 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARK: Skeleton-Parameter Aligned Retargeting on Humanoid Robots with Kinodynamic Trajectory Optimization
Mar 12, 2026Human motion provides rich priors for training general-purpose humanoid control policies, but raw demonstrations are often incompatible with a robot's kinematics and dynamics, limiting their direct use. We present a two-stage pipeline for generating natural and dynamically feasible motion references from task-space human data. First, we convert human motion into a unified robot description format (URDF)-based skeleton representation and calibrate it to the target humanoid's dimensions. By aligning the underlying skeleton structure rather than heuristically modifying task-space targets, this step significantly reduces inverse kinematics error and tuning effort. Second, we refine the retargeted trajectories through progressive kinodynamic trajectory optimization (TO), solved in three stages: kinematic TO, inverse dynamics, and full kinodynamic TO, each warm-started from the previous solution. The final result yields dynamically consistent state trajectories and joint torque profiles, providing high-quality references for learning-based controllers. Together, skeleton calibration and kinodynamic TO enable the generation of natural, physically consistent motion references across diverse humanoid platforms.
mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning
Jan 29, 2026We present mjlab, a lightweight, open-source framework for robot learning that combines GPU-accelerated simulation with composable environments and minimal setup friction. mjlab adopts the manager-based API introduced by Isaac Lab, where users compose modular building blocks for observations, rewards, and events, and pairs it with MuJoCo Warp for GPU-accelerated physics. The result is a framework installable with a single command, requiring minimal dependencies, and providing direct access to native MuJoCo data structures. mjlab ships with reference implementations of velocity tracking, motion imitation, and manipulation tasks.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Aug 28, 2025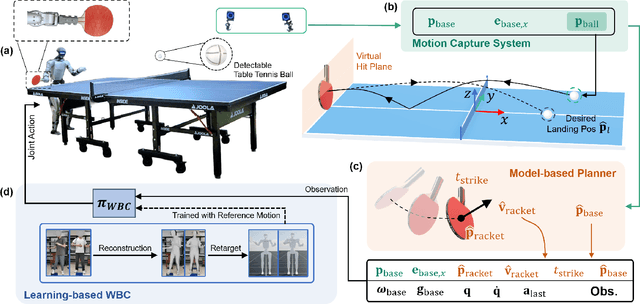
