 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERQ: Saliency-Aware Low-Rank Error Reconstruction for LLM Quantization
Mar 09, 2026Post-training quantization (PTQ) has emerged as a prevailing technique for deploying large language models (LLMs) efficiently in terms of both memory and computation, across edge devices and server platforms. Existing PTQ methods primarily aim to reduce precision in weights and activations by mitigating quantization errors caused by channel-wise outlier activations (e.g., pre-quantization scaling, online transformations, or low-rank error reconstruction). Among these approaches, error reconstruction with low-rank adaptation (LoRA) has proven particularly effective, as it introduces a lightweight auxiliary computation path without requiring heavy optimization or additional online layers. However, prior studies reveal severe accuracy degradation under W4A4 settings, and conventional low-rank adaptations rely on two sequential factors, necessitating intermediate quantization during inference and thereby limiting low-precision efficiency. In this work, we propose SERQ, a saliency-aware error reconstruction method for low-bit LLM inference that employs a single low-rank compensation matrix. SERQ preserves efficient 4-bit matrix multiplication in linear layers by jointly mitigating quantization errors arising from both activation and weight saliency through three stages: (1) static activation flattening, (2) saliency-aware error reconstruction, and (3) offline weight permutation. The method incurs additional computation only for low-rank error reconstruction via a single decomposition, while all other operations are performed offline, thereby keeping latency overhead minimal. Empirically, SERQ outperforms prior error reconstruction methods under both W4A8 and W4A4 settings, and achieves higher accuracy than state-of-the-art rotation-based W4A4 approaches, while substantially reducing calibration complexity.
Learning-based Dynamic Robot-to-Human Handover
Feb 18, 2025This paper presents a novel learning-based approach to dynamic robot-to-human handover, addressing the challenges of delivering objects to a moving receiver. We hypothesize that dynamic handover, where the robot adjusts to the receiver's movements, results in more efficient and comfortable interaction compared to static handover, where the receiver is assumed to be stationary. To validate this, we developed a nonparametric method for generating continuous handover motion, conditioned on the receiver's movements, and trained the model using a dataset of 1,000 human-to-human handover demonstrations. We integrated preference learning for improved handover effectiveness and applied impedance control to ensure user safety and adaptiveness. The approach was evaluated in both simulation and real-world settings, with user studies demonstrating that dynamic handover significantly reduces handover time and improves user comfort compared to static methods. Videos and demonstrations of our approach are available at https://zerotohero7886.github.io/dyn-r2h-handover .
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024



This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
Label-Free Event-based Object Recognition via Joint Learning with Image Reconstruction from Events
Aug 18, 2023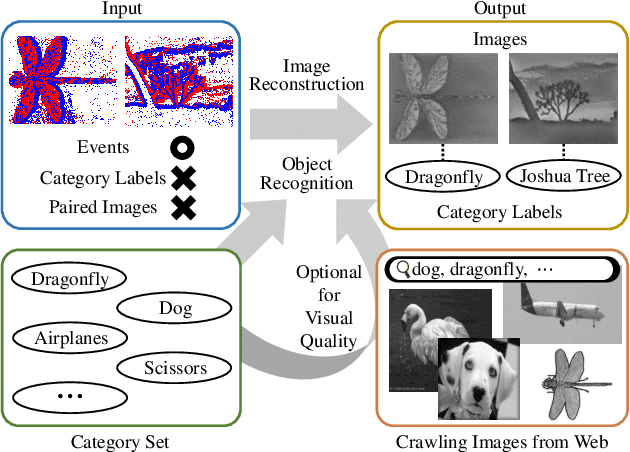
