 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
Apr 09, 2026Designing robot morphologies and kinematics has traditionally relied on human intuition, with little systematic foundation. Motion-design co-optimization offers a promising path toward automation, but two major challenges remain: (i) the vast, unstructured design space and (ii) the difficulty of constructing task-specific loss functions. We propose a new paradigm that minimizes human involvement by (i) learning the design search space from existing mechanical designs, rather than hand-crafting it, and (ii) defining the loss directly from human motion data via motion retargeting and Procrustes analysis. Using screw-theory-based joint axis representation and isometric manifold learning, we construct a compact, geometry-preserving latent space of humanoid upper body designs in which optimization is tractable. We then solve design optimization in this latent space using gradient-free optimization. Our approach establishes a principled framework for data-driven robot design and demonstrates that leveraging existing designs and human motion can effectively guide the automated discovery of novel robot design.
Learning Dexterous Grasping from Sparse Taxonomy Guidance
Apr 05, 2026Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Formalizing the Sampling Design Space of Diffusion-Based Generative Models via Adaptive Solvers and Wasserstein-Bounded Timesteps
Feb 13, 2026Diffusion-based generative models have achieved remarkable performance across various domains, yet their practical deployment is often limited by high sampling costs. While prior work focuses on training objectives or individual solvers, the holistic design of sampling, specifically solver selection and scheduling, remains dominated by static heuristics. In this work, we revisit this challenge through a geometric lens, proposing SDM, a principled framework that aligns the numerical solver with the intrinsic properties of the diffusion trajectory. By analyzing the ODE dynamics, we show that efficient low-order solvers suffice in early high-noise stages while higher-order solvers can be progressively deployed to handle the increasing non-linearity of later stages. Furthermore, we formalize the scheduling by introducing a Wasserstein-bounded optimization framework. This method systematically derives adaptive timesteps that explicitly bound the local discretization error, ensuring the sampling process remains faithful to the underlying continuous dynamics. Without requiring additional training or architectural modifications, SDM achieves state-of-the-art performance across standard benchmarks, including an FID of 1.93 on CIFAR-10, 2.41 on FFHQ, and 1.98 on AFHQv2, with a reduced number of function evaluations compared to existing samplers. Our code is available at https://github.com/aiimaginglab/sdm.
Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and Speech
Jan 13, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Mar 19, 2025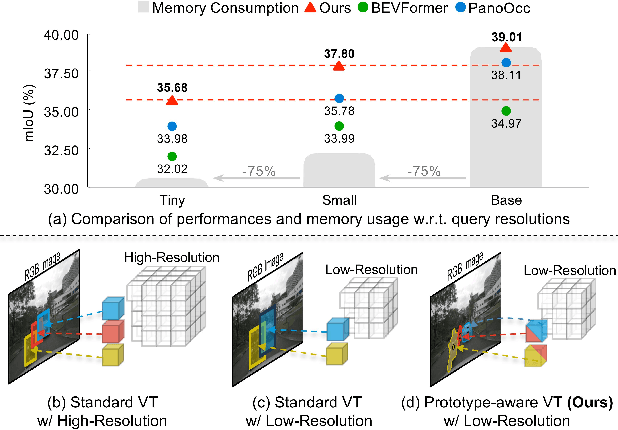
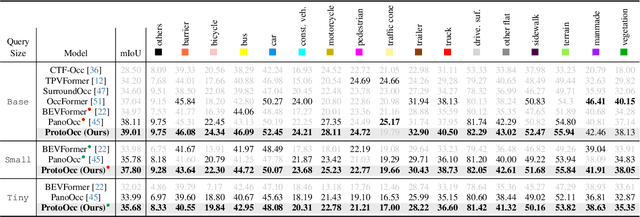
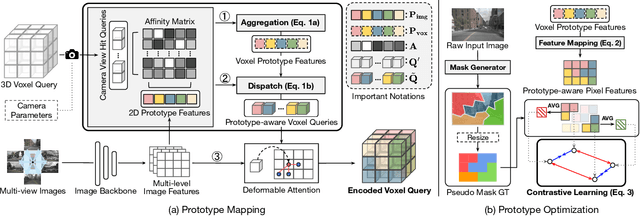
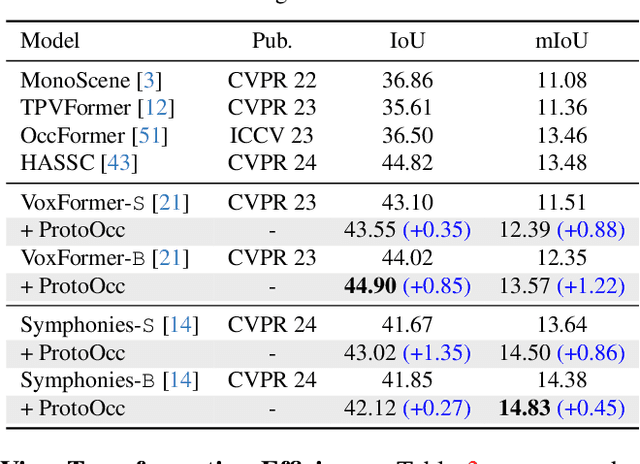
The resolution of voxel queries significantly influences the quality of view transformation in camera-based 3D occupancy prediction. However, computational constraints and the practical necessity for real-time deployment require smaller query resolutions, which inevitably leads to an information loss. Therefore, it is essential to encode and preserve rich visual details within limited query sizes while ensuring a comprehensive representation of 3D occupancy. To this end, we introduce ProtoOcc, a novel occupancy network that leverages prototypes of clustered image segments in view transformation to enhance low-resolution context. In particular, the mapping of 2D prototypes onto 3D voxel queries encodes high-level visual geometries and complements the loss of spatial information from reduced query resolutions. Additionally, we design a multi-perspective decoding strategy to efficiently disentangle the densely compressed visual cues into a high-dimensional 3D occupancy scene. Experimental results on both Occ3D and SemanticKITTI benchmarks demonstrate the effectiveness of the proposed method, showing clear improvements over the baselines. More importantly, ProtoOcc achieves competitive performance against the baselines even with 75\% reduced voxel resolution.
Learning-based Dynamic Robot-to-Human Handover
Feb 18, 2025This paper presents a novel learning-based approach to dynamic robot-to-human handover, addressing the challenges of delivering objects to a moving receiver. We hypothesize that dynamic handover, where the robot adjusts to the receiver's movements, results in more efficient and comfortable interaction compared to static handover, where the receiver is assumed to be stationary. To validate this, we developed a nonparametric method for generating continuous handover motion, conditioned on the receiver's movements, and trained the model using a dataset of 1,000 human-to-human handover demonstrations. We integrated preference learning for improved handover effectiveness and applied impedance control to ensure user safety and adaptiveness. The approach was evaluated in both simulation and real-world settings, with user studies demonstrating that dynamic handover significantly reduces handover time and improves user comfort compared to static methods. Videos and demonstrations of our approach are available at https://zerotohero7886.github.io/dyn-r2h-handover .
Versatile Motion Langauge Models for Multi-Turn Interactive Agents
Oct 08, 2024



