 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember with Confidence: Uncertainty Quantification for Spatio-temporal Memory with Probabilistic Guarantees
Jun 06, 2026Long-horizon robot operation requires spatio-temporal memory to record the environment state and recall it for downstream reasoning. Scene graphs and retrieval-augmented systems ground VLM descriptions to persistent 3D entities with rich semantic descriptions. However, VLM captions are noisy and viewpoint-inconsistent, and existing systems treat them as an oracle with no mechanism to detect unreliable stored descriptions. We introduce object-level semantic uncertainty for multi-view VLM memory: a score that measures object-centric cross-view semantic scatter of captions and identifies semantically unresolved objects. Then, we include our uncertainty scores in an advanced spatial-semantic memory system, that we dub UQ-DAAAM. UQ-DAAAM uses this score to actively refine uncertain objects under a fixed query budget by selecting high-quality views and fusing the resulting multi-view captions into a single object description. We also derive probabilistic guarantees showing that higher-quality candidate views (as selected by our approach) are more likely to reduce uncertainty. Our experiments show that uncertainty quantification can make embodied 4D memory systems more reliable and more effective. In particular, on the OC-NaVQA benchmark, UQ-DAAAM achieves substantially larger uncertainty reduction and better spatio-temporal question answering performance than baselines.
Worth Remembering: Surprise-Gated Robot Episodic Memory
Jun 03, 2026Robots solving generalist tasks need to be able to ground instructions in their past experience, since humans may refer to notable past events when giving a task (e.g., ``Take me to where the chemical spill happened yesterday''). Since memory limits make storing all past events infeasible, long-term robot memory must be selective, ideally retaining only those episodes with high utility for future tasks. However, future tasks are not typically given a priori for generalist robots. To select generically useful memories, we propose Bayesian surprise as a gating mechanism for memory formation. We present an approach to compute surprise in a semantically rich deployment-agnostic latent space provided by V-JEPA-2. Using our gated episodic memory to augment 4D scene graph-based spatial memory, we show a consistent improvement over state-of-the-art benchmarks in robot question answering, outperforming prior robot memory methods by $\geq12\%$ for temporal, spatial, and binary questions, and surpassing the performance of supervised and non-causal methods with an unsupervised causal method in event segmentation tasks.
FOUND-IT: Foundation-model-first Task-driven 3D Scene Graphs with Granularity on Demand
May 25, 2026We present the first approach to build hierarchical task-driven 3D scene graphs of arbitrary indoor or outdoor environments using an uncalibrated monocular camera in real-time. We leverage geometric foundation models to estimate geometric attributes of the scene graph (e.g., object bounding boxes), but we also observe that traversability information (the "places" layer of a scene graph) can be directly reconstructed by adding an extra head to existing geometric foundation models, like VGGT. Our approach is task-driven in the sense that we adjust the granularity of the objects and regions in the map depending on the task; for instance, during a manipulation task, our approach is able to resolve small knobs on a stove, while during a navigation task it can focus on large objects (e.g., the entire stove). However, in a major departure from related work, we consider the realistic case where the list of tasks is not predefined and fixed, but evolves as the robot operates. This naturally allows dealing with complex loco-manipulation tasks, where the robot can dynamically adjust its representation as the task unfolds. We dub the resulting approach FOUND-IT. FOUND-IT also includes an agentic approach to query information in the scene graph. In addition to achieving 79% higher accuracy on the ASHiTA SG3D task grounding benchmark, we demonstrate FOUND-IT runs in real-time on a ground robot using a Jetson Thor. Furthermore, to highlight the robustness of our method, we demonstrate constructing 3D scene graphs on casually captured realtor apartment tours from YouTube. Code will be made available upon publication.
Long-Term Human Trajectory Prediction using 3D Dynamic Scene Graphs
May 01, 2024



We present a novel approach for long-term human trajectory prediction, which is essential for long-horizon robot planning in human-populated environments. State-of-the-art human trajectory prediction methods are limited by their focus on collision avoidance and short-term planning, and their inability to model complex interactions of humans with the environment. In contrast, our approach overcomes these limitations by predicting sequences of human interactions with the environment and using this information to guide trajectory predictions over a horizon of up to 60s. We leverage Large Language Models (LLMs) to predict interactions with the environment by conditioning the LLM prediction on rich contextual information about the scene. This information is given as a 3D Dynamic Scene Graph that encodes the geometry, semantics, and traversability of the environment into a hierarchical representation. We then ground these interaction sequences into multi-modal spatio-temporal distributions over human positions using a probabilistic approach based on continuous-time Markov Chains. To evaluate our approach, we introduce a new semi-synthetic dataset of long-term human trajectories in complex indoor environments, which also includes annotations of human-object interactions. We show in thorough experimental evaluations that our approach achieves a 54% lower average negative log-likelihood (NLL) and a 26.5% lower Best-of-20 displacement error compared to the best non-privileged baselines for a time horizon of 60s.
Geranos: a Novel Tilted-Rotors Aerial Robot for the Transportation of Poles
Dec 04, 2023



