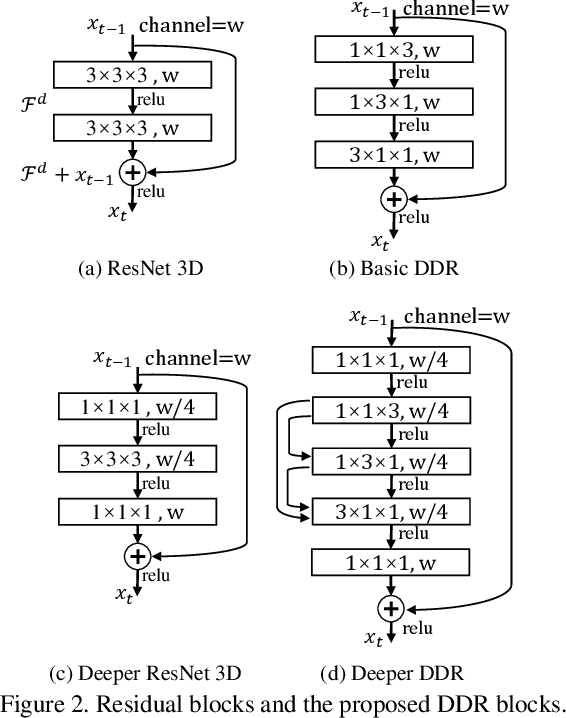

RGB images differentiate from depth images as they carry more details about the color and texture information, which can be utilized as a vital complementary to depth for boosting the performance of 3D semantic scene completion (SSC). SSC is composed of 3D shape completion (SC) and semantic scene labeling while most of the existing methods use depth as the sole input which causes the performance bottleneck. Moreover, the state-of-the-art methods employ 3D CNNs which have cumbersome networks and tremendous parameters. We introduce a light-weight Dimensional Decomposition Residual network (DDR) for 3D dense prediction tasks. The novel factorized convolution layer is effective for reducing the network parameters, and the proposed multi-scale fusion mechanism for depth and color image can improve the completion and segmentation accuracy simultaneously. Our method demonstrates excellent performance on two public datasets. Compared with the latest method SSCNet, we achieve 5.9% gains in SC-IoU and 5.7% gains in SSC-IOU, albeit with only 21% network parameters and 16.6% FLOPs employed compared with that of SSCNet.