 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealDiff: Real-world 3D Shape Completion using Self-Supervised Diffusion Models
Sep 16, 2024



Point cloud completion aims to recover the complete 3D shape of an object from partial observations. While approaches relying on synthetic shape priors achieved promising results in this domain, their applicability and generalizability to real-world data are still limited. To tackle this problem, we propose a self-supervised framework, namely RealDiff, that formulates point cloud completion as a conditional generation problem directly on real-world measurements. To better deal with noisy observations without resorting to training on synthetic data, we leverage additional geometric cues. Specifically, RealDiff simulates a diffusion process at the missing object parts while conditioning the generation on the partial input to address the multimodal nature of the task. We further regularize the training by matching object silhouettes and depth maps, predicted by our method, with the externally estimated ones. Experimental results show that our method consistently outperforms state-of-the-art methods in real-world point cloud completion.
SceneTeller: Language-to-3D Scene Generation
Jul 30, 2024Designing high-quality indoor 3D scenes is important in many practical applications, such as room planning or game development. Conventionally, this has been a time-consuming process which requires both artistic skill and familiarity with professional software, making it hardly accessible for layman users. However, recent advances in generative AI have established solid foundation for democratizing 3D design. In this paper, we propose a pioneering approach for text-based 3D room design. Given a prompt in natural language describing the object placement in the room, our method produces a high-quality 3D scene corresponding to it. With an additional text prompt the users can change the appearance of the entire scene or of individual objects in it. Built using in-context learning, CAD model retrieval and 3D-Gaussian-Splatting-based stylization, our turnkey pipeline produces state-of-the-art 3D scenes, while being easy to use even for novices. Our project page is available at https://sceneteller.github.io/.
Accurate Training Data for Occupancy Map Prediction in Automated Driving Using Evidence Theory
May 17, 2024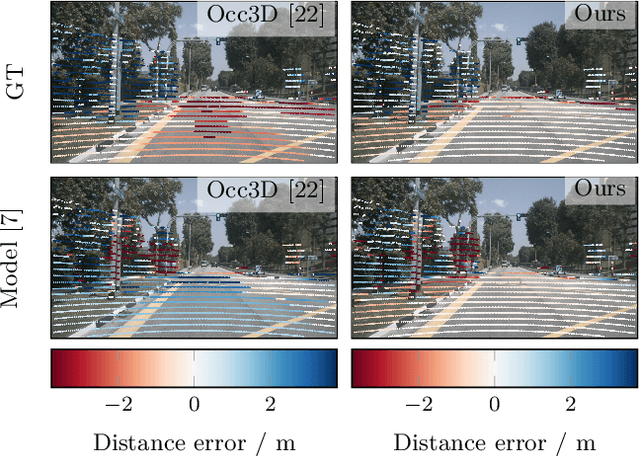
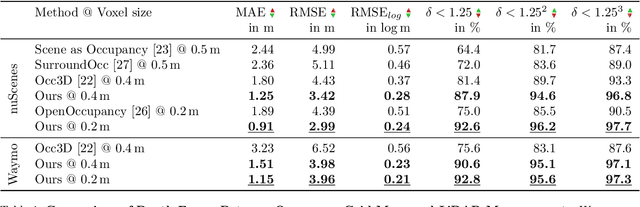
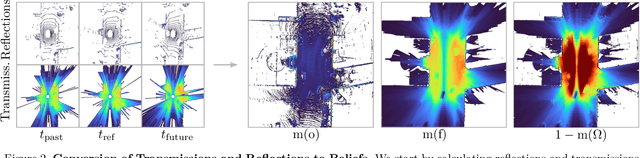
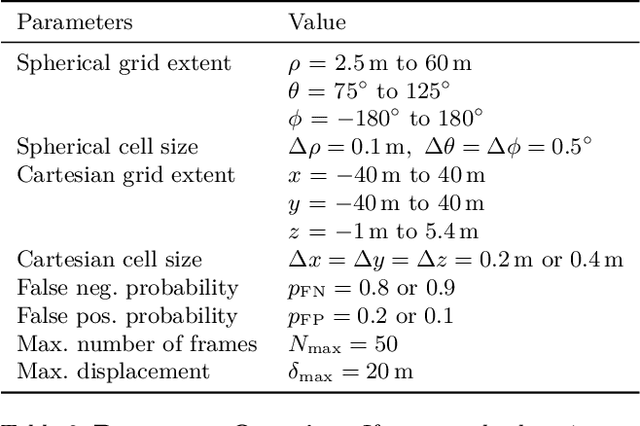
Automated driving fundamentally requires knowledge about the surrounding geometry of the scene. Modern approaches use only captured images to predict occupancy maps that represent the geometry. Training these approaches requires accurate data that may be acquired with the help of LiDAR scanners. We show that the techniques used for current benchmarks and training datasets to convert LiDAR scans into occupancy grid maps yield very low quality, and subsequently present a novel approach using evidence theory that yields more accurate reconstructions. We demonstrate that these are superior by a large margin, both qualitatively and quantitatively, and that we additionally obtain meaningful uncertainty estimates. When converting the occupancy maps back to depth estimates and comparing them with the raw LiDAR measurements, our method yields a MAE improvement of 30% to 52% on nuScenes and 53% on Waymo over other occupancy ground-truth data. Finally, we use the improved occupancy maps to train a state-of-the-art occupancy prediction method and demonstrate that it improves the MAE by 25% on nuScenes.
