 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Dynamic Robot-to-Human Handover
Feb 18, 2025This paper presents a novel learning-based approach to dynamic robot-to-human handover, addressing the challenges of delivering objects to a moving receiver. We hypothesize that dynamic handover, where the robot adjusts to the receiver's movements, results in more efficient and comfortable interaction compared to static handover, where the receiver is assumed to be stationary. To validate this, we developed a nonparametric method for generating continuous handover motion, conditioned on the receiver's movements, and trained the model using a dataset of 1,000 human-to-human handover demonstrations. We integrated preference learning for improved handover effectiveness and applied impedance control to ensure user safety and adaptiveness. The approach was evaluated in both simulation and real-world settings, with user studies demonstrating that dynamic handover significantly reduces handover time and improves user comfort compared to static methods. Videos and demonstrations of our approach are available at https://zerotohero7886.github.io/dyn-r2h-handover .
Towards Robotic Haptic Proxies in Virtual Reality
Jun 06, 2024This work represents the initial development of a haptic display system for increased presence in virtual experiences. The developed system creates a two-way connection between a virtual space, mediated through a virtual reality headset, and a physical space, mediated through a robotic manipulator, creating the foundation for future haptic display development using the haptic proxy framework. Here, we assesses hand-tracking performance of the Meta Quest Pro headset, examining hand tracking latency and static positional error to characterize performance of our system.
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024



This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
Towards Text-based Human Search and Approach with an Intelligent Robot Dog
Feb 10, 2023



In this paper, we propose a SOCratic model for Robots Approaching humans based on TExt System (SOCRATES) focusing on the human search and approach based on free-form textual description; the robot first searches for the target user, then the robot proceeds to approach in a human-friendly manner. In particular, textual descriptions are composed of appearance (e.g., wearing white shirts with black hair) and location clues (e.g., is a student who works with robots). We initially present a Human Search Socratic Model that connects large pre-trained models in the language domain to solve the downstream task, which is searching for the target person based on textual descriptions. Then, we propose a hybrid learning-based framework for generating target-cordial robotic motion to approach a person, consisting of a learning-from-demonstration module and a knowledge distillation module. We validate the proposed searching module via simulation using a virtual mobile robot as well as through real-world experiments involving participants and the Boston Dynamics Spot robot. Furthermore, we analyze the properties of the proposed approaching framework with human participants based on the Robotic Social Attributes Scale (RoSAS)
Active Visual Search in the Wild
Sep 20, 2022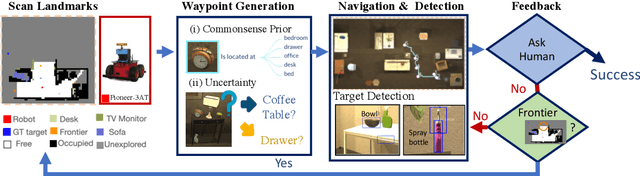
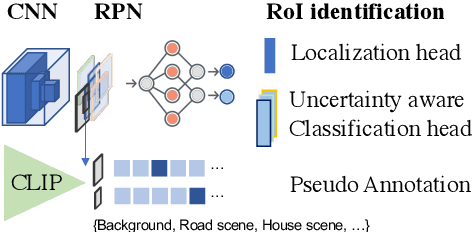

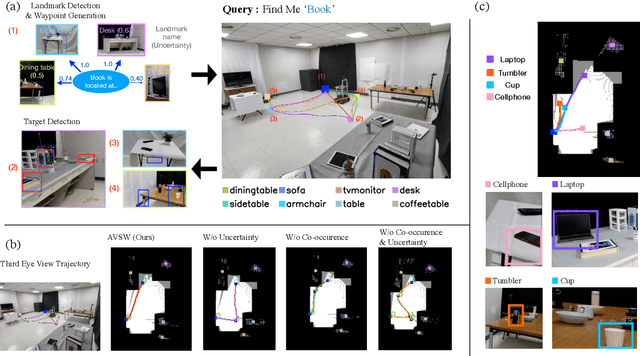
In this paper, we focus on the problem of efficiently locating a target object described with free-form language using a mobile robot equipped with vision sensors (e.g., an RGBD camera). Conventional active visual search predefines a set of objects to search for, rendering these techniques restrictive in practice. To provide added flexibility in active visual searching, we propose a system where a user can enter target commands using free-form language; we call this system Active Visual Search in the Wild (AVSW). AVSW detects and plans to search for a target object inputted by a user through a semantic grid map represented by static landmarks (e.g., desk or bed). For efficient planning of object search patterns, AVSW considers commonsense knowledge-based co-occurrence and predictive uncertainty while deciding which landmarks to visit first. We validate the proposed method with respect to SR (success rate) and SPL (success weighted by path length) in both simulated and real-world environments. The proposed method outperforms previous methods in terms of SPL in simulated scenarios with an average gap of 0.283. We further demonstrate AVSW with a Pioneer-3AT robot in real-world studies.