 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscontinuity-aware Normal Integration for Generic Central Camera Models
Jul 08, 2025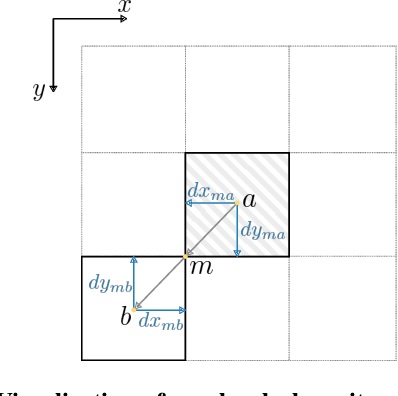
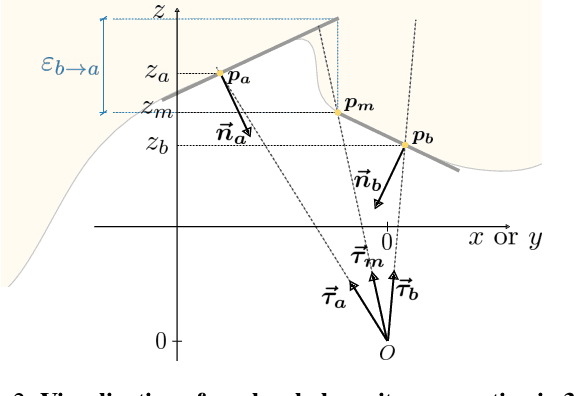
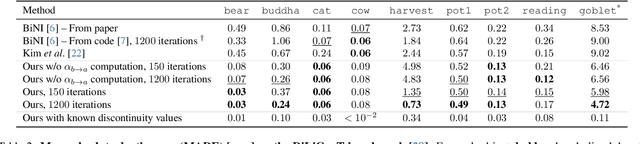
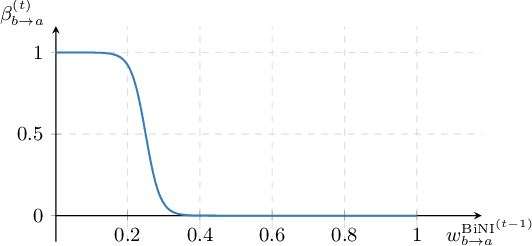
Recovering a 3D surface from its surface normal map, a problem known as normal integration, is a key component for photometric shape reconstruction techniques such as shape-from-shading and photometric stereo. The vast majority of existing approaches for normal integration handle only implicitly the presence of depth discontinuities and are limited to orthographic or ideal pinhole cameras. In this paper, we propose a novel formulation that allows modeling discontinuities explicitly and handling generic central cameras. Our key idea is based on a local planarity assumption, that we model through constraints between surface normals and ray directions. Compared to existing methods, our approach more accurately approximates the relation between depth and surface normals, achieves state-of-the-art results on the standard normal integration benchmark, and is the first to directly handle generic central camera models.
NeuSurfEmb: A Complete Pipeline for Dense Correspondence-based 6D Object Pose Estimation without CAD Models
Jul 16, 2024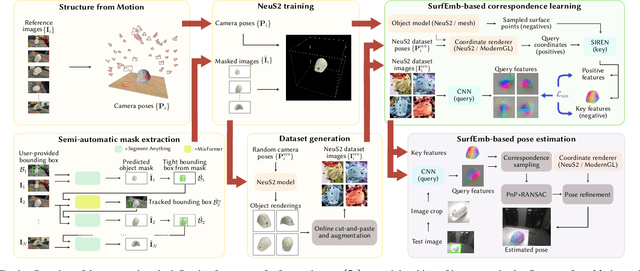



State-of-the-art approaches for 6D object pose estimation assume the availability of CAD models and require the user to manually set up physically-based rendering (PBR) pipelines for synthetic training data generation. Both factors limit the application of these methods in real-world scenarios. In this work, we present a pipeline that does not require CAD models and allows training a state-of-the-art pose estimator requiring only a small set of real images as input. Our method is based on a NeuS2 object representation, that we learn through a semi-automated procedure based on Structure-from-Motion (SfM) and object-agnostic segmentation. We exploit the novel-view synthesis ability of NeuS2 and simple cut-and-paste augmentation to automatically generate photorealistic object renderings, which we use to train the correspondence-based SurfEmb pose estimator. We evaluate our method on the LINEMOD-Occlusion dataset, extensively studying the impact of its individual components and showing competitive performance with respect to approaches based on CAD models and PBR data. We additionally demonstrate the ease of use and effectiveness of our pipeline on self-collected real-world objects, showing that our method outperforms state-of-the-art CAD-model-free approaches, with better accuracy and robustness to mild occlusions. To allow the robotics community to benefit from this system, we will publicly release it at https://www.github.com/ethz-asl/neusurfemb.
ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
Nov 05, 2023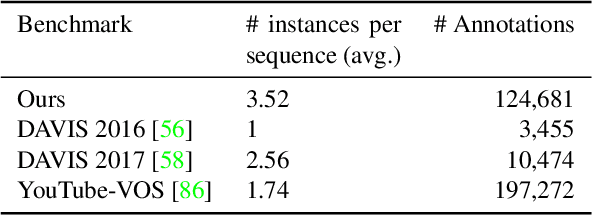

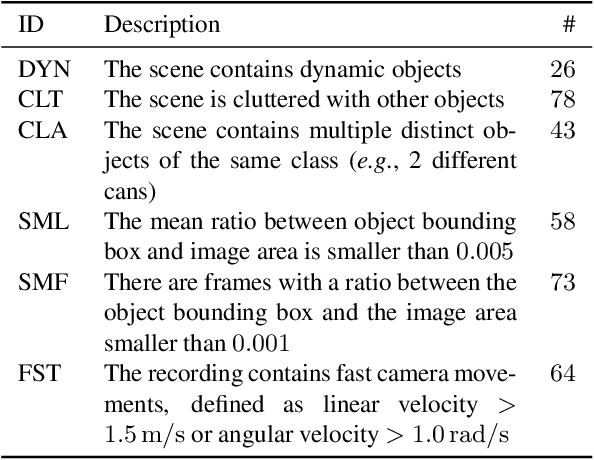
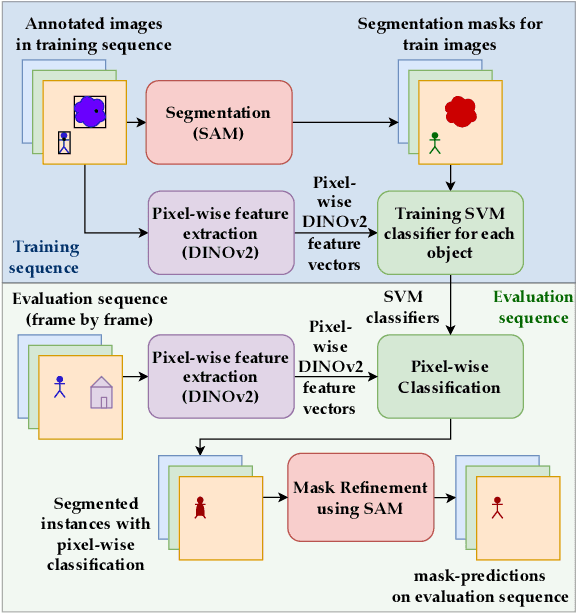
Most object-level mapping systems in use today make use of an upstream learned object instance segmentation model. If we want to teach them about a new object or segmentation class, we need to build a large dataset and retrain the system. To build spatial AI systems that can quickly be taught about new objects, we need to effectively solve the problem of single-shot object detection, instance segmentation and re-identification. So far there is neither a method fulfilling all of these requirements in unison nor a benchmark that could be used to test such a method. Addressing this, we propose ISAR, a benchmark and baseline method for single- and few-shot object Instance Segmentation And Re-identification, in an effort to accelerate the development of algorithms that can robustly detect, segment, and re-identify objects from a single or a few sparse training examples. We provide a semi-synthetic dataset of video sequences with ground-truth semantic annotations, a standardized evaluation pipeline, and a baseline method. Our benchmark aligns with the emerging research trend of unifying Multi-Object Tracking, Video Object Segmentation, and Re-identification.
Panoptic Vision-Language Feature Fields
Sep 11, 2023Recently, methods have been proposed for 3D open-vocabulary semantic segmentation. Such methods are able to segment scenes into arbitrary classes given at run-time using their text description. In this paper, we propose to our knowledge the first algorithm for open-vocabulary panoptic segmentation, simultaneously performing both semantic and instance segmentation. Our algorithm, Panoptic Vision-Language Feature Fields (PVLFF) learns a feature field of the scene, jointly learning vision-language features and hierarchical instance features through a contrastive loss function from 2D instance segment proposals on input frames. Our method achieves comparable performance against the state-of-the-art close-set 3D panoptic systems on the HyperSim, ScanNet and Replica dataset and outperforms current 3D open-vocabulary systems in terms of semantic segmentation. We additionally ablate our method to demonstrate the effectiveness of our model architecture. Our code will be available at https://github.com/ethz-asl/autolabel.