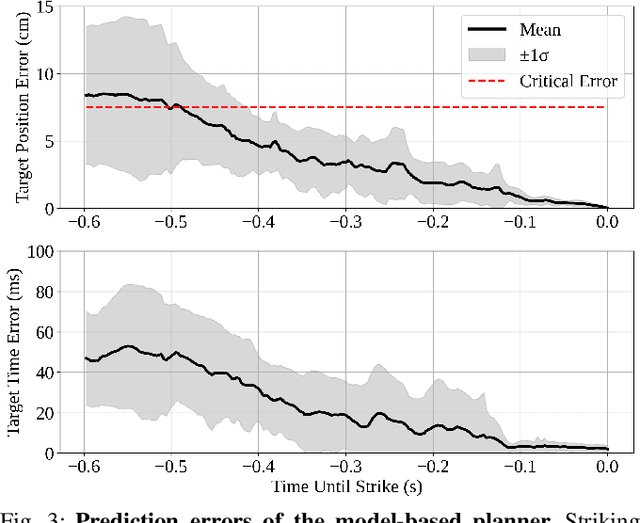
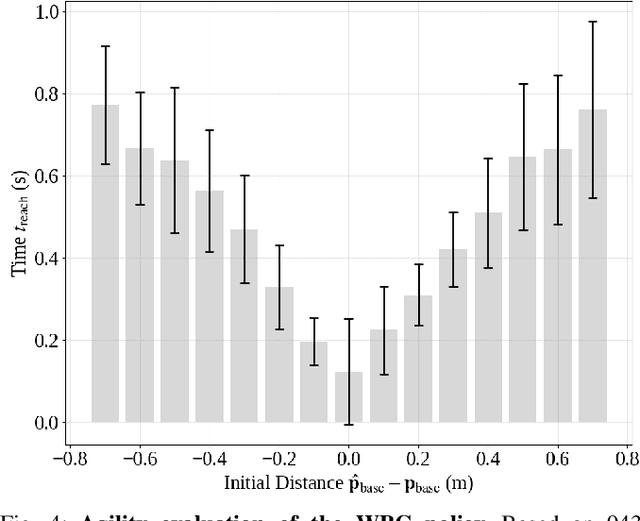

Humanoid robots have recently achieved impressive progress in locomotion and whole-body control, yet they remain constrained in tasks that demand rapid interaction with dynamic environments through manipulation. Table tennis exemplifies such a challenge: with ball speeds exceeding 5 m/s, players must perceive, predict, and act within sub-second reaction times, requiring both agility and precision. To address this, we present a hierarchical framework for humanoid table tennis that integrates a model-based planner for ball trajectory prediction and racket target planning with a reinforcement learning-based whole-body controller. The planner determines striking position, velocity and timing, while the controller generates coordinated arm and leg motions that mimic human strikes and maintain stability and agility across consecutive rallies. Moreover, to encourage natural movements, human motion references are incorporated during training. We validate our system on a general-purpose humanoid robot, achieving up to 106 consecutive shots with a human opponent and sustained exchanges against another humanoid. These results demonstrate real-world humanoid table tennis with sub-second reactive control, marking a step toward agile and interactive humanoid behaviors.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Aug 13, 2025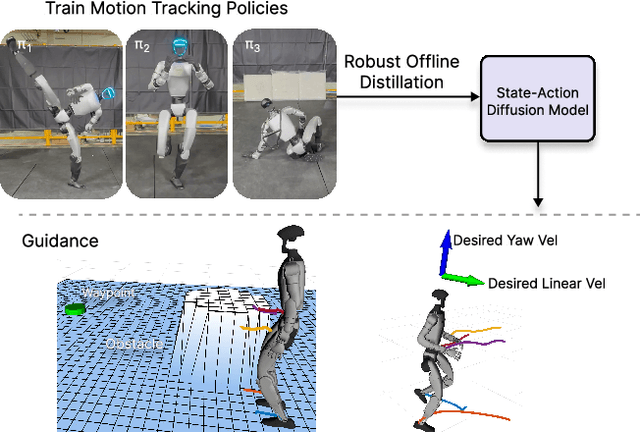



Learning skills from human motions offers a promising path toward generalizable policies for versatile humanoid whole-body control, yet two key cornerstones are missing: (1) a high-quality motion tracking framework that faithfully transforms large-scale kinematic references into robust and extremely dynamic motions on real hardware, and (2) a distillation approach that can effectively learn these motion primitives and compose them to solve downstream tasks. We