 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangent Convolutions for Dense Prediction in 3D
Jul 06, 2018
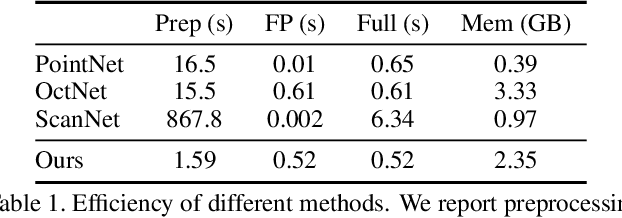
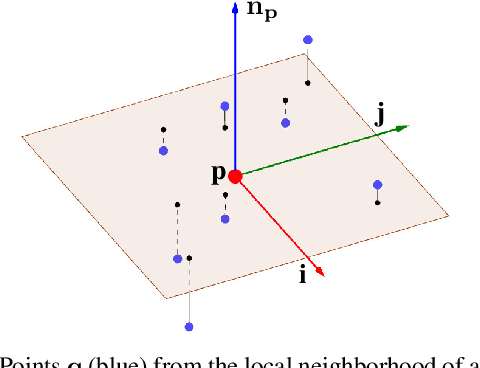
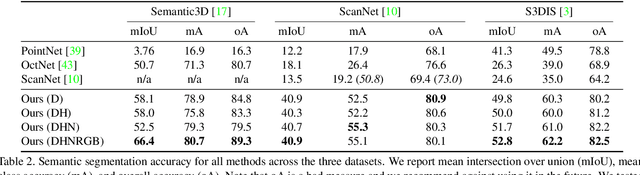
We present an approach to semantic scene analysis using deep convolutional networks. Our approach is based on tangent convolutions - a new construction for convolutional networks on 3D data. In contrast to volumetric approaches, our method operates directly on surface geometry. Crucially, the construction is applicable to unstructured point clouds and other noisy real-world data. We show that tangent convolutions can be evaluated efficiently on large-scale point clouds with millions of points. Using tangent convolutions, we design a deep fully-convolutional network for semantic segmentation of 3D point clouds, and apply it to challenging real-world datasets of indoor and outdoor 3D environments. Experimental results show that the presented approach outperforms other recent deep network constructions in detailed analysis of large 3D scenes.
Open3D: A Modern Library for 3D Data Processing
Jan 30, 2018
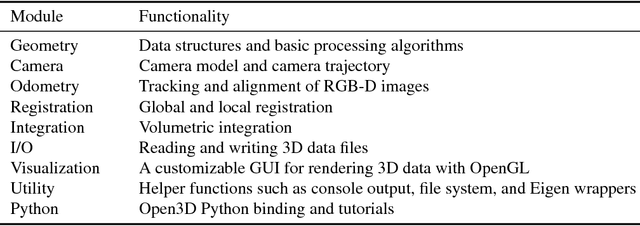
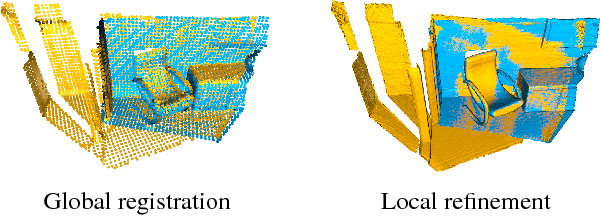
Open3D is an open-source library that supports rapid development of software that deals with 3D data. The Open3D frontend exposes a set of carefully selected data structures and algorithms in both C++ and Python. The backend is highly optimized and is set up for parallelization. Open3D was developed from a clean slate with a small and carefully considered set of dependencies. It can be set up on different platforms and compiled from source with minimal effort. The code is clean, consistently styled, and maintained via a clear code review mechanism. Open3D has been used in a number of published research projects and is actively deployed in the cloud. We welcome contributions from the open-source community.
Learning Compact Geometric Features
Sep 15, 2017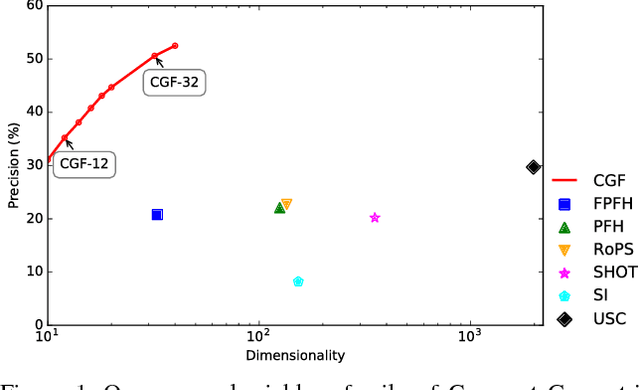

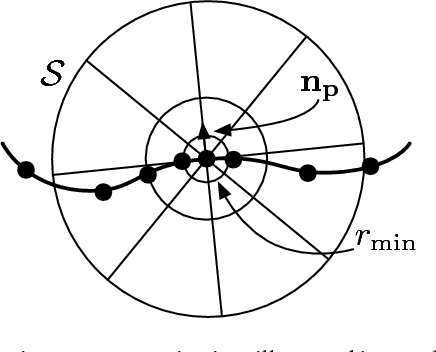
We present an approach to learning features that represent the local geometry around a point in an unstructured point cloud. Such features play a central role in geometric registration, which supports diverse applications in robotics and 3D vision. Current state-of-the-art local features for unstructured point clouds have been manually crafted and none combines the desirable properties of precision, compactness, and robustness. We show that features with these properties can be learned from data, by optimizing deep networks that map high-dimensional histograms into low-dimensional Euclidean spaces. The presented approach yields a family of features, parameterized by dimension, that are both more compact and more accurate than existing descriptors.
A Large Dataset of Object Scans
May 05, 2016

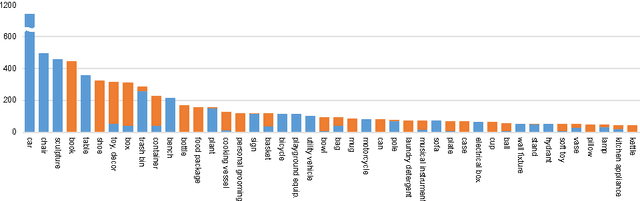
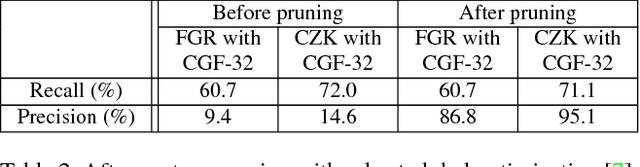
We have created a dataset of more than ten thousand 3D scans of real objects. To create the dataset, we recruited 70 operators, equipped them with consumer-grade mobile 3D scanning setups, and paid them to scan objects in their environments. The operators scanned objects of their choosing, outside the laboratory and without direct supervision by computer vision professionals. The result is a large and diverse collection of object scans: from shoes, mugs, and toys to grand pianos, construction vehicles, and large outdoor sculptures. We worked with an attorney to ensure that data acquisition did not violate privacy constraints. The acquired data was irrevocably placed in the public domain and is available freely at http://redwood-data.org/3dscan .