Neural Implicit Vision-Language Feature Fields
Mar 20, 2023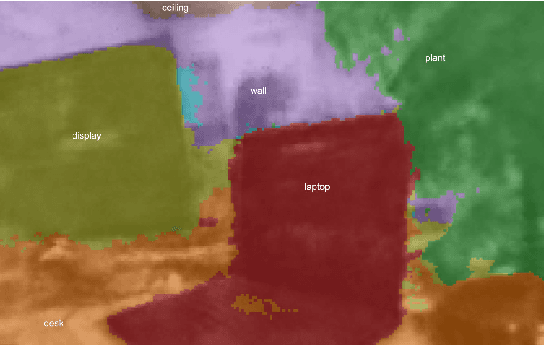


Recently, groundbreaking results have been presented on open-vocabulary semantic image segmentation. Such methods segment each pixel in an image into arbitrary categories provided at run-time in the form of text prompts, as opposed to a fixed set of classes defined at training time. In this work, we present a zero-shot volumetric open-vocabulary semantic scene segmentation method. Our method builds on the insight that we can fuse image features from a vision-language model into a neural implicit representation. We show that the resulting feature field can be segmented into different classes by assigning points to natural language text prompts. The implicit volumetric representation enables us to segment the scene both in 3D and 2D by rendering feature maps from any given viewpoint of the scene. We show that our method works on noisy real-world data and can run in real-time on live sensor data dynamically adjusting to text prompts. We also present quantitative comparisons on the ScanNet dataset.
Unsupervised Continual Semantic Adaptation through Neural Rendering
Nov 25, 2022
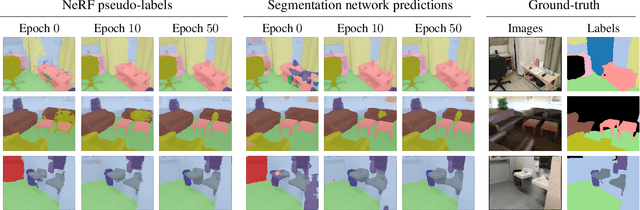
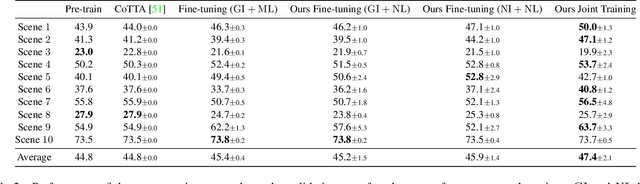

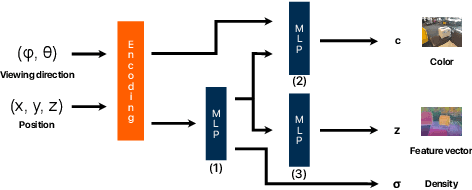
An increasing amount of applications rely on data-driven models that are deployed for perception tasks across a sequence of scenes. Due to the mismatch between training and deployment data, adapting the model on the new scenes is often crucial to obtain good performance. In this work, we study continual multi-scene adaptation for the task of semantic segmentation, assuming that no ground-truth labels are available during deployment and that performance on the previous scenes should be maintained. We propose training a Semantic-NeRF network for each scene by fusing the predictions of a segmentation model and then using the view-consistent rendered semantic labels as pseudo-labels to adapt the model. Through joint training with the segmentation model, the Semantic-NeRF model effectively enables 2D-3D knowledge transfer. Furthermore, due to its compact size, it can be stored in a long-term memory and subsequently used to render data from arbitrary viewpoints to reduce forgetting. We evaluate our approach on ScanNet, where we outperform both a voxel-based baseline and a state-of-the-art unsupervised domain adaptation method.
