 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Mapping for Evolving Scenes
Jun 07, 2025Mapping systems with novel view synthesis (NVS) capabilities are widely used in computer vision, with augmented reality, robotics, and autonomous driving applications. Most notably, 3D Gaussian Splatting-based systems show high NVS performance; however, many current approaches are limited to static scenes. While recent works have started addressing short-term dynamics (motion within the view of the camera), long-term dynamics (the scene evolving through changes out of view) remain less explored. To overcome this limitation, we introduce a dynamic scene adaptation mechanism that continuously updates the 3D representation to reflect the latest changes. In addition, since maintaining geometric and semantic consistency remains challenging due to stale observations disrupting the reconstruction process, we propose a novel keyframe management mechanism that discards outdated observations while preserving as much information as possible. We evaluate Gaussian Mapping for Evolving Scenes (GaME) on both synthetic and real-world datasets and find it to be more accurate than the state of the art.
Traversing Mars: Cooperative Informative Path Planning to Efficiently Navigate Unknown Scenes
Jun 12, 2024



The ability to traverse an unknown environment is crucial for autonomous robot operations. However, due to the limited sensing capabilities and system constraints, approaching this problem with a single robot agent can be slow, costly, and unsafe. For example, in planetary exploration missions, the wear on the wheels of a rover from abrasive terrain should be minimized at all costs as reparations are infeasible. On the other hand, utilizing a scouting robot such as a micro aerial vehicle (MAV) has the potential to reduce wear and time costs and increasing safety of a follower robot. This work proposes a novel cooperative IPP framework that allows a scout (e.g., an MAV) to efficiently explore the minimum-cost-path for a follower (e.g., a rover) to reach the goal. We derive theoretic guarantees for our algorithm, and prove that the algorithm always terminates, always finds the optimal path if it exists, and terminates early when the found path is shown to be optimal or infeasible. We show in thorough experimental evaluation that the guarantees hold in practice, and that our algorithm is 22.5% quicker to find the optimal path and 15% quicker to terminate compared to existing methods.
Long-Term Human Trajectory Prediction using 3D Dynamic Scene Graphs
May 01, 2024



We present a novel approach for long-term human trajectory prediction, which is essential for long-horizon robot planning in human-populated environments. State-of-the-art human trajectory prediction methods are limited by their focus on collision avoidance and short-term planning, and their inability to model complex interactions of humans with the environment. In contrast, our approach overcomes these limitations by predicting sequences of human interactions with the environment and using this information to guide trajectory predictions over a horizon of up to 60s. We leverage Large Language Models (LLMs) to predict interactions with the environment by conditioning the LLM prediction on rich contextual information about the scene. This information is given as a 3D Dynamic Scene Graph that encodes the geometry, semantics, and traversability of the environment into a hierarchical representation. We then ground these interaction sequences into multi-modal spatio-temporal distributions over human positions using a probabilistic approach based on continuous-time Markov Chains. To evaluate our approach, we introduce a new semi-synthetic dataset of long-term human trajectories in complex indoor environments, which also includes annotations of human-object interactions. We show in thorough experimental evaluations that our approach achieves a 54% lower average negative log-likelihood (NLL) and a 26.5% lower Best-of-20 displacement error compared to the best non-privileged baselines for a time horizon of 60s.
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Apr 29, 2024



Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
Khronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environments
Feb 21, 2024



Perceiving and understanding highly dynamic and changing environments is a crucial capability for robot autonomy. While large strides have been made towards developing dynamic SLAM approaches that estimate the robot pose accurately, a lesser emphasis has been put on the construction of dense spatio-temporal representations of the robot environment. A detailed understanding of the scene and its evolution through time is crucial for long-term robot autonomy and essential to tasks that require long-term reasoning, such as operating effectively in environments shared with humans and other agents and thus are subject to short and long-term dynamics. To address this challenge, this work defines the Spatio-temporal Metric-semantic SLAM (SMS) problem, and presents a framework to factorize and solve it efficiently. We show that the proposed factorization suggests a natural organization of a spatio-temporal perception system, where a fast process tracks short-term dynamics in an active temporal window, while a slower process reasons over long-term changes in the environment using a factor graph formulation. We provide an efficient implementation of the proposed spatio-temporal perception approach, that we call Khronos, and show that it unifies exiting interpretations of short-term and long-term dynamics and is able to construct a dense spatio-temporal map in real-time. We provide simulated and real results, showing that the spatio-temporal maps built by Khronos are an accurate reflection of a 3D scene over time and that Khronos outperforms baselines across multiple metrics. We further validate our approach on two heterogeneous robots in challenging, large-scale real-world environments.
Dynablox: Real-time Detection of Diverse Dynamic Objects in Complex Environments
Apr 21, 2023Real-time detection of moving objects is an essential capability for robots acting autonomously in dynamic environments. We thus propose Dynablox, a novel online mapping-based approach for robust moving object detection in complex environments. The central idea of our approach is to incrementally estimate high confidence free-space areas by modeling and accounting for sensing, state estimation, and mapping limitations during online robot operation. The spatio-temporally conservative free space estimate enables robust detection of moving objects without making any assumptions on the appearance of objects or environments. This allows deployment in complex scenes such as multi-storied buildings or staircases, and for diverse moving objects such as people carrying various items, doors swinging or even balls rolling around. We thoroughly evaluate our approach on real-world data sets, achieving 86% IoU at 17 FPS in typical robotic settings. The method outperforms a recent appearance-based classifier and approaches the performance of offline methods. We demonstrate its generality on a novel data set with rare moving objects in complex environments. We make our efficient implementation and the novel data set available as open-source.
3D VSG: Long-term Semantic Scene Change Prediction through 3D Variable Scene Graphs
Sep 16, 2022

