 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Mapping for Evolving Scenes
Jun 07, 2025Mapping systems with novel view synthesis (NVS) capabilities are widely used in computer vision, with augmented reality, robotics, and autonomous driving applications. Most notably, 3D Gaussian Splatting-based systems show high NVS performance; however, many current approaches are limited to static scenes. While recent works have started addressing short-term dynamics (motion within the view of the camera), long-term dynamics (the scene evolving through changes out of view) remain less explored. To overcome this limitation, we introduce a dynamic scene adaptation mechanism that continuously updates the 3D representation to reflect the latest changes. In addition, since maintaining geometric and semantic consistency remains challenging due to stale observations disrupting the reconstruction process, we propose a novel keyframe management mechanism that discards outdated observations while preserving as much information as possible. We evaluate Gaussian Mapping for Evolving Scenes (GaME) on both synthetic and real-world datasets and find it to be more accurate than the state of the art.
MAGiC-SLAM: Multi-Agent Gaussian Globally Consistent SLAM
Nov 25, 2024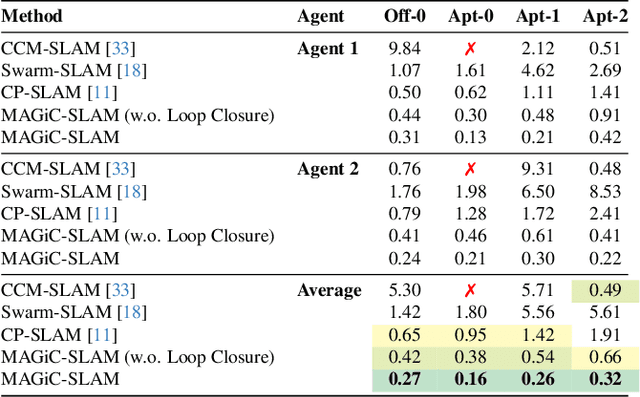
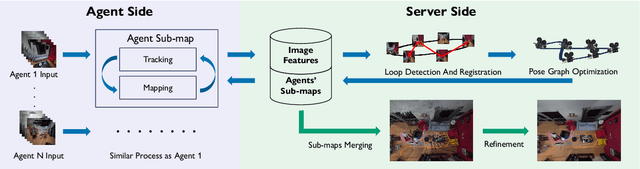
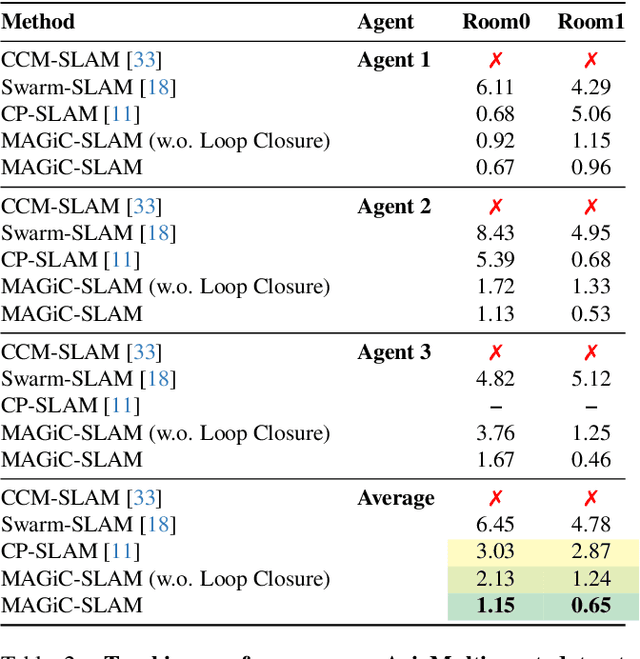

Simultaneous localization and mapping (SLAM) systems with novel view synthesis capabilities are widely used in computer vision, with applications in augmented reality, robotics, and autonomous driving. However, existing approaches are limited to single-agent operation. Recent work has addressed this problem using a distributed neural scene representation. Unfortunately, existing methods are slow, cannot accurately render real-world data, are restricted to two agents, and have limited tracking accuracy. In contrast, we propose a rigidly deformable 3D Gaussian-based scene representation that dramatically speeds up the system. However, improving tracking accuracy and reconstructing a globally consistent map from multiple agents remains challenging due to trajectory drift and discrepancies across agents' observations. Therefore, we propose new tracking and map-merging mechanisms and integrate loop closure in the Gaussian-based SLAM pipeline. We evaluate MAGiC-SLAM on synthetic and real-world datasets and find it more accurate and faster than the state of the art.