Continual Learning of Semantic Segmentation using Complementary 2D-3D Data Representations
Nov 03, 2021
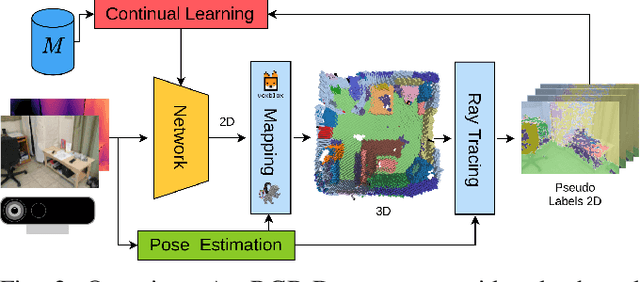
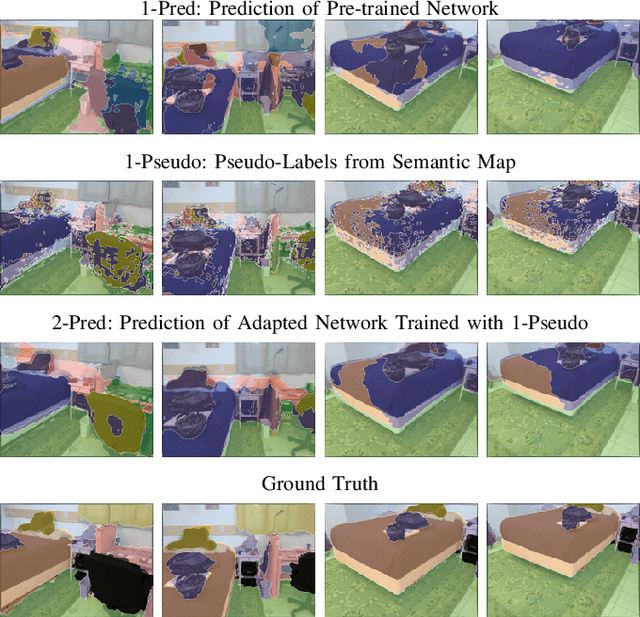

Semantic segmentation networks are usually pre-trained and not updated during deployment. As a consequence, misclassifications commonly occur if the distribution of the training data deviates from the one encountered during the robot's operation. We propose to mitigate this problem by adapting the neural network to the robot's environment during deployment, without any need for external supervision. Leveraging complementary data representations, we generate a supervision signal, by probabilistically accumulating consecutive 2D semantic predictions in a volumetric 3D map. We then retrain the network on renderings of the accumulated semantic map, effectively resolving ambiguities and enforcing multi-view consistency through the 3D representation. To preserve the previously-learned knowledge while performing network adaptation, we employ a continual learning strategy based on experience replay. Through extensive experimental evaluation, we show successful adaptation to real-world indoor scenes both on the ScanNet dataset and on in-house data recorded with an RGB-D sensor. Our method increases the segmentation performance on average by 11.8% compared to the fixed pre-trained neural network, while effectively retaining knowledge from the pre-training dataset.
Self-Improving Semantic Perception on a Construction Robot
May 04, 2021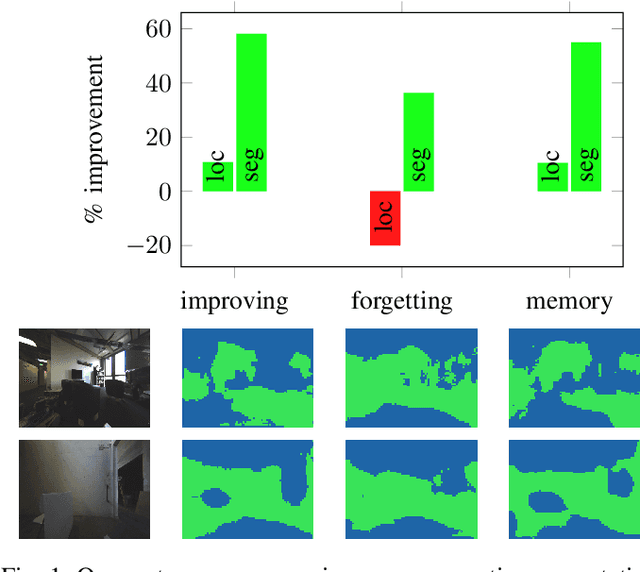
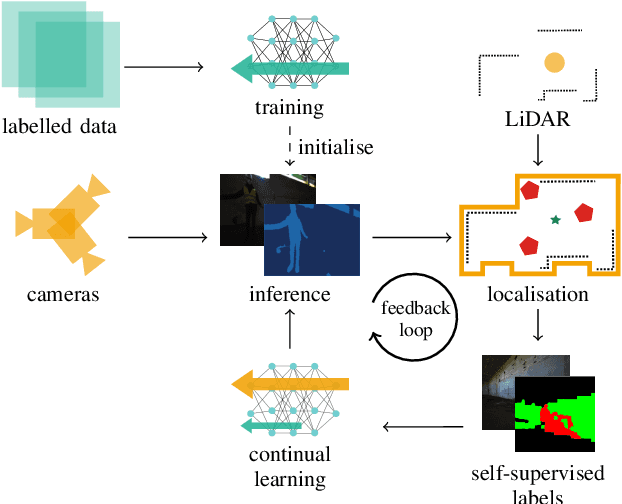
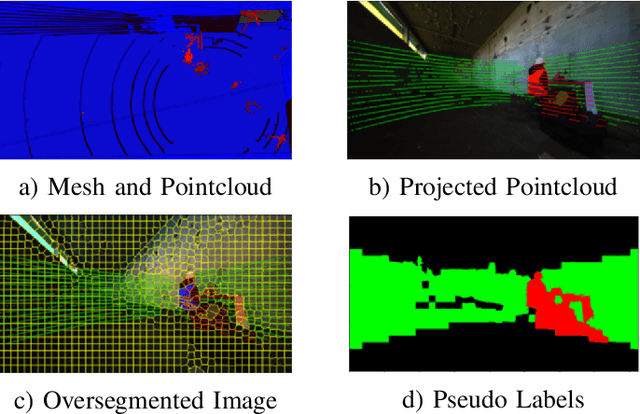

We propose a novel robotic system that can improve its semantic perception during deployment. Contrary to the established approach of learning semantics from large datasets and deploying fixed models, we propose a framework in which semantic models are continuously updated on the robot to adapt to the deployment environments. Our system therefore tightly couples multi-sensor perception and localisation to continuously learn from self-supervised pseudo labels. We study this system in the context of a construction robot registering LiDAR scans of cluttered environments against building models. Our experiments show how the robot's semantic perception improves during deployment and how this translates into improved 