Recent advancements in large language models (LLMs) have greatly enhanced their ability to generate natural and contextually relevant text, making AI interactions more human-like. However, generating and understanding interactive human-like motion, where two individuals engage in coordinated movements, remains a challenge due to the complexity of modeling these coordinated interactions. Furthermore, a versatile model is required to handle diverse interactive scenarios, such as chat systems that follow user instructions or adapt to their assigned role while adjusting interaction dynamics. To tackle this problem, we introduce VIM, short for the Versatile Interactive Motion language model, which integrates both language and motion modalities to effectively understand, generate, and control interactive motions in multi-turn conversational contexts. To address the scarcity of multi-turn interactive motion data, we introduce a synthetic dataset, INERT-MT2, where we utilize pre-trained models to create diverse instructional datasets with interactive motion. Our approach first trains a motion tokenizer that encodes interactive motions into residual discrete tokens. In the pretraining stage, the model learns to align motion and text representations with these discrete tokens. During the instruction fine-tuning stage, VIM adapts to multi-turn conversations using the INTER-MT2 dataset. We evaluate the versatility of our method across motion-related tasks, motion to text, text to motion, reaction generation, motion editing, and reasoning about motion sequences. The results highlight the versatility and effectiveness of proposed method in handling complex interactive motion synthesis.
Spatio-Temporal Motion Retargeting for Quadruped Robots
Apr 17, 2024This work introduces a motion retargeting approach for legged robots, which aims to create motion controllers that imitate the fine behavior of animals. Our approach, namely spatio-temporal motion retargeting (STMR), guides imitation learning procedures by transferring motion from source to target, effectively bridging the morphological disparities by ensuring the feasibility of imitation on the target system. Our STMR method comprises two components: spatial motion retargeting (SMR) and temporal motion retargeting (TMR). On the one hand, SMR tackles motion retargeting at the kinematic level by generating kinematically feasible whole-body motions from keypoint trajectories. On the other hand, TMR aims to retarget motion at the dynamic level by optimizing motion in the temporal domain. We showcase the effectiveness of our method in facilitating Imitation Learning (IL) for complex animal movements through a series of simulation and hardware experiments. In these experiments, our STMR method successfully tailored complex animal motions from various media, including video captured by a hand-held camera, to fit the morphology and physical properties of the target robots. This enabled RL policy training for precise motion tracking, while baseline methods struggled with highly dynamic motion involving flying phases. Moreover, we validated that the control policy can successfully imitate six different motions in two quadruped robots with different dimensions and physical properties in real-world settings.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024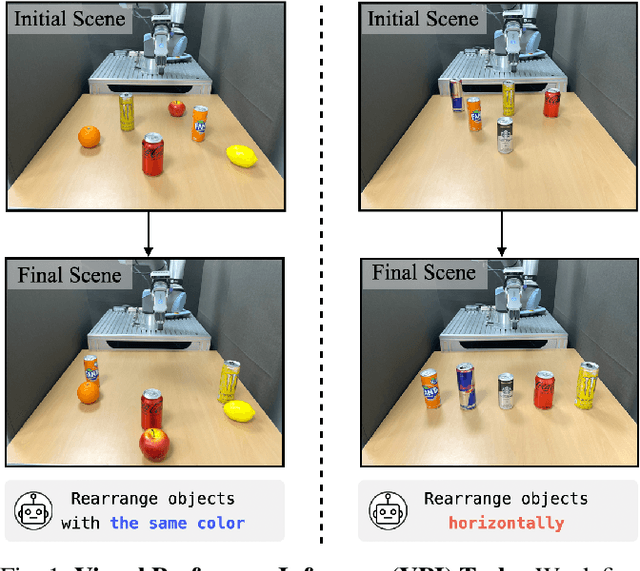

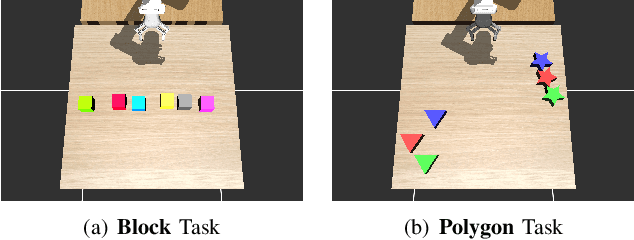

In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024



This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.