 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDAT: Diffusion Policies Enforcing Dynamically Admissible Robot Trajectories
Feb 20, 2025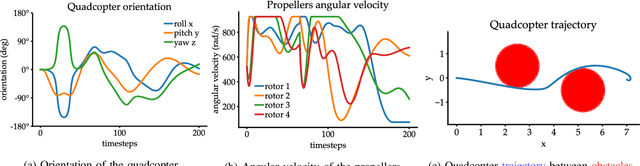
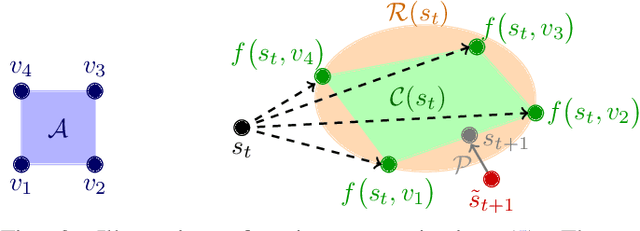
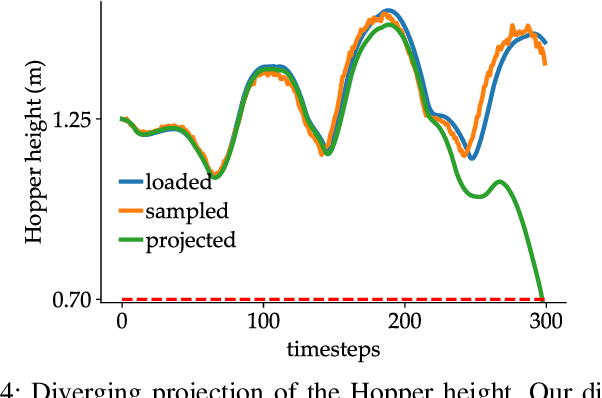
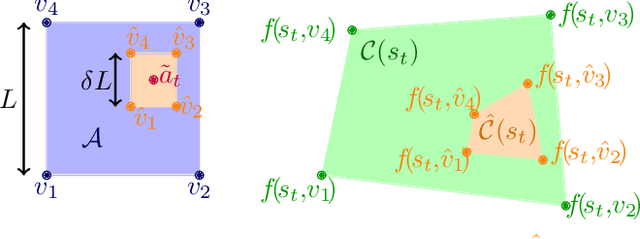
Diffusion models excel at creating images and videos thanks to their multimodal generative capabilities. These same capabilities have made diffusion models increasingly popular in robotics research, where they are used for generating robot motion. However, the stochastic nature of diffusion models is fundamentally at odds with the precise dynamical equations describing the feasible motion of robots. Hence, generating dynamically admissible robot trajectories is a challenge for diffusion models. To alleviate this issue, we introduce DDAT: Diffusion policies for Dynamically Admissible Trajectories to generate provably admissible trajectories of black-box robotic systems using diffusion models. A sequence of states is a dynamically admissible trajectory if each state of the sequence belongs to the reachable set of its predecessor by the robot's equations of motion. To generate such trajectories, our diffusion policies project their predictions onto a dynamically admissible manifold during both training and inference to align the objective of the denoiser neural network with the dynamical admissibility constraint. The auto-regressive nature of these projections along with the black-box nature of robot dynamics render these projections immensely challenging. We thus enforce admissibility by iteratively sampling a polytopic under-approximation of the reachable set of a state onto which we project its predicted successor, before iterating this process with the projected successor. By producing accurate trajectories, this projection eliminates the need for diffusion models to continually replan, enabling one-shot long-horizon trajectory planning. We demonstrate that our framework generates higher quality dynamically admissible robot trajectories through extensive simulations on a quadcopter and various MuJoCo environments, along with real-world experiments on a Unitree GO1 and GO2.
POLICEd RL: Learning Closed-Loop Robot Control Policies with Provable Satisfaction of Hard Constraints
Mar 20, 2024In this paper, we seek to learn a robot policy guaranteed to satisfy state constraints. To encourage constraint satisfaction, existing RL algorithms typically rely on Constrained Markov Decision Processes and discourage constraint violations through reward shaping. However, such soft constraints cannot offer verifiable safety guarantees. To address this gap, we propose POLICEd RL, a novel RL algorithm explicitly designed to enforce affine hard constraints in closed-loop with a black-box environment. Our key insight is to force the learned policy to be affine around the unsafe set and use this affine region as a repulsive buffer to prevent trajectories from violating the constraint. We prove that such policies exist and guarantee constraint satisfaction. Our proposed framework is applicable to both systems with continuous and discrete state and action spaces and is agnostic to the choice of the RL training algorithm. Our results demonstrate the capacity of POLICEd RL to enforce hard constraints in robotic tasks while significantly outperforming existing methods.
Optimal Robotic Assembly Sequence Planning: A Sequential Decision-Making Approach
Oct 26, 2023The optimal robot assembly planning problem is challenging due to the necessity of finding the optimal solution amongst an exponentially vast number of possible plans, all while satisfying a selection of constraints. Traditionally, robotic assembly planning problems have been solved using heuristics, but these methods are specific to a given objective structure or set of problem parameters. In this paper, we propose a novel approach to robotic assembly planning that poses assembly sequencing as a sequential decision making problem, enabling us to harness methods that far outperform the state-of-the-art. We formulate the problem as a Markov Decision Process (MDP) and utilize Dynamic Programming (DP) to find optimal assembly policies for moderately sized strictures. We further expand our framework to exploit the deterministic nature of assembly planning and introduce a class of optimal Graph Exploration Assembly Planners (GEAPs). For larger structures, we show how Reinforcement Learning (RL) enables us to learn policies that generate high reward assembly sequences. We evaluate our approach on a variety of robotic assembly problems, such as the assembly of the Hubble Space Telescope, the International Space Station, and the James Webb Space Telescope. We further showcase how our DP, GEAP, and RL implementations are capable of finding optimal solutions under a variety of different objective functions and how our formulation allows us to translate precedence constraints to branch pruning and thus further improve performance. We have published our code at https://github.com/labicon/ORASP-Code.