address these gaps with BeyondMimic, a real-world framework to learn from human motions for versatile and naturalistic humanoid control via guided diffusion. Our framework provides a motion tracking pipeline capable of challenging skills such as jumping spins, sprinting, and cartwheels with state-of-the-art motion quality. Moving beyond simply mimicking existing motions, we further introduce a unified diffusion policy that enables zero-shot task-specific control at test time using simple cost functions. Deployed on hardware, BeyondMimic performs diverse tasks at test time, including waypoint navigation, joystick teleoperation, and obstacle avoidance, bridging sim-to-real motion tracking and flexible synthesis of human motion primitives for whole-body control. https://beyondmimic.github.io/.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025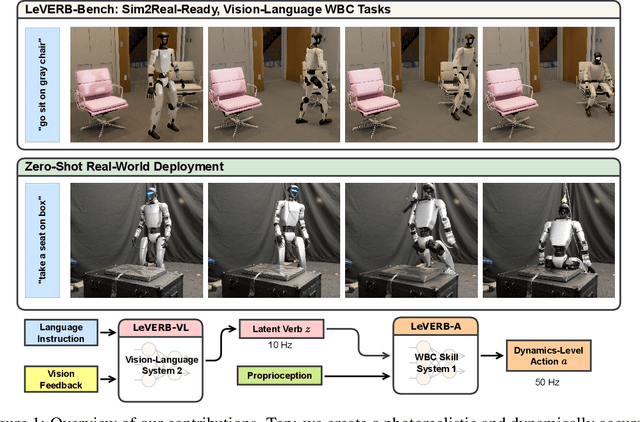
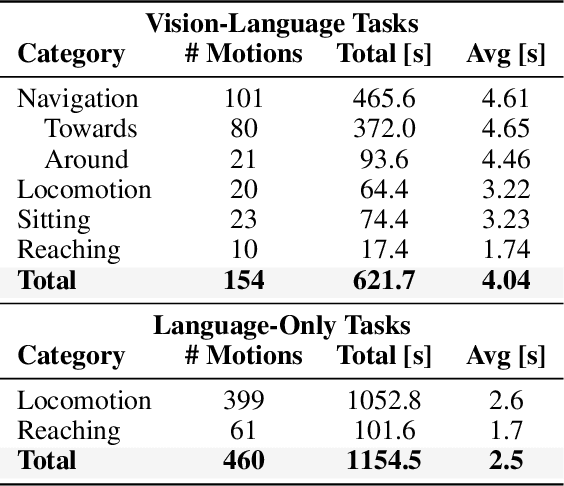
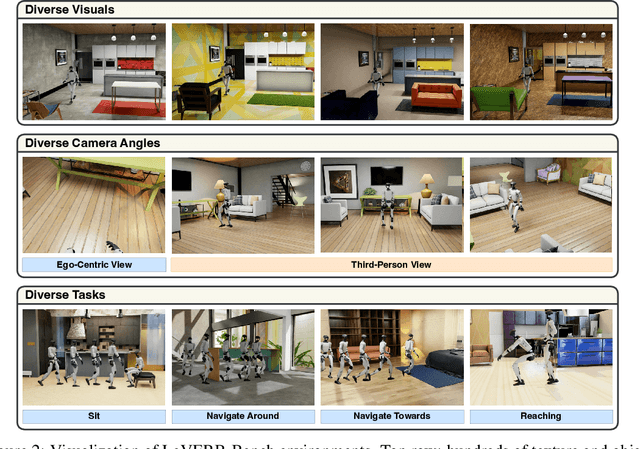
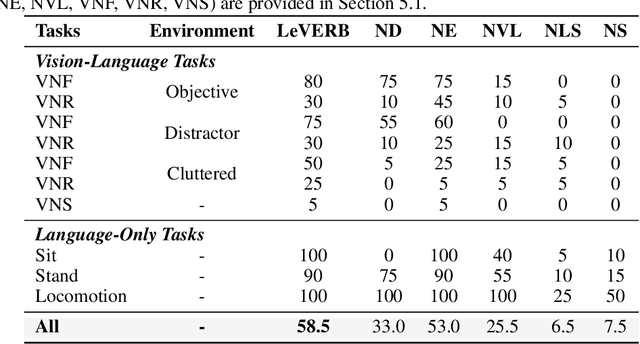
Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation
Mar 10, 2025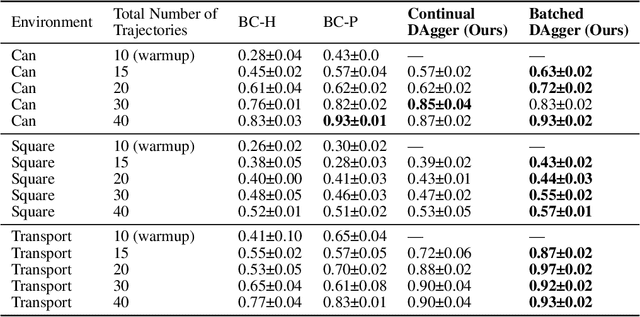
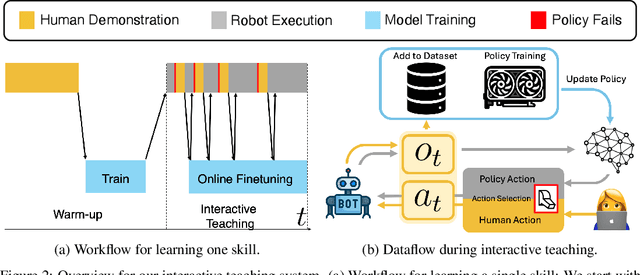
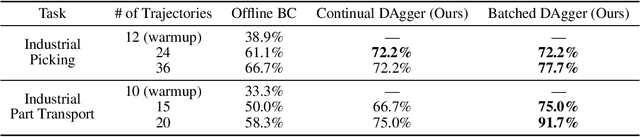
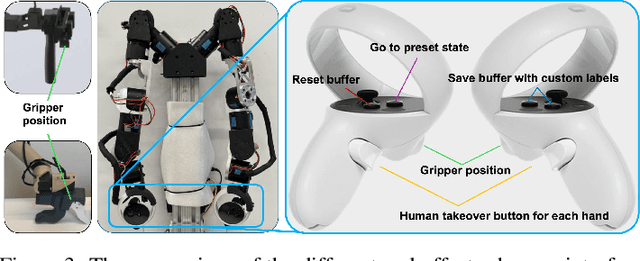
Learning from human demonstration is an effective approach for learning complex manipulation skills. However, existing approaches heavily focus on learning from passive human demonstration data for its simplicity in data collection. Interactive human teaching has appealing theoretical and practical properties, but they are not well supported by existing human-robot interfaces. This paper proposes a novel system that enables seamless control switching between human and an autonomous policy for bi-manual manipulation tasks, enabling more efficient learning of new tasks. This is achieved through a compliant, bilateral teleoperation system. Through simulation and hardware experiments, we demonstrate the value of our system in an interactive human teaching for learning complex bi-manual manipulation skills.