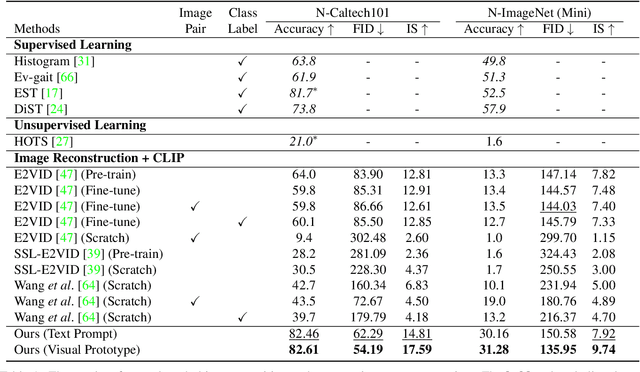
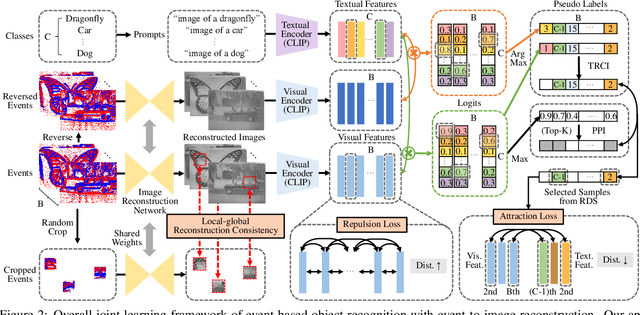
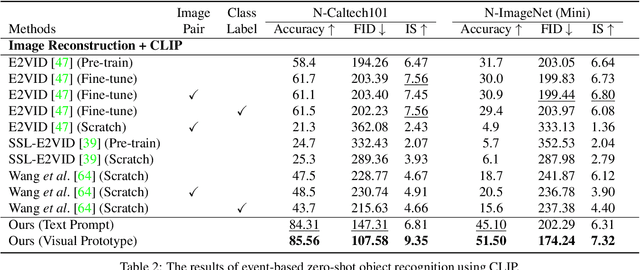
Recognizing objects from sparse and noisy events becomes extremely difficult when paired images and category labels do not exist. In this paper, we study label-free event-based object recognition where category labels and paired images are not available. To this end, we propose a joint formulation of object recognition and image reconstruction in a complementary manner. Our method first reconstructs images from events and performs object recognition through Contrastive Language-Image Pre-training (CLIP), enabling better recognition through a rich context of images. Since the category information is essential in reconstructing images, we propose category-guided attraction loss and category-agnostic repulsion loss to bridge the textual features of predicted categories and the visual features of reconstructed images using CLIP. Moreover, we introduce a reliable data sampling strategy and local-global reconstruction consistency to boost joint learning of two tasks. To enhance the accuracy of prediction and quality of reconstruction, we also propose a prototype-based approach using unpaired images. Extensive experiments demonstrate the superiority of our method and its extensibility for zero-shot object recognition. Our project code is available at \url{https://github.com/Chohoonhee/Ev-LaFOR}.
Pixel-wise Deep Image Stitching
Dec 12, 2021
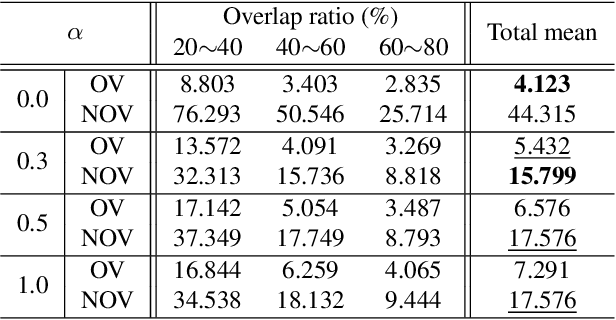
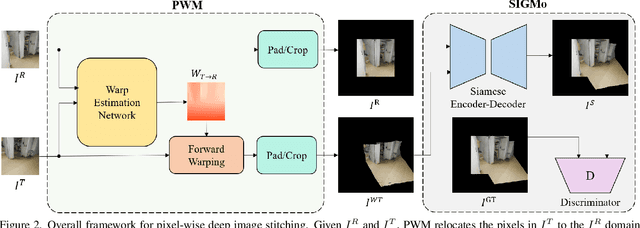
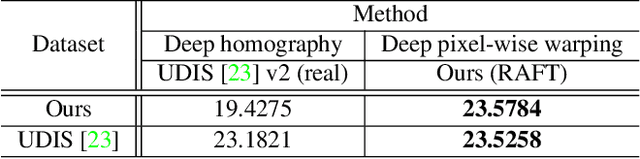
Image stitching aims at stitching the images taken from different viewpoints into an image with a wider field of view. Existing methods warp the target image to the reference image using the estimated warp function, and a homography is one of the most commonly used warping functions. However, when images have large parallax due to non-planar scenes and translational motion of a camera, the homography cannot fully describe the mapping between two images. Existing approaches based on global or local homography estimation are not free from this problem and suffer from undesired artifacts due to parallax. In this paper, instead of relying on the homography-based warp, we propose a novel deep image stitching framework exploiting the pixel-wise warp field to handle the large-parallax problem. The proposed deep image stitching framework consists of two modules: Pixel-wise Warping Module (PWM) and Stitched Image Generating Module (SIGMo). PWM employs an optical flow estimation model to obtain pixel-wise warp of the whole image, and relocates the pixels of the target image with the obtained warp field. SIGMo blends the warped target image and the reference image while eliminating unwanted artifacts such as misalignments, seams, and holes that harm the plausibility of the stitched result. For training and evaluating the proposed framework, we build a large-scale dataset that includes image pairs with corresponding pixel-wise ground truth warp and sample stitched result images. We show that the results of the proposed framework are qualitatively superior to those of the conventional methods, especially when the images have large parallax. The code and the proposed dataset will be publicly available soon.
Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Dec 10, 2021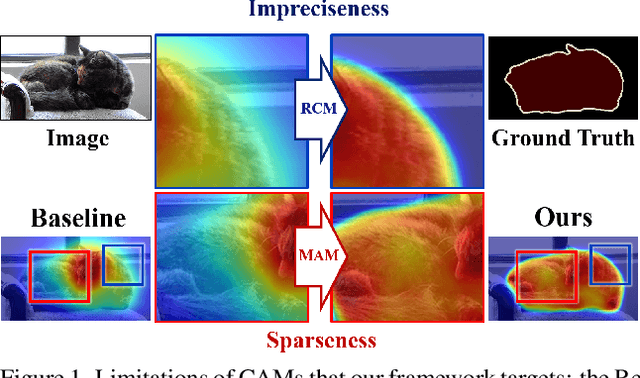
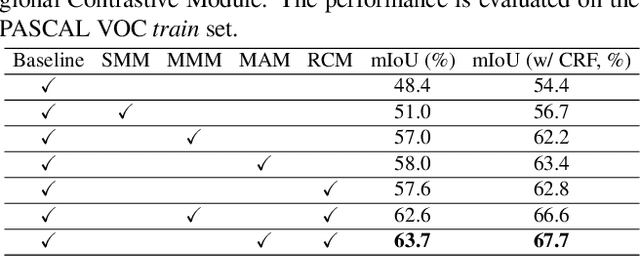
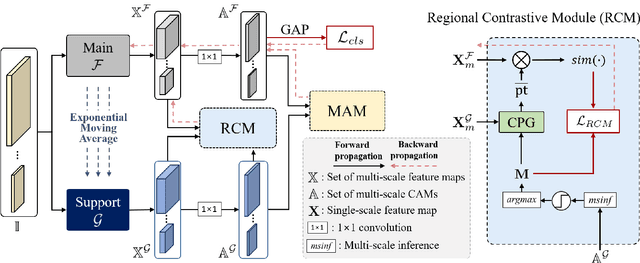
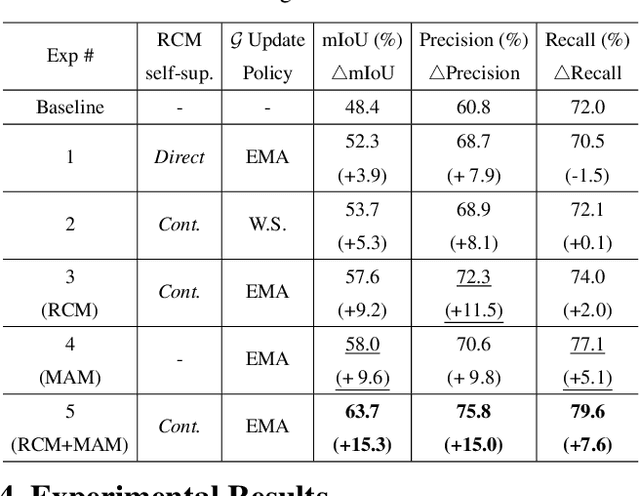
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.