 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExo-Plore: Exploring Exoskeleton Control Space through Human-aligned Simulation
Jan 30, 2026Exoskeletons show great promise for enhancing mobility, but providing appropriate assistance remains challenging due to the complexity of human adaptation to external forces. Current state-of-the-art approaches for optimizing exoskeleton controllers require extensive human experiments in which participants must walk for hours, creating a paradox: those who could benefit most from exoskeleton assistance, such as individuals with mobility impairments, are rarely able to participate in such demanding procedures. We present Exo-plore, a simulation framework that combines neuromechanical simulation with deep reinforcement learning to optimize hip exoskeleton assistance without requiring real human experiments. Exo-plore can (1) generate realistic gait data that captures human adaptation to assistive forces, (2) produce reliable optimization results despite the stochastic nature of human gait, and (3) generalize to pathological gaits, showing strong linear relationships between pathology severity and optimal assistance.
Versatile Physics-based Character Control with Hybrid Latent Representation
Mar 17, 2025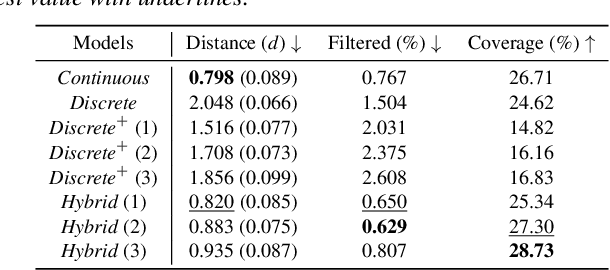
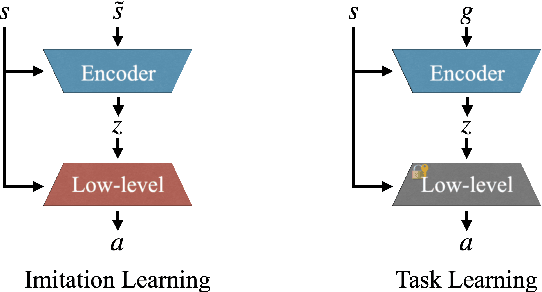

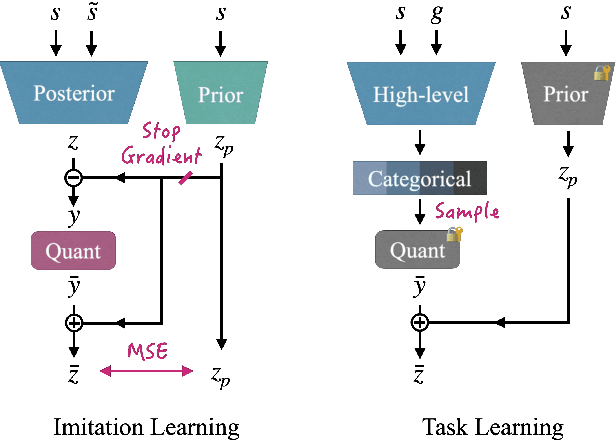
We present a versatile latent representation that enables physically simulated character to efficiently utilize motion priors. To build a powerful motion embedding that is shared across multiple tasks, the physics controller should employ rich latent space that is easily explored and capable of generating high-quality motion. We propose integrating continuous and discrete latent representations to build a versatile motion prior that can be adapted to a wide range of challenging control tasks. Specifically, we build a discrete latent model to capture distinctive posterior distribution without collapse, and simultaneously augment the sampled vector with the continuous residuals to generate high-quality, smooth motion without jittering. We further incorporate Residual Vector Quantization, which not only maximizes the capacity of the discrete motion prior, but also efficiently abstracts the action space during the task learning phase. We demonstrate that our agent can produce diverse yet smooth motions simply by traversing the learned motion prior through unconditional motion generation. Furthermore, our model robustly satisfies sparse goal conditions with highly expressive natural motions, including head-mounted device tracking and motion in-betweening at irregular intervals, which could not be achieved with existing latent representations.
Strategy and Skill Learning for Physics-based Table Tennis Animation
Jul 23, 2024



Recent advancements in physics-based character animation leverage deep learning to generate agile and natural motion, enabling characters to execute movements such as backflips, boxing, and tennis. However, reproducing the selection and use of diverse motor skills in dynamic environments to solve complex tasks, as humans do, still remains a challenge. We present a strategy and skill learning approach for physics-based table tennis animation. Our method addresses the issue of mode collapse, where the characters do not fully utilize the motor skills they need to perform to execute complex tasks. More specifically, we demonstrate a hierarchical control system for diversified skill learning and a strategy learning framework for effective decision-making. We showcase the efficacy of our method through comparative analysis with state-of-the-art methods, demonstrating its capabilities in executing various skills for table tennis. Our strategy learning framework is validated through both agent-agent interaction and human-agent interaction in Virtual Reality, handling both competitive and cooperative tasks.
MOCHA: Real-Time Motion Characterization via Context Matching
Oct 16, 2023



