 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead Control
Mar 14, 2025We present Diffuse-CLoC, a guided diffusion framework for physics-based look-ahead control that enables intuitive, steerable, and physically realistic motion generation. While existing kinematics motion generation with diffusion models offer intuitive steering capabilities with inference-time conditioning, they often fail to produce physically viable motions. In contrast, recent diffusion-based control policies have shown promise in generating physically realizable motion sequences, but the lack of kinematics prediction limits their steerability. Diffuse-CLoC addresses these challenges through a key insight: modeling the joint distribution of states and actions within a single diffusion model makes action generation steerable by conditioning it on the predicted states. This approach allows us to leverage established conditioning techniques from kinematic motion generation while producing physically realistic motions. As a result, we achieve planning capabilities without the need for a high-level planner. Our method handles a diverse set of unseen long-horizon downstream tasks through a single pre-trained model, including static and dynamic obstacle avoidance, motion in-betweening, and task-space control. Experimental results show that our method significantly outperforms the traditional hierarchical framework of high-level motion diffusion and low-level tracking.
Self-supervised 6-DoF Robot Grasping by Demonstration via Augmented Reality Teleoperation System
Apr 03, 2024
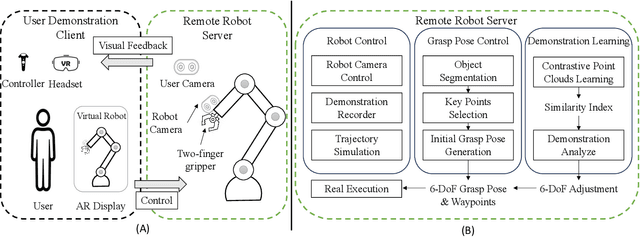


Most existing 6-DoF robot grasping solutions depend on strong supervision on grasp pose to ensure satisfactory performance, which could be laborious and impractical when the robot works in some restricted area. To this end, we propose a self-supervised 6-DoF grasp pose detection framework via an Augmented Reality (AR) teleoperation system that can efficiently learn human demonstrations and provide 6-DoF grasp poses without grasp pose annotations. Specifically, the system collects the human demonstration from the AR environment and contrastively learns the grasping strategy from the demonstration. For the real-world experiment, the proposed system leads to satisfactory grasping abilities and learning to grasp unknown objects within three demonstrations.
Simulation and Retargeting of Complex Multi-Character Interactions
May 31, 2023We present a method for reproducing complex multi-character interactions for physically simulated humanoid characters using deep reinforcement learning. Our method learns control policies for characters that imitate not only individual motions, but also the interactions between characters, while maintaining balance and matching the complexity of reference data. Our approach uses a novel reward formulation based on an interaction graph that measures distances between pairs of interaction landmarks. This reward encourages control policies to efficiently imitate the character's motion while preserving the spatial relationships of the interactions in the reference motion. We evaluate our method on a variety of activities, from simple interactions such as a high-five greeting to more complex interactions such as gymnastic exercises, Salsa dancing, and box carrying and throwing. This approach can be used to ``clean-up'' existing motion capture data to produce physically plausible interactions or to retarget motion to new characters with different sizes, kinematics or morphologies while maintaining the interactions in the original data.
Learning to Transfer In-Hand Manipulations Using a Greedy Shape Curriculum
Mar 14, 2023In-hand object manipulation is challenging to simulate due to complex contact dynamics, non-repetitive finger gaits, and the need to indirectly control unactuated objects. Further adapting a successful manipulation skill to new objects with different shapes and physical properties is a similarly challenging problem. In this work, we show that natural and robust in-hand manipulation of simple objects in a dynamic simulation can be learned from a high quality motion capture example via deep reinforcement learning with careful designs of the imitation learning problem. We apply our approach on both single-handed and two-handed dexterous manipulations of diverse object shapes and motions. We then demonstrate further adaptation of the example motion to a more complex shape through curriculum learning on intermediate shapes morphed between the source and target object. While a naive curriculum of progressive morphs often falls short, we propose a simple greedy curriculum search algorithm that can successfully apply to a range of objects such as a teapot, bunny, bottle, train, and elephant.
Learning to Manipulate Amorphous Materials
Mar 03, 2021
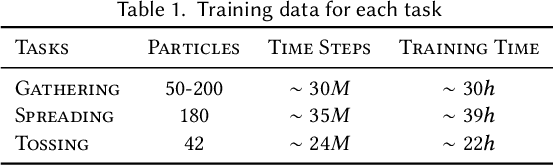

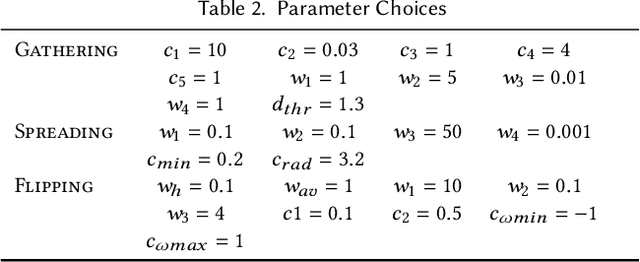
We present a method of training character manipulation of amorphous materials such as those often used in cooking. Common examples of amorphous materials include granular materials (salt, uncooked rice), fluids (honey), and visco-plastic materials (sticky rice, softened butter). A typical task is to spread a given material out across a flat surface using a tool such as a scraper or knife. We use reinforcement learning to train our controllers to manipulate materials in various ways. The training is performed in a physics simulator that uses position-based dynamics of particles to simulate the materials to be manipulated. The neural network control policy is given observations of the material (e.g. a low-resolution density map), and the policy outputs actions such as rotating and translating the knife. We demonstrate policies that have been successfully trained to carry out the following tasks: spreading, gathering, and flipping. We produce a final animation by using inverse kinematics to guide a character's arm and hand to match the motion of the manipulation tool such as a knife or a frying pan.
Learning Novel Policies For Tasks
May 13, 2019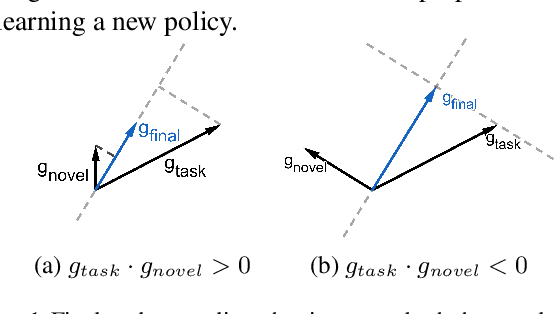


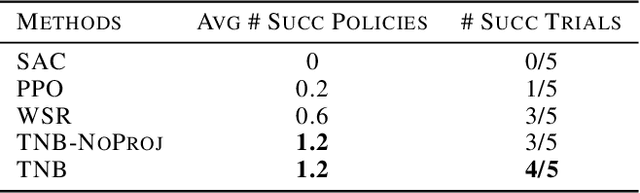
In this work, we present a reinforcement learning algorithm that can find a variety of policies (novel policies) for a task that is given by a task reward function. Our method does this by creating a second reward function that recognizes previously seen state sequences and rewards those by novelty, which is measured using autoencoders that have been trained on state sequences from previously discovered policies. We present a two-objective update technique for policy gradient algorithms in which each update of the policy is a compromise between improving the task reward and improving the novelty reward. Using this method, we end up with a collection of policies that solves a given task as well as carrying out action sequences that are distinct from one another. We demonstrate this method on maze navigation tasks, a reaching task for a simulated robot arm, and a locomotion task for a hopper. We also demonstrate the effectiveness of our approach on deceptive tasks in which policy gradient methods often get stuck.