Histogram-based Deep Learning for Automotive Radar
Mar 06, 2023There are various automotive applications that rely on correctly interpreting point cloud data recorded with radar sensors. We present a deep learning approach for histogram-based processing of such point clouds. Compared to existing methods, the design of our approach is extremely simple: it boils down to computing a point cloud histogram and passing it through a multi-layer perceptron. Our approach matches and surpasses state-of-the-art approaches on the task of automotive radar object type classification. It is also robust to noise that often corrupts radar measurements, and can deal with missing features of single radar reflections. Finally, the design of our approach makes it more interpretable than existing methods, allowing insightful analysis of its decisions.
Fostering Generalization in Single-view 3D Reconstruction by Learning a Hierarchy of Local and Global Shape Priors
Apr 01, 2021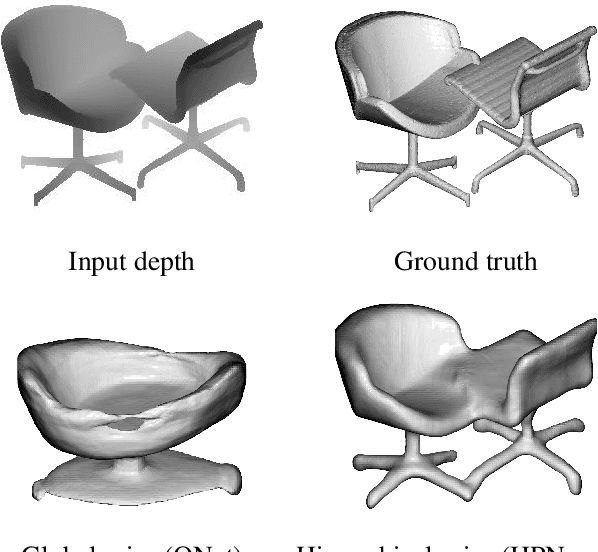
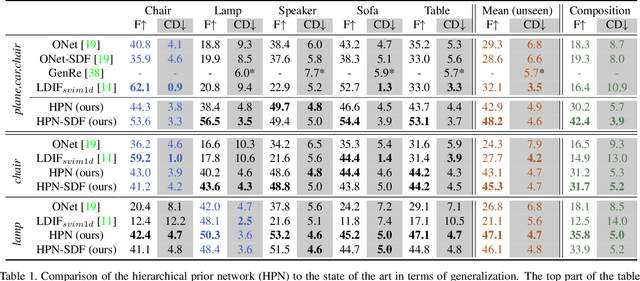
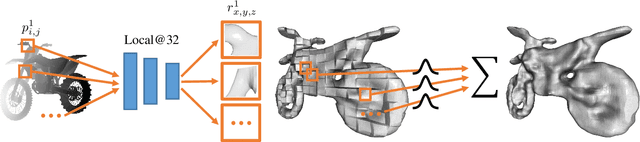
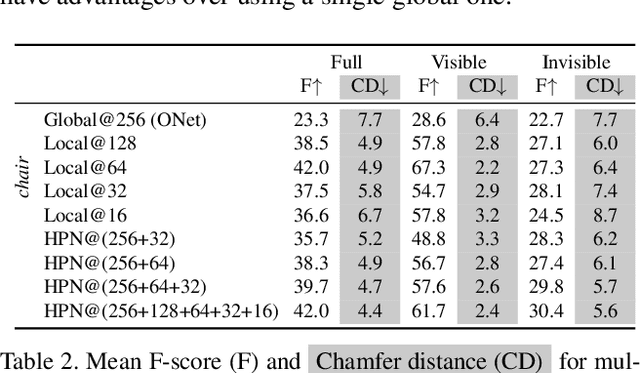
Single-view 3D object reconstruction has seen much progress, yet methods still struggle generalizing to novel shapes unseen during training. Common approaches predominantly rely on learned global shape priors and, hence, disregard detailed local observations. In this work, we address this issue by learning a hierarchy of priors at different levels of locality from ground truth input depth maps. We argue that exploiting local priors allows our method to efficiently use input observations, thus improving generalization in visible areas of novel shapes. At the same time, the combination of local and global priors enables meaningful hallucination of unobserved parts resulting in consistent 3D shapes. We show that the hierarchical approach generalizes much better than the global approach. It generalizes not only between different instances of a class but also across classes and to unseen arrangements of objects.