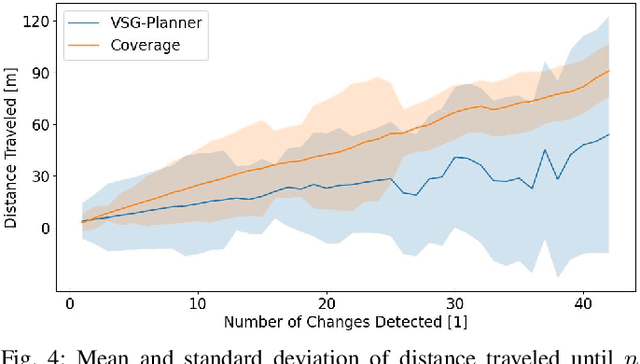
Numerous applications require robots to operate in environments shared with other agents such as humans or other robots. However, such shared scenes are typically subject to different kinds of long-term semantic scene changes. The ability to model and predict such changes is thus crucial for robot autonomy. In this work, we formalize the task of semantic scene variability estimation and identify three main varieties of semantic scene change: changes in the position of an object, its semantic state, or the composition of a scene as a whole. To represent this variability, we propose the Variable Scene Graph (VSG), which augments existing 3D Scene Graph (SG) representations with the variability attribute, representing the likelihood of discrete long-term change events. We present a novel method, DeltaVSG, to estimate the variability of VSGs in a supervised fashion. We evaluate our method on the 3RScan long-term dataset, showing notable improvements in this novel task over existing approaches. Our method DeltaVSG achieves a precision of 72.2% and recall of 66.8%, often mimicking human intuition about how indoor scenes change over time. We further show the utility of VSG predictions in the task of active robotic change detection, speeding up task completion by 62.4% compared to a scene-change-unaware planner. We make our code available as open-source.
Incremental 3D Scene Completion for Safe and Efficient Exploration Mapping and Planning
Aug 17, 2022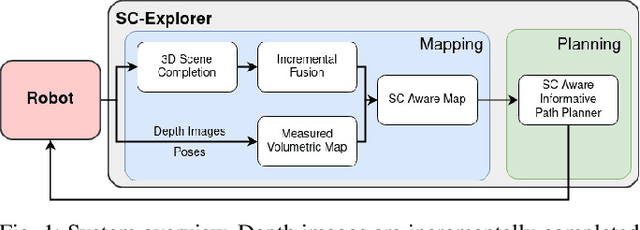