Transforming neutral, characterless input motions to embody the distinct style of a notable character in real time is highly compelling for character animation. This paper introduces MOCHA, a novel online motion characterization framework that transfers both motion styles and body proportions from a target character to an input source motion. MOCHA begins by encoding the input motion into a motion feature that structures the body part topology and captures motion dependencies for effective characterization. Central to our framework is the Neural Context Matcher, which generates a motion feature for the target character with the most similar context to the input motion feature. The conditioned autoregressive model of the Neural Context Matcher can produce temporally coherent character features in each time frame. To generate the final characterized pose, our Characterizer network incorporates the characteristic aspects of the target motion feature into the input motion feature while preserving its context. This is achieved through a transformer model that introduces the adaptive instance normalization and context mapping-based cross-attention, effectively injecting the character feature into the source feature. We validate the performance of our framework through comparisons with prior work and an ablation study. Our framework can easily accommodate various applications, including characterization with only sparse input and real-time characterization. Additionally, we contribute a high-quality motion dataset comprising six different characters performing a range of motions, which can serve as a valuable resource for future research.
DROP: Dynamics Responses from Human Motion Prior and Projective Dynamics
Sep 24, 2023Synthesizing realistic human movements, dynamically responsive to the environment, is a long-standing objective in character animation, with applications in computer vision, sports, and healthcare, for motion prediction and data augmentation. Recent kinematics-based generative motion models offer impressive scalability in modeling extensive motion data, albeit without an interface to reason about and interact with physics. While simulator-in-the-loop learning approaches enable highly physically realistic behaviors, the challenges in training often affect scalability and adoption. We introduce DROP, a novel framework for modeling Dynamics Responses of humans using generative mOtion prior and Projective dynamics. DROP can be viewed as a highly stable, minimalist physics-based human simulator that interfaces with a kinematics-based generative motion prior. Utilizing projective dynamics, DROP allows flexible and simple integration of the learned motion prior as one of the projective energies, seamlessly incorporating control provided by the motion prior with Newtonian dynamics. Serving as a model-agnostic plug-in, DROP enables us to fully leverage recent advances in generative motion models for physics-based motion synthesis. We conduct extensive evaluations of our model across different motion tasks and various physical perturbations, demonstrating the scalability and diversity of responses.
Physics-based Motion Retargeting from Sparse Inputs
Jul 04, 2023



Avatars are important to create interactive and immersive experiences in virtual worlds. One challenge in animating these characters to mimic a user's motion is that commercial AR/VR products consist only of a headset and controllers, providing very limited sensor data of the user's pose. Another challenge is that an avatar might have a different skeleton structure than a human and the mapping between them is unclear. In this work we address both of these challenges. We introduce a method to retarget motions in real-time from sparse human sensor data to characters of various morphologies. Our method uses reinforcement learning to train a policy to control characters in a physics simulator. We only require human motion capture data for training, without relying on artist-generated animations for each avatar. This allows us to use large motion capture datasets to train general policies that can track unseen users from real and sparse data in real-time. We demonstrate the feasibility of our approach on three characters with different skeleton structure: a dinosaur, a mouse-like creature and a human. We show that the avatar poses often match the user surprisingly well, despite having no sensor information of the lower body available. We discuss and ablate the important components in our framework, specifically the kinematic retargeting step, the imitation, contact and action reward as well as our asymmetric actor-critic observations. We further explore the robustness of our method in a variety of settings including unbalancing, dancing and sports motions.
QuestEnvSim: Environment-Aware Simulated Motion Tracking from Sparse Sensors
Jun 09, 2023