3D localisation by filtering the clutter out of the LiDAR scan, even across drastically different environments. We further study the risk of catastrophic forgetting that such a continuous learning setting poses. We find memory replay an effective measure to reduce forgetting and show how the robotic system can improve even when switching between different environments. On average, our system improves by 60% in segmentation and 10% in localisation compared to deployment of a fixed model, and it keeps this improvement up while adapting to further environments.
Primal-Dual Mesh Convolutional Neural Networks
Oct 23, 2020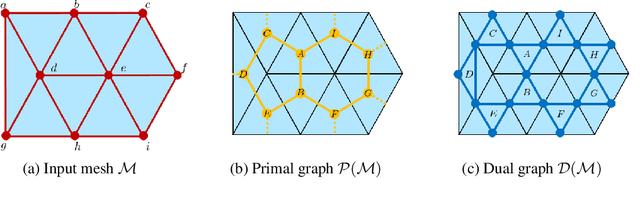
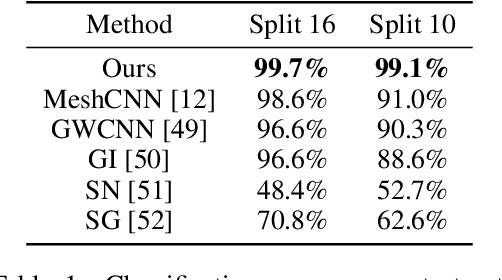
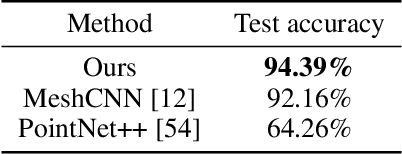
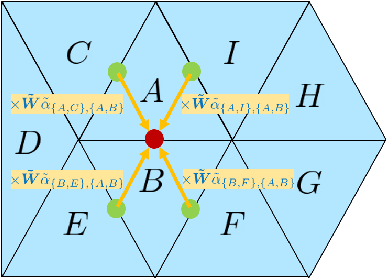
Recent works in geometric deep learning have introduced neural networks that allow performing inference tasks on three-dimensional geometric data by defining convolution, and sometimes pooling, operations on triangle meshes. These methods, however, either consider the input mesh as a graph, and do not exploit specific geometric properties of meshes for feature aggregation and downsampling, or are specialized for meshes, but rely on a rigid definition of convolution that does not properly capture the local topology of the mesh. We propose a method that combines the advantages of both types of approaches, while addressing their limitations: we extend a primal-dual framework drawn from the graph-neural-network literature to triangle meshes, and define convolutions on two types of graphs constructed from an input mesh. Our method takes features for both edges and faces of a 3D mesh as input and dynamically aggregates them using an attention mechanism. At the same time, we introduce a pooling operation with a precise geometric interpretation, that allows handling variations in the mesh connectivity by clustering mesh faces in a task-driven fashion. We provide theoretical insights of our approach using tools from the mesh-simplification literature. In addition, we validate experimentally our method in the tasks of shape classification and shape segmentation, where we obtain comparable or superior performance to the state of the art.
* Accepted to the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada. Code available at: https://github.com/MIT-SPARK/PD-MeshNet