 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIEVR-LIO: Robust LiDAR-Inertial Odometry through Bump-Image-Enhanced Voxel Maps
Apr 15, 2026Reliable odometry is essential for mobile robots as they increasingly enter more challenging environments, which often contain little information to constrain point cloud registration, resulting in degraded LiDAR-Inertial Odometry (LIO) accuracy or even divergence. To address this, we present BIEVR-LIO, a novel approach designed specifically to exploit subtle variations in the available geometry for improved robustness. We propose a high-resolution map representation that stores surfaces as compact voxel-wise oriented height images. This representation can directly be used for registration without the calculation of intermediate geometric primitives while still supporting efficient updates. Since informative geometry is often sparsely distributed in the environment, we further propose a map-informed point sampling strategy to focus registration on geometrically informative regions, improving robustness in uninformative environments while reducing computational cost compared to global high-resolution sampling. Experiments across multiple sensors, platforms, and environments demonstrates state-of-the-art performance in well-constrained scenes and substantial improvements in challenging scenarios where baseline methods diverge. Additionally, we demonstrate that the fine-grained geometry captured by BIEVR-LIO can be used for downstream tasks such as elevation mapping for robot locomotion.
Efficient Hierarchical Any-Angle Path Planning on Multi-Resolution 3D Grids
Feb 24, 2026Hierarchical, multi-resolution volumetric mapping approaches are widely used to represent large and complex environments as they can efficiently capture their occupancy and connectivity information. Yet widely used path planning methods such as sampling and trajectory optimization do not exploit this explicit connectivity information, and search-based methods such as A* suffer from scalability issues in large-scale high-resolution maps. In many applications, Euclidean shortest paths form the underpinning of the navigation system. For such applications, any-angle planning methods, which find optimal paths by connecting corners of obstacles with straight-line segments, provide a simple and efficient solution. In this paper, we present a method that has the optimality and completeness properties of any-angle planners while overcoming computational tractability issues common to search-based methods by exploiting multi-resolution representations. Extensive experiments on real and synthetic environments demonstrate the proposed approach's solution quality and speed, outperforming even sampling-based methods. The framework is open-sourced to allow the robotics and planning community to build on our research.
* 12 pages, 9 figures, 4 tables, accepted to RSS 2025, code is open-source: https://github.com/ethz-asl/wavestar
Depth Completion in Unseen Field Robotics Environments Using Extremely Sparse Depth Measurements
Feb 03, 2026Autonomous field robots operating in unstructured environments require robust perception to ensure safe and reliable operations. Recent advances in monocular depth estimation have demonstrated the potential of low-cost cameras as depth sensors; however, their adoption in field robotics remains limited due to the absence of reliable scale cues, ambiguous or low-texture conditions, and the scarcity of large-scale datasets. To address these challenges, we propose a depth completion model that trains on synthetic data and uses extremely sparse measurements from depth sensors to predict dense metric depth in unseen field robotics environments. A synthetic dataset generation pipeline tailored to field robotics enables the creation of multiple realistic datasets for training purposes. This dataset generation approach utilizes textured 3D meshes from Structure from Motion and photorealistic rendering with novel viewpoint synthesis to simulate diverse field robotics scenarios. Our approach achieves an end-to-end latency of 53 ms per frame on a Nvidia Jetson AGX Orin, enabling real-time deployment on embedded platforms. Extensive evaluation demonstrates competitive performance across diverse real-world field robotics scenarios.
Discontinuity-aware Normal Integration for Generic Central Camera Models
Jul 08, 2025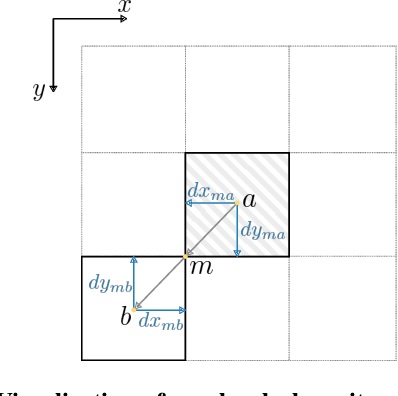
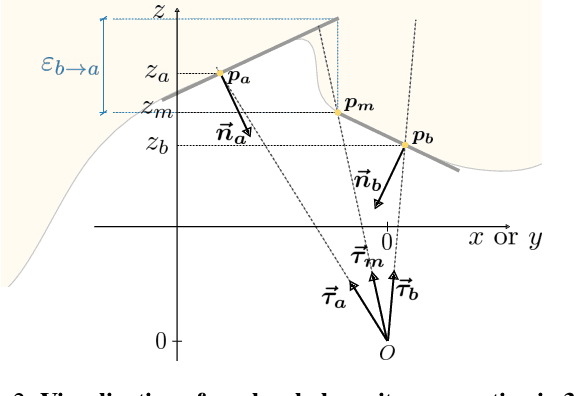
Recovering a 3D surface from its surface normal map, a problem known as normal integration, is a key component for photometric shape reconstruction techniques such as shape-from-shading and photometric stereo. The vast majority of existing approaches for normal integration handle only implicitly the presence of depth discontinuities and are limited to orthographic or ideal pinhole cameras. In this paper, we propose a novel formulation that allows modeling discontinuities explicitly and handling generic central cameras. Our key idea is based on a local planarity assumption, that we model through constraints between surface normals and ray directions. Compared to existing methods, our approach more accurately approximates the relation between depth and surface normals, achieves state-of-the-art results on the standard normal integration benchmark, and is the first to directly handle generic central camera models.