FewViewGS: Gaussian Splatting with Few View Matching and Multi-stage Training
Nov 04, 2024



The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.
Loopy-SLAM: Dense Neural SLAM with Loop Closures
Feb 14, 2024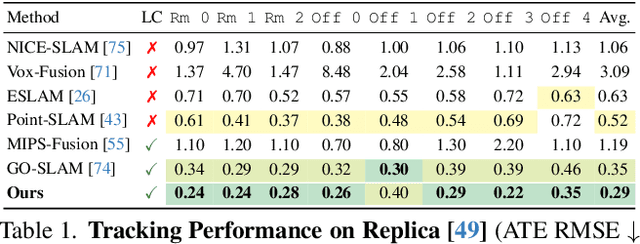
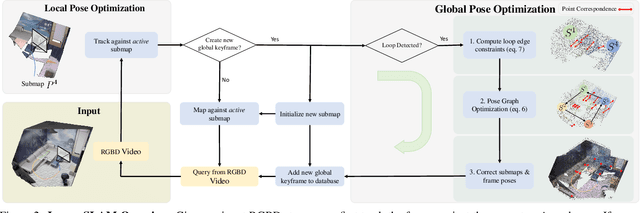
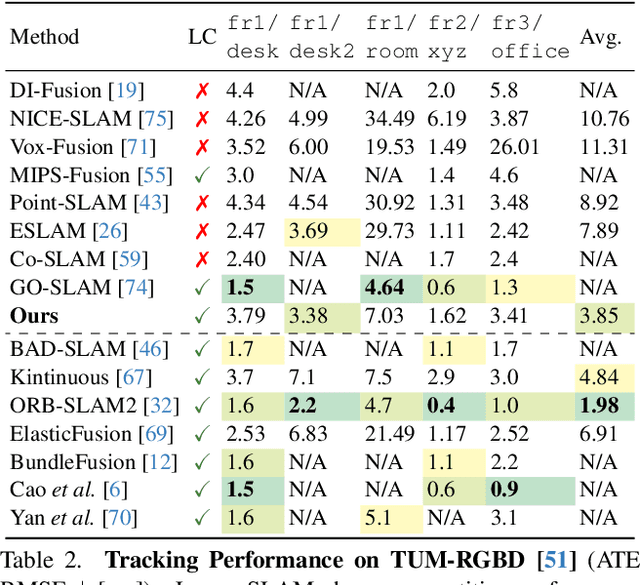

Neural RGBD SLAM techniques have shown promise in dense Simultaneous Localization And Mapping (SLAM), yet face challenges such as error accumulation during camera tracking resulting in distorted maps. In response, we introduce Loopy-SLAM that globally optimizes poses and the dense 3D model. We use frame-to-model tracking using a data-driven point-based submap generation method and trigger loop closures online by performing global place recognition. Robust pose graph optimization is used to rigidly align the local submaps. As our representation is point based, map corrections can be performed efficiently without the need to store the entire history of input frames used for mapping as typically required by methods employing a grid based mapping structure. Evaluation on the synthetic Replica and real-world TUM-RGBD and ScanNet datasets demonstrate competitive or superior performance in tracking, mapping, and rendering accuracy when compared to existing dense neural RGBD SLAM methods. Project page: notchla.github.io/Loopy-SLAM.