Parting with Illusions about Deep Active Learning
Dec 11, 2019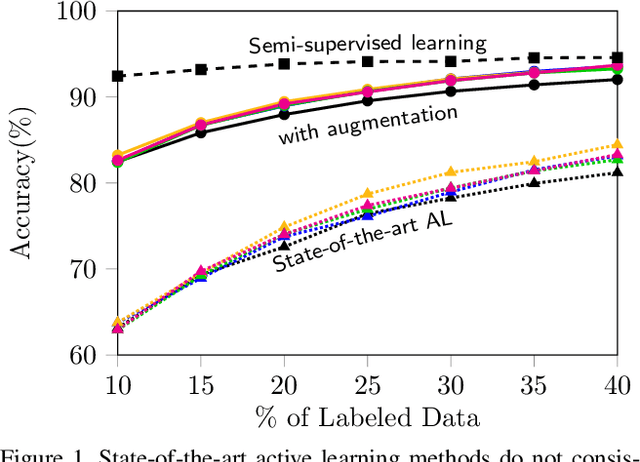
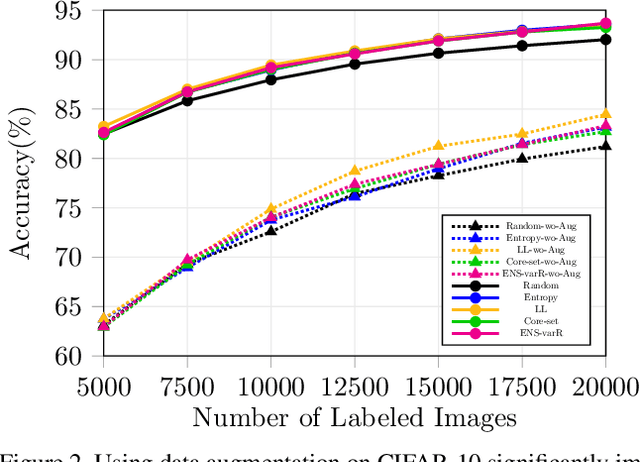
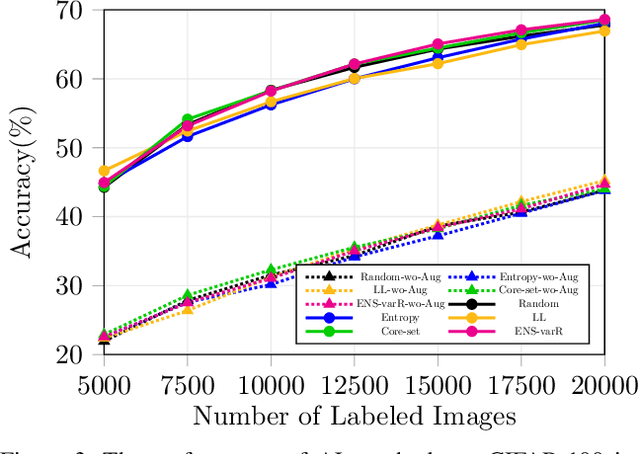
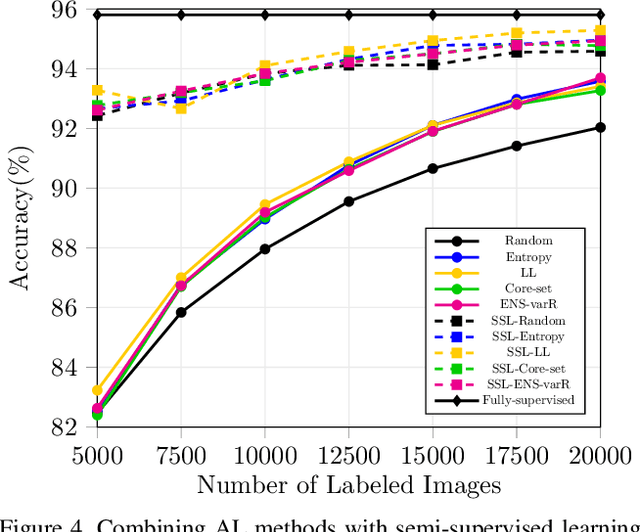
Active learning aims to reduce the high labeling cost involved in training machine learning models on large datasets by efficiently labeling only the most informative samples. Recently, deep active learning has shown success on various tasks. However, the conventional evaluation scheme used for deep active learning is below par. Current methods disregard some apparent parallel work in the closely related fields. Active learning methods are quite sensitive w.r.t. changes in the training procedure like data augmentation. They improve by a large-margin when integrated with semi-supervised learning, but barely perform better than the random baseline. We re-implement various latest active learning approaches for image classification and evaluate them under more realistic settings. We further validate our findings for semantic segmentation. Based on our observations, we realistically assess the current state of the field and propose a more suitable evaluation protocol.
