 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnblur-SLAM: Dense Neural SLAM for Blurry Inputs
Mar 26, 2026We propose Unblur-SLAM, a novel RGB SLAM pipeline for sharp 3D reconstruction from blurred image inputs. In contrast to previous work, our approach is able to handle different types of blur and demonstrates state-of-the-art performance in the presence of both motion blur and defocus blur. Moreover, we adjust the computation effort with the amount of blur in the input image. As a first stage, our method uses a feed-forward image deblurring model for which we propose a suitable training scheme that can improve both tracking and mapping modules. Frames that are successfully deblurred by the feed-forward network obtain refined poses and depth through local-global multi-view optimization and loop closure. Frames that fail the first stage deblurring are directly modeled through the global 3DGS representation and an additional blur network to model multiple blurred sub-frames and simulate the blur formation process in 3D space, thereby learning sharp details and refined sub-frame poses. Experiments on several real-world datasets demonstrate consistent improvements in both pose estimation and sharp reconstruction results of geometry and texture.
Stronger Semantic Encoders Can Harm Relighting Performance: Probing Visual Priors via Augmented Latent Intrinsics
Feb 01, 2026Image-to-image relighting requires representations that disentangle scene properties from illumination. Recent methods rely on latent intrinsic representations but remain under-constrained and often fail on challenging materials such as metal and glass. A natural hypothesis is that stronger pretrained visual priors should resolve these failures. We find the opposite: features from top-performing semantic encoders often degrade relighting quality, revealing a fundamental trade-off between semantic abstraction and photometric fidelity. We study this trade-off and introduce Augmented Latent Intrinsics (ALI), which balances semantic context and dense photometric structure by fusing features from a pixel-aligned visual encoder into a latent-intrinsic framework, together with a self-supervised refinement strategy to mitigate the scarcity of paired real-world data. Trained only on unlabeled real-world image pairs and paired with a dense, pixel-aligned visual prior, ALI achieves strong improvements in relighting, with the largest gains on complex, specular materials. Project page: https:\\augmented-latent-intrinsics.github.io
Grab-3D: Detecting AI-Generated Videos from 3D Geometric Temporal Consistency
Dec 15, 2025Recent advances in diffusion-based generation techniques enable AI models to produce highly realistic videos, heightening the need for reliable detection mechanisms. However, existing detection methods provide only limited exploration of the 3D geometric patterns present in generated videos. In this paper, we use vanishing points as an explicit representation of 3D geometry patterns, revealing fundamental discrepancies in geometric consistency between real and AI-generated videos. We introduce Grab-3D, a geometry-aware transformer framework for detecting AI-generated videos based on 3D geometric temporal consistency. To enable reliable evaluation, we construct an AI-generated video dataset of static scenes, allowing stable 3D geometric feature extraction. We propose a geometry-aware transformer equipped with geometric positional encoding, temporal-geometric attention, and an EMA-based geometric classifier head to explicitly inject 3D geometric awareness into temporal modeling. Experiments demonstrate that Grab-3D significantly outperforms state-of-the-art detectors, achieving robust cross-domain generalization to unseen generators.
LumiNet: Latent Intrinsics Meets Diffusion Models for Indoor Scene Relighting
Dec 03, 2024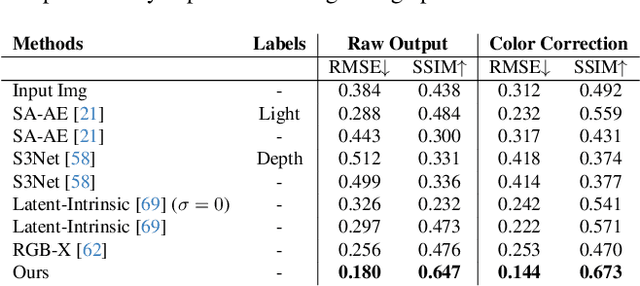



We introduce LumiNet, a novel architecture that leverages generative models and latent intrinsic representations for effective lighting transfer. Given a source image and a target lighting image, LumiNet synthesizes a relit version of the source scene that captures the target's lighting. Our approach makes two key contributions: a data curation strategy from the StyleGAN-based relighting model for our training, and a modified diffusion-based ControlNet that processes both latent intrinsic properties from the source image and latent extrinsic properties from the target image. We further improve lighting transfer through a learned adaptor (MLP) that injects the target's latent extrinsic properties via cross-attention and fine-tuning. Unlike traditional ControlNet, which generates images with conditional maps from a single scene, LumiNet processes latent representations from two different images - preserving geometry and albedo from the source while transferring lighting characteristics from the target. Experiments demonstrate that our method successfully transfers complex lighting phenomena including specular highlights and indirect illumination across scenes with varying spatial layouts and materials, outperforming existing approaches on challenging indoor scenes using only images as input.
FewViewGS: Gaussian Splatting with Few View Matching and Multi-stage Training
Nov 04, 2024