DDAT: Diffusion Policies Enforcing Dynamically Admissible Robot Trajectories
Feb 20, 2025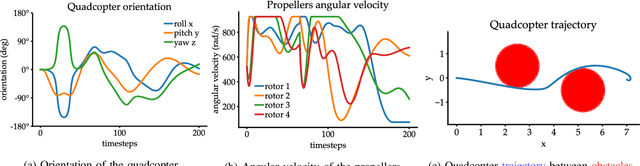
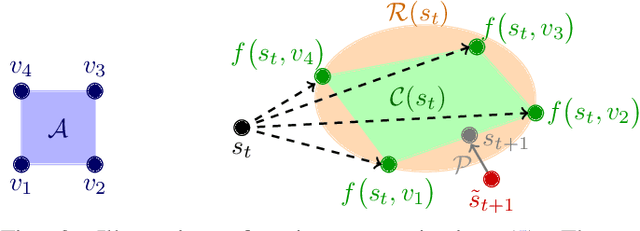
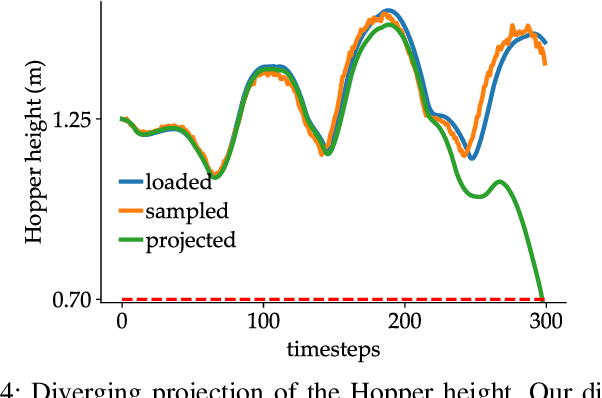
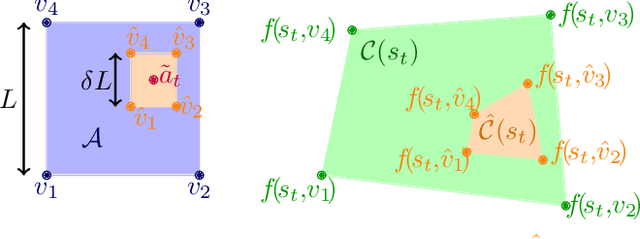
Diffusion models excel at creating images and videos thanks to their multimodal generative capabilities. These same capabilities have made diffusion models increasingly popular in robotics research, where they are used for generating robot motion. However, the stochastic nature of diffusion models is fundamentally at odds with the precise dynamical equations describing the feasible motion of robots. Hence, generating dynamically admissible robot trajectories is a challenge for diffusion models. To alleviate this issue, we introduce DDAT: Diffusion policies for Dynamically Admissible Trajectories to generate provably admissible trajectories of black-box robotic systems using diffusion models. A sequence of states is a dynamically admissible trajectory if each state of the sequence belongs to the reachable set of its predecessor by the robot's equations of motion. To generate such trajectories, our diffusion policies project their predictions onto a dynamically admissible manifold during both training and inference to align the objective of the denoiser neural network with the dynamical admissibility constraint. The auto-regressive nature of these projections along with the black-box nature of robot dynamics render these projections immensely challenging. We thus enforce admissibility by iteratively sampling a polytopic under-approximation of the reachable set of a state onto which we project its predicted successor, before iterating this process with the projected successor. By producing accurate trajectories, this projection eliminates the need for diffusion models to continually replan, enabling one-shot long-horizon trajectory planning. We demonstrate that our framework generates higher quality dynamically admissible robot trajectories through extensive simulations on a quadcopter and various MuJoCo environments, along with real-world experiments on a Unitree GO1 and GO2.
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org