CompSLAM: Complementary Hierarchical Multi-Modal Localization and Mapping for Robot Autonomy in Underground Environments
May 10, 2025Robot autonomy in unknown, GPS-denied, and complex underground environments requires real-time, robust, and accurate onboard pose estimation and mapping for reliable operations. This becomes particularly challenging in perception-degraded subterranean conditions under harsh environmental factors, including darkness, dust, and geometrically self-similar structures. This paper details CompSLAM, a highly resilient and hierarchical multi-modal localization and mapping framework designed to address these challenges. Its flexible architecture achieves resilience through redundancy by leveraging the complementary nature of pose estimates derived from diverse sensor modalities. Developed during the DARPA Subterranean Challenge, CompSLAM was successfully deployed on all aerial, legged, and wheeled robots of Team Cerberus during their competition-winning final run. Furthermore, it has proven to be a reliable odometry and mapping solution in various subsequent projects, with extensions enabling multi-robot map sharing for marsupial robotic deployments and collaborative mapping. This paper also introduces a comprehensive dataset acquired by a manually teleoperated quadrupedal robot, covering a significant portion of the DARPA Subterranean Challenge finals course. This dataset evaluates CompSLAM's robustness to sensor degradations as the robot traverses 740 meters in an environment characterized by highly variable geometries and demanding lighting conditions. The CompSLAM code and the DARPA SubT Finals dataset are made publicly available for the benefit of the robotics community
Towards Open-Source and Modular Space Systems with ATMOS
Jan 28, 2025



In the near future, autonomous space systems will compose a large number of the spacecraft being deployed. Their tasks will involve autonomous rendezvous and proximity operations with large structures, such as inspections or assembly of orbiting space stations and maintenance and human-assistance tasks over shared workspaces. To promote replicable and reliable scientific results for autonomous control of spacecraft, we present the design of a space systems laboratory based on open-source and modular software and hardware. The simulation software provides a software-in-the-loop (SITL) architecture that seamlessly transfers simulated results to the ATMOS platforms, developed for testing of multi-agent autonomy schemes for microgravity. The manuscript presents the KTH space systems laboratory facilities and the ATMOS platform as open-source hardware and software contributions. Preliminary results showcase SITL and real testing.
Learning Affordances from Interactive Exploration using an Object-level Map
Jan 10, 2025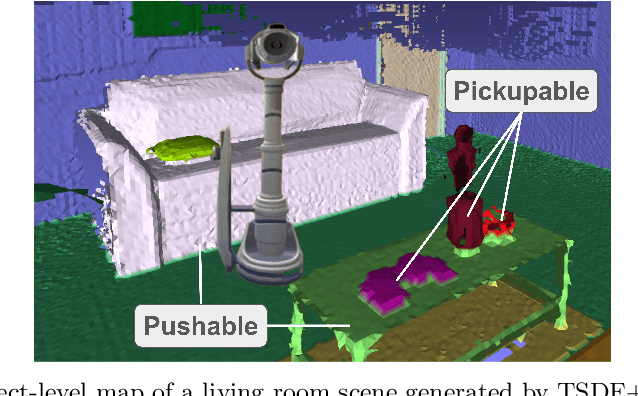
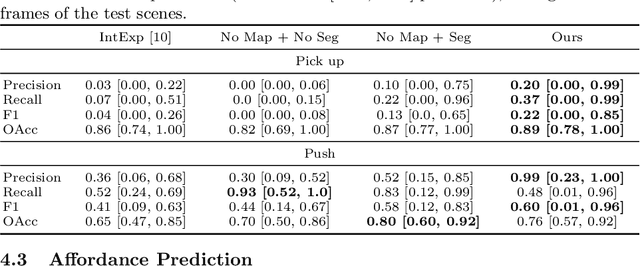
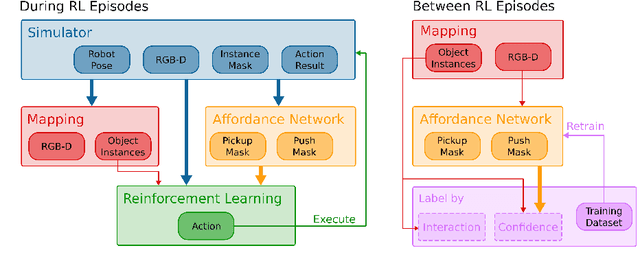
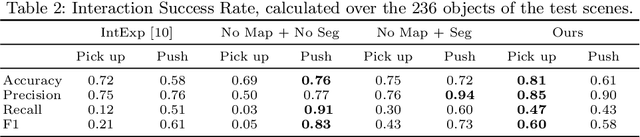
Many robotic tasks in real-world environments require physical interactions with an object such as pick up or push. For successful interactions, the robot needs to know the object's affordances, which are defined as the potential actions the robot can perform with the object. In order to learn a robot-specific affordance predictor, we propose an interactive exploration pipeline which allows the robot to collect interaction experiences while exploring an unknown environment. We integrate an object-level map in the exploration pipeline such that the robot can identify different object instances and track objects across diverse viewpoints. This results in denser and more accurate affordance annotations compared to state-of-the-art methods, which do not incorporate a map. We show that our affordance exploration approach makes exploration more efficient and results in more accurate affordance prediction models compared to baseline methods.