The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.
RealDiff: Real-world 3D Shape Completion using Self-Supervised Diffusion Models
Sep 16, 2024



Point cloud completion aims to recover the complete 3D shape of an object from partial observations. While approaches relying on synthetic shape priors achieved promising results in this domain, their applicability and generalizability to real-world data are still limited. To tackle this problem, we propose a self-supervised framework, namely RealDiff, that formulates point cloud completion as a conditional generation problem directly on real-world measurements. To better deal with noisy observations without resorting to training on synthetic data, we leverage additional geometric cues. Specifically, RealDiff simulates a diffusion process at the missing object parts while conditioning the generation on the partial input to address the multimodal nature of the task. We further regularize the training by matching object silhouettes and depth maps, predicted by our method, with the externally estimated ones. Experimental results show that our method consistently outperforms state-of-the-art methods in real-world point cloud completion.
Ray-Distance Volume Rendering for Neural Scene Reconstruction
Aug 28, 2024Existing methods in neural scene reconstruction utilize the Signed Distance Function (SDF) to model the density function. However, in indoor scenes, the density computed from the SDF for a sampled point may not consistently reflect its real importance in volume rendering, often due to the influence of neighboring objects. To tackle this issue, our work proposes a novel approach for indoor scene reconstruction, which instead parameterizes the density function with the Signed Ray Distance Function (SRDF). Firstly, the SRDF is predicted by the network and transformed to a ray-conditioned density function for volume rendering. We argue that the ray-specific SRDF only considers the surface along the camera ray, from which the derived density function is more consistent to the real occupancy than that from the SDF. Secondly, although SRDF and SDF represent different aspects of scene geometries, their values should share the same sign indicating the underlying spatial occupancy. Therefore, this work introduces a SRDF-SDF consistency loss to constrain the signs of the SRDF and SDF outputs. Thirdly, this work proposes a self-supervised visibility task, introducing the physical visibility geometry to the reconstruction task. The visibility task combines prior from predicted SRDF and SDF as pseudo labels, and contributes to generating more accurate 3D geometry. Our method implemented with different representations has been validated on indoor datasets, achieving improved performance in both reconstruction and view synthesis.
Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction
Aug 28, 2024



In addition to color and textural information, geometry provides important cues for 3D scene reconstruction. However, current reconstruction methods only include geometry at the feature level thus not fully exploiting the geometric information. In contrast, this paper proposes a novel geometry integration mechanism for 3D scene reconstruction. Our approach incorporates 3D geometry at three levels, i.e. feature learning, feature fusion, and network supervision. First, geometry-guided feature learning encodes geometric priors to contain view-dependent information. Second, a geometry-guided adaptive feature fusion is introduced which utilizes the geometric priors as a guidance to adaptively generate weights for multiple views. Third, at the supervision level, taking the consistency between 2D and 3D normals into account, a consistent 3D normal loss is designed to add local constraints. Large-scale experiments are conducted on the ScanNet dataset, showing that volumetric methods with our geometry integration mechanism outperform state-of-the-art methods quantitatively as well as qualitatively. Volumetric methods with ours also show good generalization on the 7-Scenes and TUM RGB-D datasets.
SceneTeller: Language-to-3D Scene Generation
Jul 30, 2024Designing high-quality indoor 3D scenes is important in many practical applications, such as room planning or game development. Conventionally, this has been a time-consuming process which requires both artistic skill and familiarity with professional software, making it hardly accessible for layman users. However, recent advances in generative AI have established solid foundation for democratizing 3D design. In this paper, we propose a pioneering approach for text-based 3D room design. Given a prompt in natural language describing the object placement in the room, our method produces a high-quality 3D scene corresponding to it. With an additional text prompt the users can change the appearance of the entire scene or of individual objects in it. Built using in-context learning, CAD model retrieval and 3D-Gaussian-Splatting-based stylization, our turnkey pipeline produces state-of-the-art 3D scenes, while being easy to use even for novices. Our project page is available at https://sceneteller.github.io/.
Retinex-Diffusion: On Controlling Illumination Conditions in Diffusion Models via Retinex Theory
Jul 29, 2024This paper introduces a novel approach to illumination manipulation in diffusion models, addressing the gap in conditional image generation with a focus on lighting conditions. We conceptualize the diffusion model as a black-box image render and strategically decompose its energy function in alignment with the image formation model. Our method effectively separates and controls illumination-related properties during the generative process. It generates images with realistic illumination effects, including cast shadow, soft shadow, and inter-reflections. Remarkably, it achieves this without the necessity for learning intrinsic decomposition, finding directions in latent space, or undergoing additional training with new datasets.