Gaussian-SLAM: Photo-realistic Dense SLAM with Gaussian Splatting
Dec 06, 2023
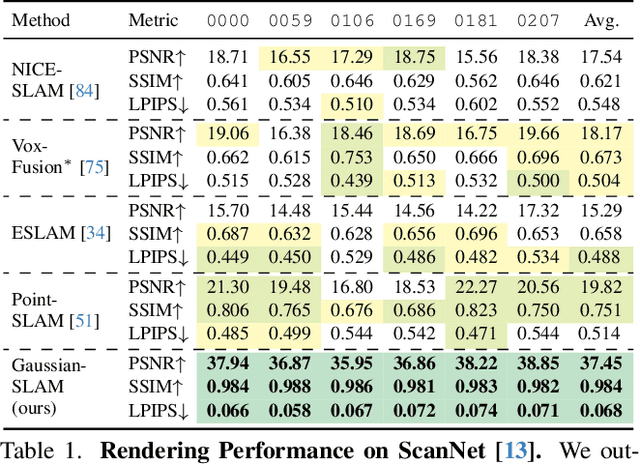


We present a new dense simultaneous localization and mapping (SLAM) method that uses Gaussian splats as a scene representation. The new representation enables interactive-time reconstruction and photo-realistic rendering of real-world and synthetic scenes. We propose novel strategies for seeding and optimizing Gaussian splats to extend their use from multiview offline scenarios to sequential monocular RGBD input data setups. In addition, we extend Gaussian splats to encode geometry and experiment with tracking against this scene representation. Our method achieves state-of-the-art rendering quality on both real-world and synthetic datasets while being competitive in reconstruction performance and runtime.
Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
Oct 14, 2022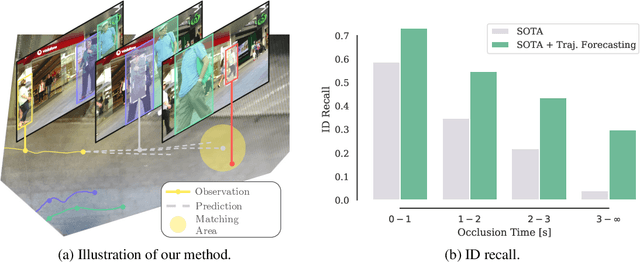
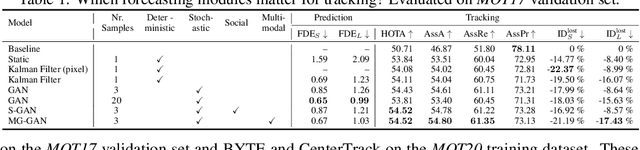
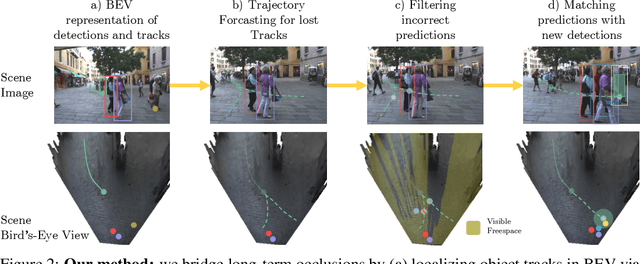
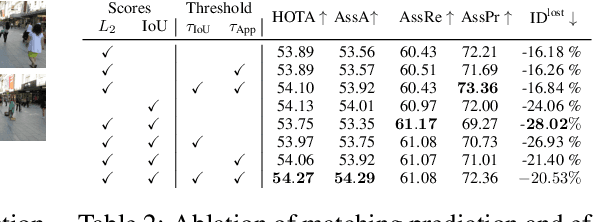
Recent developments in monocular multi-object tracking have been very successful in tracking visible objects and bridging short occlusion gaps, mainly relying on data-driven appearance models. While we have significantly advanced short-term tracking performance, bridging longer occlusion gaps remains elusive: state-of-the-art object trackers only bridge less than 10% of occlusions longer than three seconds. We suggest that the missing key is reasoning about future trajectories over a longer time horizon. Intuitively, the longer the occlusion gap, the larger the search space for possible associations. In this paper, we show that even a small yet diverse set of trajectory predictions for moving agents will significantly reduce this search space and thus improve long-term tracking robustness. Our experiments suggest that the crucial components of our approach are reasoning in a bird's-eye view space and generating a small yet diverse set of forecasts while accounting for their localization uncertainty. This way, we can advance state-of-the-art trackers on the MOTChallenge dataset and significantly improve their long-term tracking performance. This paper's source code and experimental data are available at https://github.com/dendorferpatrick/QuoVadis.