Self-supervised 3D Shape and Viewpoint Estimation from Single Images for Robotics
Oct 17, 2019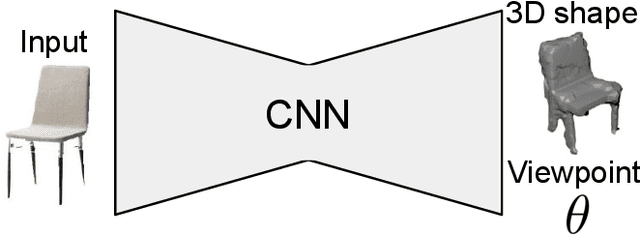
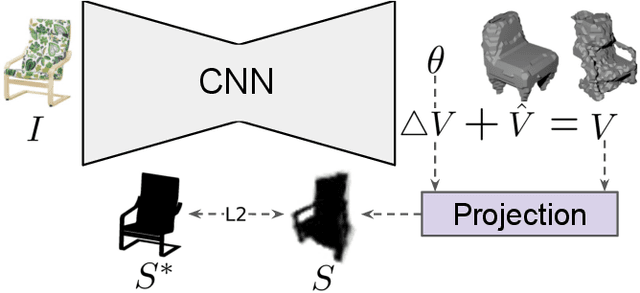
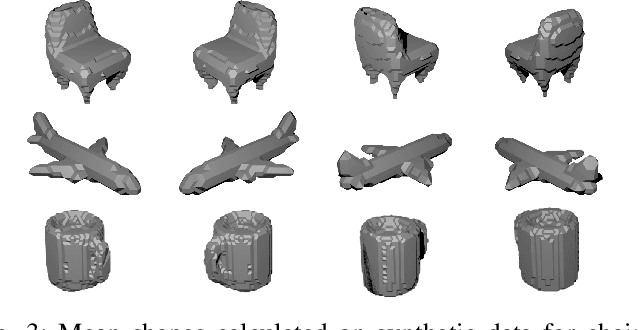

We present a convolutional neural network for joint 3D shape prediction and viewpoint estimation from a single input image. During training, our network gets the learning signal from a silhouette of an object in the input image - a form of self-supervision. It does not require ground truth data for 3D shapes and the viewpoints. Because it relies on such a weak form of supervision, our approach can easily be applied to real-world data. We demonstrate that our method produces reasonable qualitative and quantitative results on natural images for both shape estimation and viewpoint prediction. Unlike previous approaches, our method does not require multiple views of the same object instance in the dataset, which significantly expands the applicability in practical robotics scenarios. We showcase it by using the hallucinated shapes to improve the performance on the task of grasping real-world objects both in simulation and with a PR2 robot.
Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
Aug 15, 2019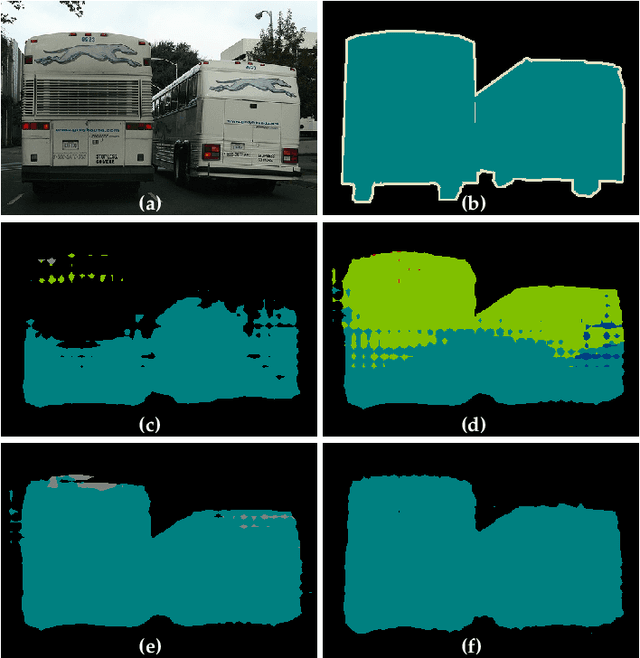
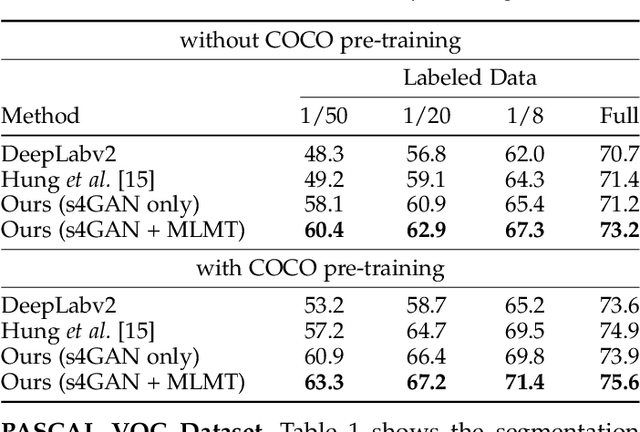
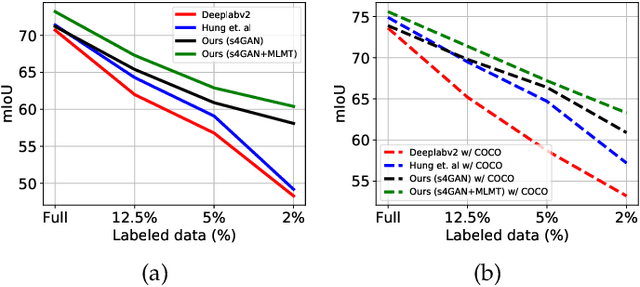
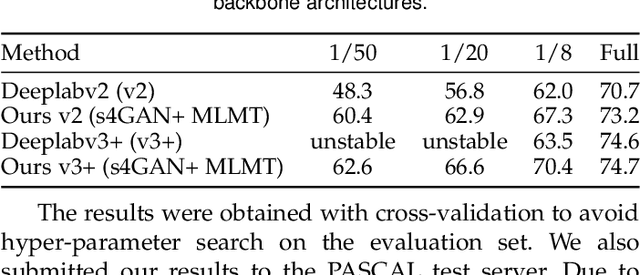
The ability to understand visual information from limited labeled data is an important aspect of machine learning. While image-level classification has been extensively studied in a semi-supervised setting, dense pixel-level classification with limited data has only drawn attention recently. In this work, we propose an approach for semi-supervised semantic segmentation that learns from limited pixel-wise annotated samples while exploiting additional annotation-free images. It uses two network branches that link semi-supervised classification with semi-supervised segmentation including self-training. The dual-branch approach reduces both the low-level and the high-level artifacts typical when training with few labels. The approach attains significant improvement over existing methods, especially when trained with very few labeled samples. On several standard benchmarks - PASCAL VOC 2012, PASCAL-Context, and Cityscapes - the approach achieves new state-of-the-art in semi-supervised learning.
What Do Single-view 3D Reconstruction Networks Learn?
