 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024



This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
Learning Joint Representation of Human Motion and Language
Oct 27, 2022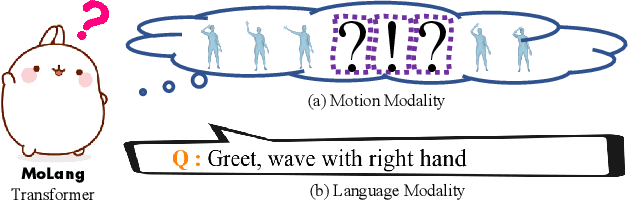
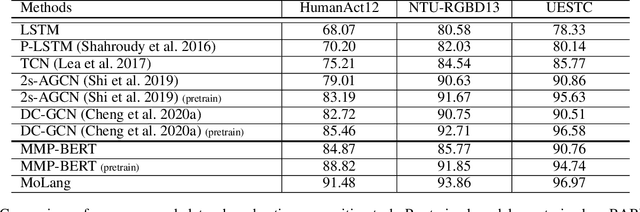
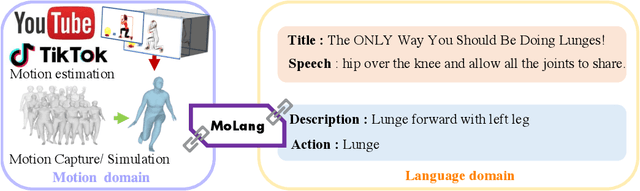
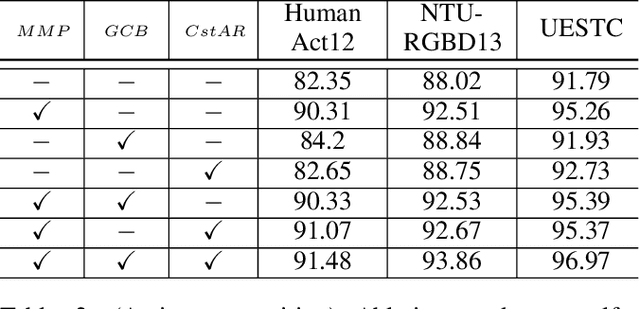
In this work, we present MoLang (a Motion-Language connecting model) for learning joint representation of human motion and language, leveraging both unpaired and paired datasets of motion and language modalities. To this end, we propose a motion-language model with contrastive learning, empowering our model to learn better generalizable representations of the human motion domain. Empirical results show that our model learns strong representations of human motion data through navigating language modality. Our proposed method is able to perform both action recognition and motion retrieval tasks with a single model where it outperforms state-of-the-art approaches on a number of action recognition benchmarks.
Conditional Motion In-betweening
Feb 09, 2022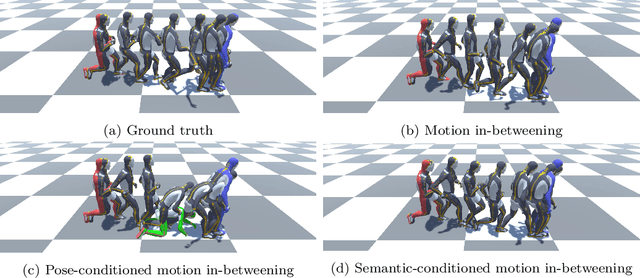
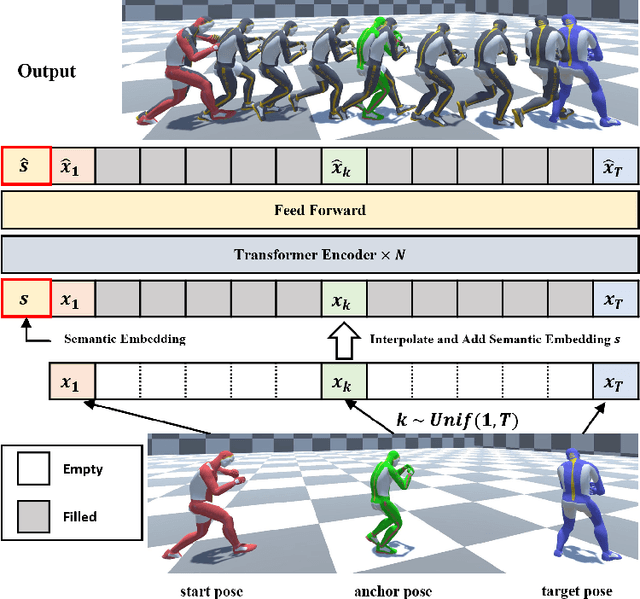
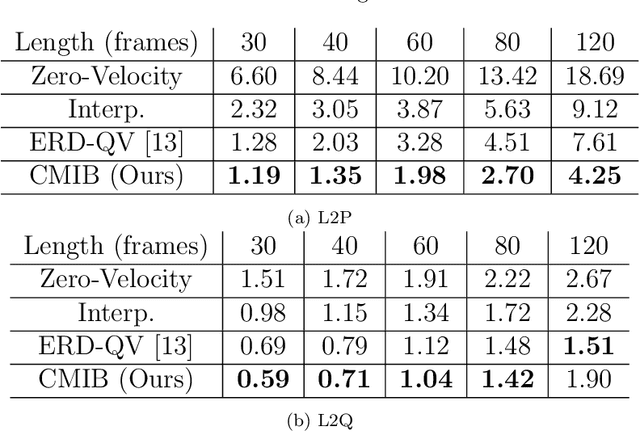
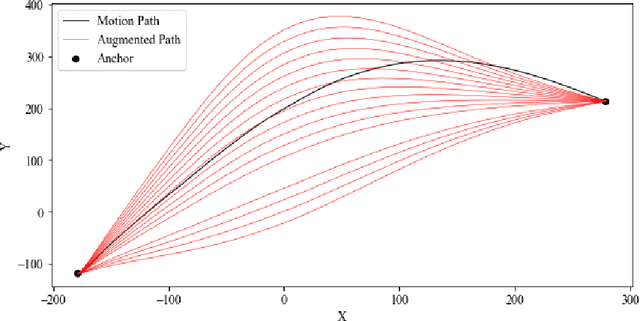
Motion in-betweening (MIB) is a process of generating intermediate skeletal movement between the given start and target poses while preserving the naturalness of the motion, such as periodic footstep motion while walking. Although state-of-the-art MIB methods are capable of producing plausible motions given sparse key-poses, they often lack the controllability to generate motions satisfying the semantic contexts required in practical applications. We focus on the method that can handle pose or semantic conditioned MIB tasks using a unified model. We also present a motion augmentation method to improve the quality of pose-conditioned motion generation via defining a distribution over smooth trajectories. Our proposed method outperforms the existing state-of-the-art MIB method in pose prediction errors while providing additional controllability.