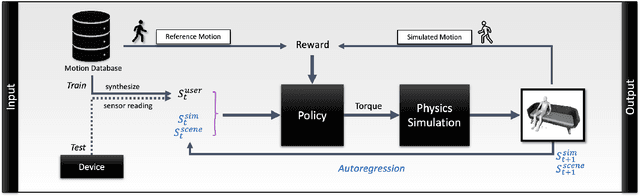

Replicating a user's pose from only wearable sensors is important for many AR/VR applications. Most existing methods for motion tracking avoid environment interaction apart from foot-floor contact due to their complex dynamics and hard constraints. However, in daily life people regularly interact with their environment, e.g. by sitting on a couch or leaning on a desk. Using Reinforcement Learning, we show that headset and controller pose, if combined with physics simulation and environment observations can generate realistic full-body poses even in highly constrained environments. The physics simulation automatically enforces the various constraints necessary for realistic poses, instead of manually specifying them as in many kinematic approaches. These hard constraints allow us to achieve high-quality interaction motions without typical artifacts such as penetration or contact sliding. We discuss three features, the environment representation, the contact reward and scene randomization, crucial to the performance of the method. We demonstrate the generality of the approach through various examples, such as sitting on chairs, a couch and boxes, stepping over boxes, rocking a chair and turning an office chair. We believe these are some of the highest-quality results achieved for motion tracking from sparse sensor with scene interaction.
Bidirectional GaitNet: A Bidirectional Prediction Model of Human Gait and Anatomical Conditions
Jun 07, 2023
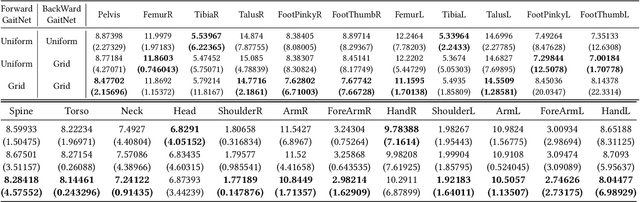
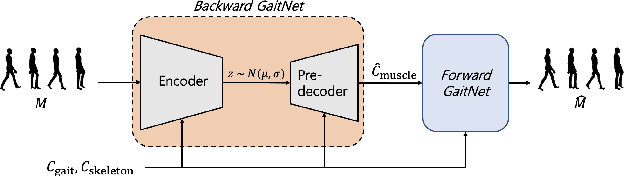
We present a novel generative model, called Bidirectional GaitNet, that learns the relationship between human anatomy and its gait. The simulation model of human anatomy is a comprehensive, full-body, simulation-ready, musculoskeletal model with 304 Hill-type musculotendon units. The Bidirectional GaitNet consists of forward and backward models. The forward model predicts a gait pattern of a person with specific physical conditions, while the backward model estimates the physical conditions of a person when his/her gait pattern is provided. Our simulation-based approach first learns the forward model by distilling the simulation data generated by a state-of-the-art predictive gait simulator and then constructs a Variational Autoencoder (VAE) with the learned forward model as its decoder. Once it is learned its encoder serves as the backward model. We demonstrate our model on a variety of healthy/impaired gaits and validate it in comparison with physical examination data of real patients.
Simulation and Retargeting of Complex Multi-Character Interactions
May 31, 2023We present a method for reproducing complex multi-character interactions for physically simulated humanoid characters using deep reinforcement learning. Our method learns control policies for characters that imitate not only individual motions, but also the interactions between characters, while maintaining balance and matching the complexity of reference data. Our approach uses a novel reward formulation based on an interaction graph that measures distances between pairs of interaction landmarks. This reward encourages control policies to efficiently imitate the character's motion while preserving the spatial relationships of the interactions in the reference motion. We evaluate our method on a variety of activities, from simple interactions such as a high-five greeting to more complex interactions such as gymnastic exercises, Salsa dancing, and box carrying and throwing. This approach can be used to ``clean-up'' existing motion capture data to produce physically plausible interactions or to retarget motion to new characters with different sizes, kinematics or morphologies while maintaining the interactions in the original data.
ACE: Adversarial Correspondence Embedding for Cross Morphology Motion Retargeting from Human to Nonhuman Characters
May 24, 2023



Motion retargeting is a promising approach for generating natural and compelling animations for nonhuman characters. However, it is challenging to translate human movements into semantically equivalent motions for target characters with different morphologies due to the ambiguous nature of the problem. This work presents a novel learning-based motion retargeting framework, Adversarial Correspondence Embedding (ACE), to retarget human motions onto target characters with different body dimensions and structures. Our framework is designed to produce natural and feasible robot motions by leveraging generative-adversarial networks (GANs) while preserving high-level motion semantics by introducing an additional feature loss. In addition, we pretrain a robot motion prior that can be controlled in a latent embedding space and seek to establish a compact correspondence. We demonstrate that the proposed framework can produce retargeted motions for three different characters -- a quadrupedal robot with a manipulator, a crab character, and a wheeled manipulator. We further validate the design choices of our framework by conducting baseline comparisons and a user study. We also showcase sim-to-real transfer of the retargeted motions by transferring them to a real Spot robot.