 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Feb 03, 2026Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.
mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning
Jan 29, 2026We present mjlab, a lightweight, open-source framework for robot learning that combines GPU-accelerated simulation with composable environments and minimal setup friction. mjlab adopts the manager-based API introduced by Isaac Lab, where users compose modular building blocks for observations, rewards, and events, and pairs it with MuJoCo Warp for GPU-accelerated physics. The result is a framework installable with a single command, requiring minimal dependencies, and providing direct access to native MuJoCo data structures. mjlab ships with reference implementations of velocity tracking, motion imitation, and manipulation tasks.
Coordinated Humanoid Manipulation with Choice Policies
Dec 31, 2025Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks: dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.
MomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
CHyLL: Learning Continuous Neural Representations of Hybrid Systems
Dec 10, 2025Learning the flows of hybrid systems that have both continuous and discrete time dynamics is challenging. The existing method learns the dynamics in each discrete mode, which suffers from the combination of mode switching and discontinuities in the flows. In this work, we propose CHyLL (Continuous Hybrid System Learning in Latent Space), which learns a continuous neural representation of a hybrid system without trajectory segmentation, event functions, or mode switching. The key insight of CHyLL is that the reset map glues the state space at the guard surface, reformulating the state space as a piecewise smooth quotient manifold where the flow becomes spatially continuous. Building upon these insights and the embedding theorems grounded in differential topology, CHyLL concurrently learns a singularity-free neural embedding in a higher-dimensional space and the continuous flow in it. We showcase that CHyLL can accurately predict the flow of hybrid systems with superior accuracy and identify the topological invariants of the hybrid systems. Finally, we apply CHyLL to the stochastic optimal control problem.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Aug 28, 2025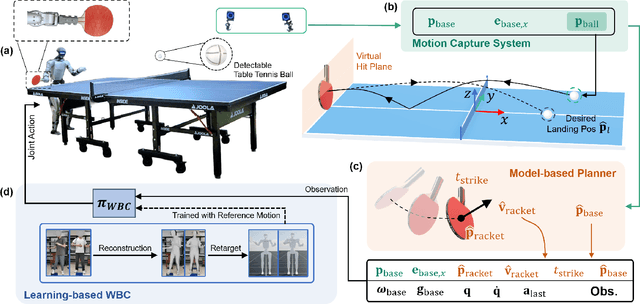
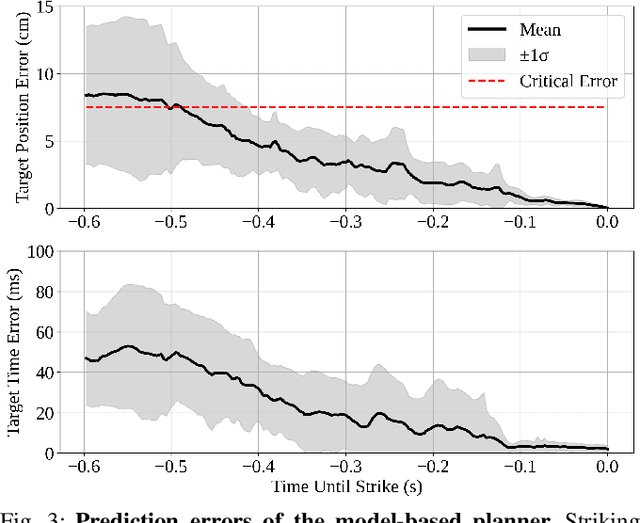
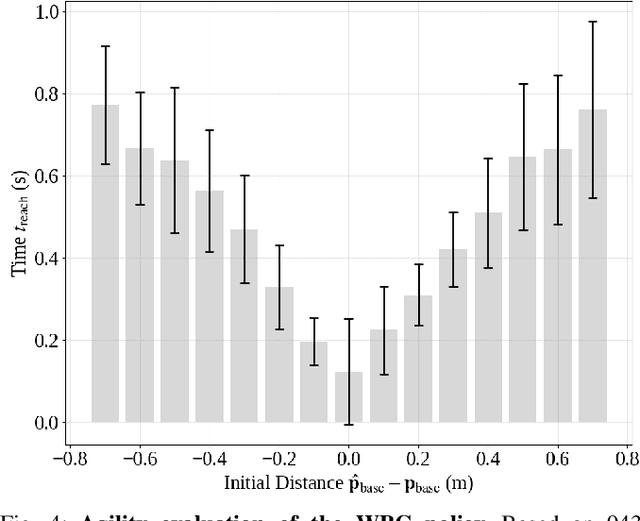

Humanoid robots have recently achieved impressive progress in locomotion and whole-body control, yet they remain constrained in tasks that demand rapid interaction with dynamic environments through manipulation. Table tennis exemplifies such a challenge: with ball speeds exceeding 5 m/s, players must perceive, predict, and act within sub-second reaction times, requiring both agility and precision. To address this, we present a hierarchical framework for humanoid table tennis that integrates a model-based planner for ball trajectory prediction and racket target planning with a reinforcement learning-based whole-body controller. The planner determines striking position, velocity and timing, while the controller generates coordinated arm and leg motions that mimic human strikes and maintain stability and agility across consecutive rallies. Moreover, to encourage natural movements, human motion references are incorporated during training. We validate our system on a general-purpose humanoid robot, achieving up to 106 consecutive shots with a human opponent and sustained exchanges against another humanoid. These results demonstrate real-world humanoid table tennis with sub-second reactive control, marking a step toward agile and interactive humanoid behaviors.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Aug 13, 2025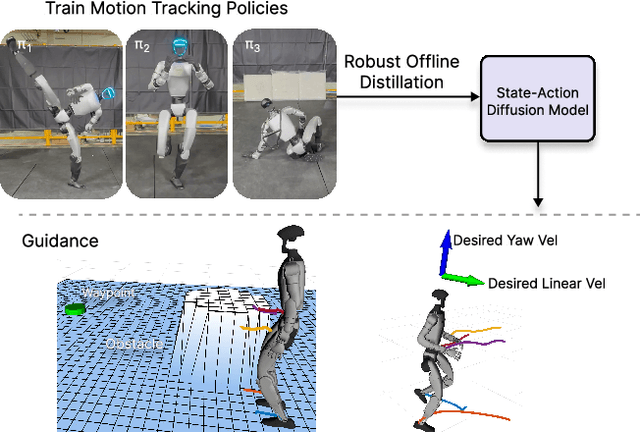