In challenging terrains, constructing structures such as antennas and cable-car masts often requires the use of helicopters to transport loads via ropes. The swinging of the load, exacerbated by wind, impairs positioning accuracy, therefore necessitating precise manual placement by ground crews. This increases costs and risk of injuries. Challenging this paradigm, we present Geranos: a specialized multirotor Unmanned Aerial Vehicle (UAV) designed to enhance aerial transportation and assembly. Geranos demonstrates exceptional prowess in accurately positioning vertical poles, achieving this through an innovative integration of load transport and precision. Its unique ring design mitigates the impact of high pole inertia, while a lightweight two-part grasping mechanism ensures secure load attachment without active force. With four primary propellers countering gravity and four auxiliary ones enhancing lateral precision, Geranos achieves comprehensive position and attitude control around hovering. Our experimental demonstration mimicking antenna/cable-car mast installations showcases Geranos ability in stacking poles (3 kg, 2 m long) with remarkable sub-5 cm placement accuracy, without the need of human manual intervention.
ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
Nov 05, 2023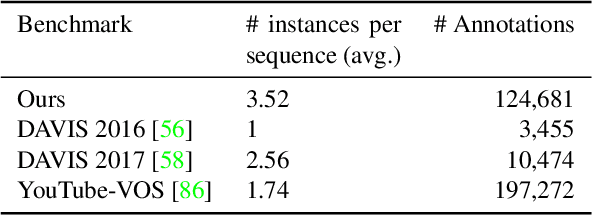

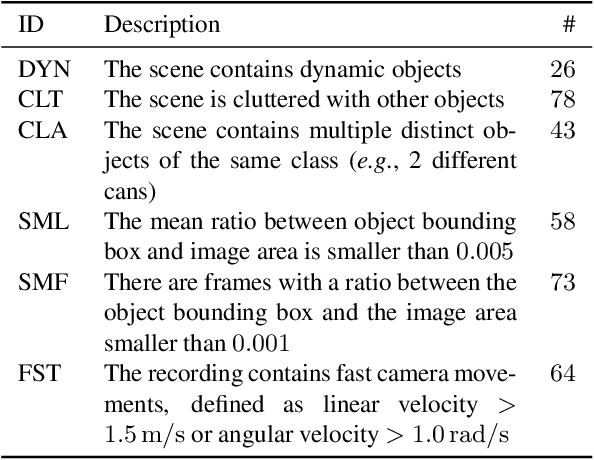
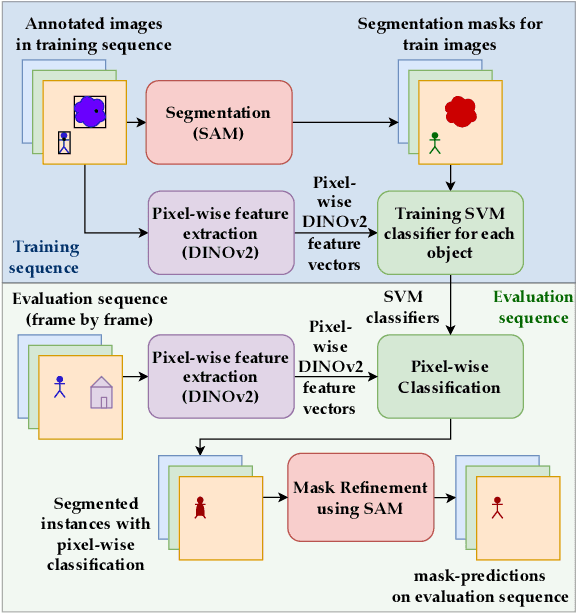
Most object-level mapping systems in use today make use of an upstream learned object instance segmentation model. If we want to teach them about a new object or segmentation class, we need to build a large dataset and retrain the system. To build spatial AI systems that can quickly be taught about new objects, we need to effectively solve the problem of single-shot object detection, instance segmentation and re-identification. So far there is neither a method fulfilling all of these requirements in unison nor a benchmark that could be used to test such a method. Addressing this, we propose ISAR, a benchmark and baseline method for single- and few-shot object Instance Segmentation And Re-identification, in an effort to accelerate the development of algorithms that can robustly detect, segment, and re-identify objects from a single or a few sparse training examples. We provide a semi-synthetic dataset of video sequences with ground-truth semantic annotations, a standardized evaluation pipeline, and a baseline method. Our benchmark aligns with the emerging research trend of unifying Multi-Object Tracking, Video Object Segmentation, and Re-identification.