May 09, 2019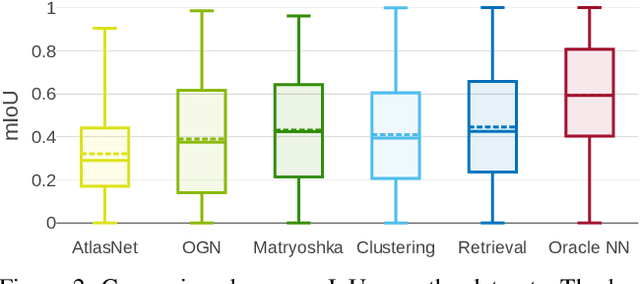
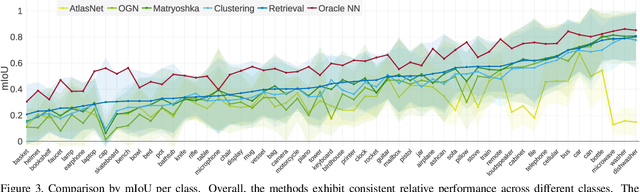
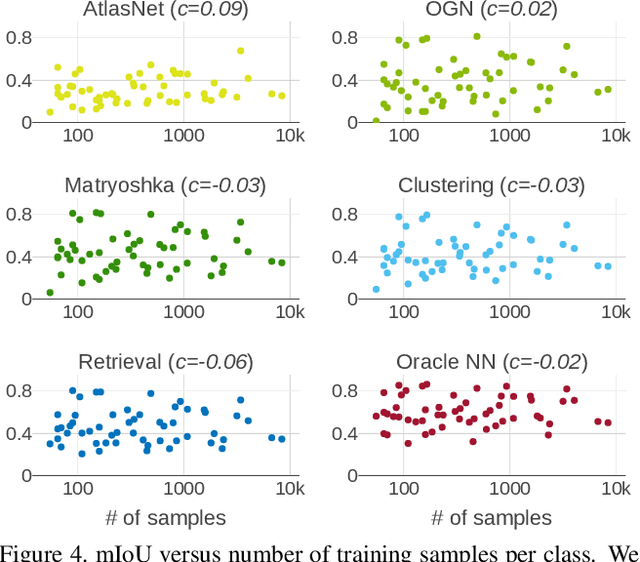

Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
Tangent Convolutions for Dense Prediction in 3D
Jul 06, 2018
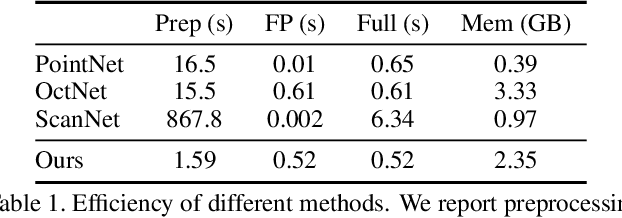
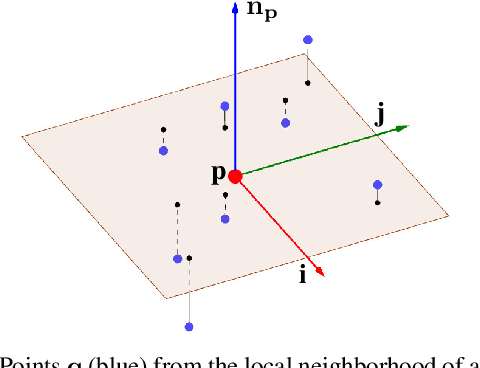
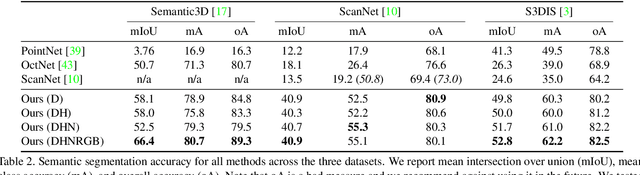
We present an approach to semantic scene analysis using deep convolutional networks. Our approach is based on tangent convolutions - a new construction for convolutional networks on 3D data. In contrast to volumetric approaches, our method operates directly on surface geometry. Crucially, the construction is applicable to unstructured point clouds and other noisy real-world data. We show that tangent convolutions can be evaluated efficiently on large-scale point clouds with millions of points. Using tangent convolutions, we design a deep fully-convolutional network for semantic segmentation of 3D point clouds, and apply it to challenging real-world datasets of indoor and outdoor 3D environments. Experimental results show that the presented approach outperforms other recent deep network constructions in detailed analysis of large 3D scenes.