Learning skills from human motions offers a promising path toward generalizable policies for versatile humanoid whole-body control, yet two key cornerstones are missing: (1) a high-quality motion tracking framework that faithfully transforms large-scale kinematic references into robust and extremely dynamic motions on real hardware, and (2) a distillation approach that can effectively learn these motion primitives and compose them to solve downstream tasks. We address these gaps with BeyondMimic, a real-world framework to learn from human motions for versatile and naturalistic humanoid control via guided diffusion. Our framework provides a motion tracking pipeline capable of challenging skills such as jumping spins, sprinting, and cartwheels with state-of-the-art motion quality. Moving beyond simply mimicking existing motions, we further introduce a unified diffusion policy that enables zero-shot task-specific control at test time using simple cost functions. Deployed on hardware, BeyondMimic performs diverse tasks at test time, including waypoint navigation, joystick teleoperation, and obstacle avoidance, bridging sim-to-real motion tracking and flexible synthesis of human motion primitives for whole-body control. https://beyondmimic.github.io/.
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams
May 20, 2025Achieving coordinated teamwork among legged robots requires both fine-grained locomotion control and long-horizon strategic decision-making. Robot soccer offers a compelling testbed for this challenge, combining dynamic, competitive, and multi-agent interactions. In this work, we present a hierarchical multi-agent reinforcement learning (MARL) framework that enables fully autonomous and decentralized quadruped robot soccer. First, a set of highly dynamic low-level skills is trained for legged locomotion and ball manipulation, such as walking, dribbling, and kicking. On top of these, a high-level strategic planning policy is trained with Multi-Agent Proximal Policy Optimization (MAPPO) via Fictitious Self-Play (FSP). This learning framework allows agents to adapt to diverse opponent strategies and gives rise to sophisticated team behaviors, including coordinated passing, interception, and dynamic role allocation. With an extensive ablation study, the proposed learning method shows significant advantages in the cooperative and competitive multi-agent soccer game. We deploy the learned policies to real quadruped robots relying solely on onboard proprioception and decentralized localization, with the resulting system supporting autonomous robot-robot and robot-human soccer matches on indoor and outdoor soccer courts.
HuB: Learning Extreme Humanoid Balance
May 12, 2025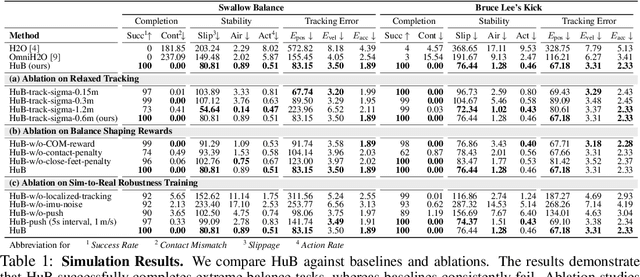
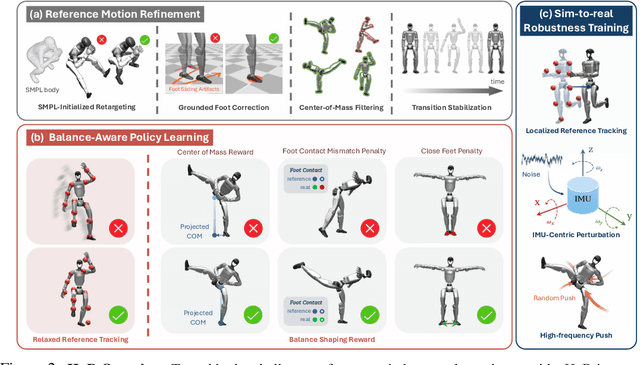
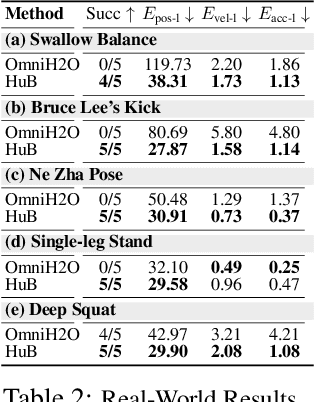
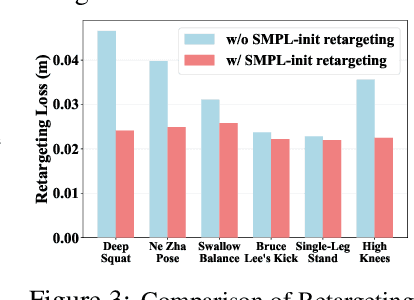
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.