Allocation for Omnidirectional Aerial Robots: Incorporating Power Dynamics
Dec 20, 2024



Tilt-rotor aerial robots are more dynamic and versatile than their fixed-rotor counterparts, since the thrust vector and body orientation are decoupled. However, the coordination of servomotors and propellers (the allocation problem) is not trivial, especially accounting for overactuation and actuator dynamics. We present and compare different methods of actuator allocation for tilt-rotor platforms, evaluating them on a real aerial robot performing dynamic trajectories. We extend the state-of-the-art geometric allocation into a differential allocation, which uses the platform's redundancy and does not suffer from singularities typical of the geometric solution. We expand it by incorporating actuator dynamics and introducing propeller limit curves. These improve the modeling of propeller limits, automatically balancing their usage and allowing the platform to selectively activate and deactivate propellers during flight. We show that actuator dynamics and limits make the tuning of the allocation not only easier, but also allow it to track more dynamic oscillating trajectories with angular velocities up to 4 rad/s, compared to 2.8 rad/s of geometric methods.
Evaluation of Human-Robot Interfaces based on 2D/3D Visual and Haptic Feedback for Aerial Manipulation
Oct 20, 2024



Most telemanipulation systems for aerial robots provide the operator with only 2D screen visual information. The lack of richer information about the robot's status and environment can limit human awareness and, in turn, task performance. While the pilot's experience can often compensate for this reduced flow of information, providing richer feedback is expected to reduce the cognitive workload and offer a more intuitive experience overall. This work aims to understand the significance of providing additional pieces of information during aerial telemanipulation, namely (i) 3D immersive visual feedback about the robot's surroundings through mixed reality (MR) and (ii) 3D haptic feedback about the robot interaction with the environment. To do so, we developed a human-robot interface able to provide this information. First, we demonstrate its potential in a real-world manipulation task requiring sub-centimeter-level accuracy. Then, we evaluate the individual effect of MR vision and haptic feedback on both dexterity and workload through a human subjects study involving a virtual block transportation task. Results show that both 3D MR vision and haptic feedback improve the operator's dexterity in the considered teleoperated aerial interaction tasks. Nevertheless, pilot experience remains the most significant factor.
Obstacle-Avoidant Leader Following with a Quadruped Robot
Oct 01, 2024Personal mobile robotic assistants are expected to find wide applications in industry and healthcare. For example, people with limited mobility can benefit from robots helping with daily tasks, or construction workers can have robots perform precision monitoring tasks on-site. However, manually steering a robot while in motion requires significant concentration from the operator, especially in tight or crowded spaces. This reduces walking speed, and the constant need for vigilance increases fatigue and, thus, the risk of accidents. This work presents a virtual leash with which a robot can naturally follow an operator. We use a sensor fusion based on a custom-built RF transponder, RGB cameras, and a LiDAR. In addition, we customize a local avoidance planner for legged platforms, which enables us to navigate dynamic and narrow environments. We successfully validate on the ANYmal platform the robustness and performance of our entire pipeline in real-world experiments.