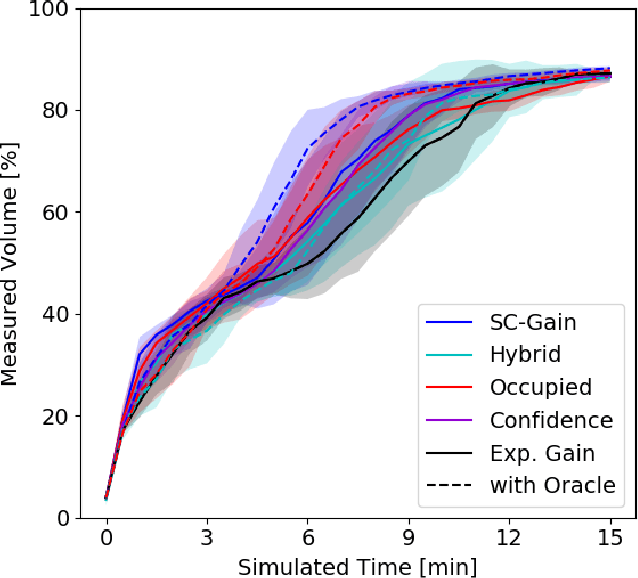
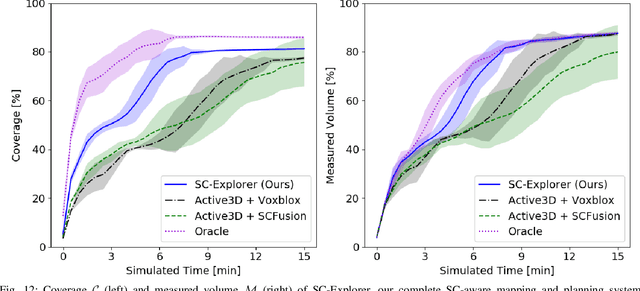
Exploration of unknown environments is a fundamental problem in robotics and an essential component in numerous applications of autonomous systems. A major challenge in exploring unknown environments is that the robot has to plan with the limited information available at each time step. While most current approaches rely on heuristics and assumption to plan paths based on these partial observations, we instead propose a novel way to integrate deep learning into exploration by leveraging 3D scene completion for informed, safe, and interpretable exploration mapping and planning. Our approach, SC-Explorer, combines scene completion using a novel incremental fusion mechanism and a newly proposed hierarchical multi-layer mapping approach, to guarantee safety and efficiency of the robot. We further present an informative path planning method, leveraging the capabilities of our mapping approach and a novel scene-completion-aware information gain. While our method is generally applicable, we evaluate it in the use case of a Micro Aerial Vehicle (MAV). We thoroughly study each component in high-fidelity simulation experiments using only mobile hardware, and show that our method can speed up coverage of an environment by 73% compared to the baselines with only minimal reduction in map accuracy. Even if scene completions are not included in the final map, we show that they can be used to guide the robot to choose more informative paths, speeding up the measurement of the scene with the robot's sensors by 35%. We make our methods available as open-source.
Embodied Active Domain Adaptation for Semantic Segmentation via Informative Path Planning
Mar 01, 2022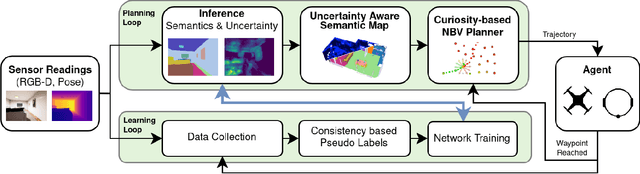
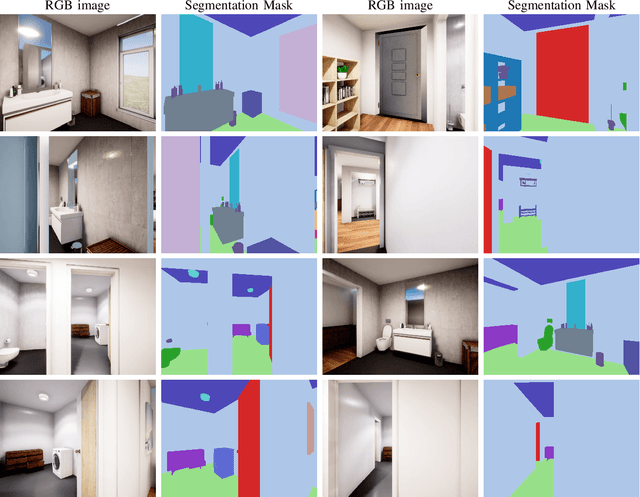


This work presents an embodied agent that can adapt its semantic segmentation network to new indoor environments in a fully autonomous way. Because semantic segmentation networks fail to generalize well to unseen environments, the agent collects images of the new environment which are then used for self-supervised domain adaptation. We formulate this as an informative path planning problem, and present a novel information gain that leverages uncertainty extracted from the semantic model to safely collect relevant data. As domain adaptation progresses, these uncertainties change over time and the rapid learning feedback of our system drives the agent to collect different data. Experiments show that our method adapts to new environments faster and with higher final performance compared to an exploration objective, and can successfully be deployed to real-world environments on physical robots.
Fast and Compute-efficient Sampling-based Local Exploration Planning via Distribution Learning
Feb 28, 2022
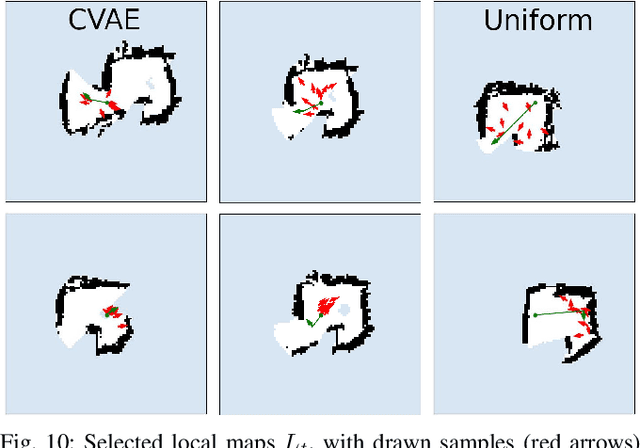


Exploration is a fundamental problem in robotics. While sampling-based planners have shown high performance, they are oftentimes compute intensive and can exhibit high variance. To this end, we propose to directly learn the underlying distribution of informative views based on the spatial context in the robot's map. We further explore a variety of methods to also learn the information gain. We show in thorough experimental evaluation that our proposed system improves exploration performance by up to 28\% over classical methods, and find that learning the gains in addition to the sampling distribution can provide favorable performance vs. compute trade-offs for compute-constrained systems. We demonstrate in simulation and on a low-cost mobile robot that our system generalizes well to varying environments.