 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Apr 24, 2025Despite significant interest and advancements in humanoid robotics, most existing commercially available hardware remains high-cost, closed-source, and non-transparent within the robotics community. This lack of accessibility and customization hinders the growth of the field and the broader development of humanoid technologies. To address these challenges and promote democratization in humanoid robotics, we demonstrate Berkeley Humanoid Lite, an open-source humanoid robot designed to be accessible, customizable, and beneficial for the entire community. The core of this design is a modular 3D-printed gearbox for the actuators and robot body. All components can be sourced from widely available e-commerce platforms and fabricated using standard desktop 3D printers, keeping the total hardware cost under $5,000 (based on U.S. market prices). The design emphasizes modularity and ease of fabrication. To address the inherent limitations of 3D-printed gearboxes, such as reduced strength and durability compared to metal alternatives, we adopted a cycloidal gear design, which provides an optimal form factor in this context. Extensive testing was conducted on the 3D-printed actuators to validate their durability and alleviate concerns about the reliability of plastic components. To demonstrate the capabilities of Berkeley Humanoid Lite, we conducted a series of experiments, including the development of a locomotion controller using reinforcement learning. These experiments successfully showcased zero-shot policy transfer from simulation to hardware, highlighting the platform's suitability for research validation. By fully open-sourcing the hardware design, embedded code, and training and deployment frameworks, we aim for Berkeley Humanoid Lite to serve as a pivotal step toward democratizing the development of humanoid robotics. All resources are available at https://lite.berkeley-humanoid.org.
DiffuseLoco: Real-Time Legged Locomotion Control with Diffusion from Offline Datasets
Apr 30, 2024
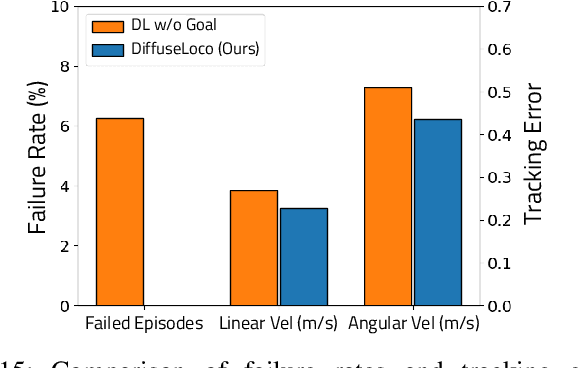
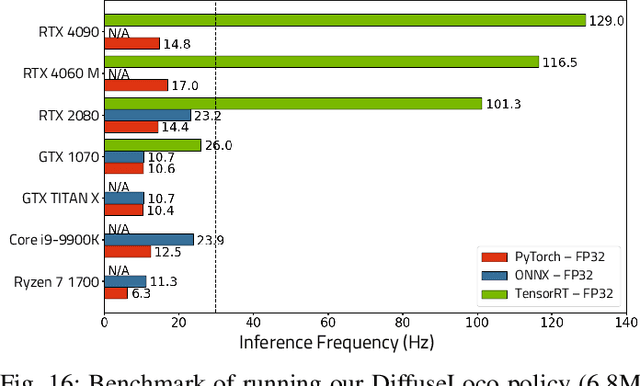

This work introduces DiffuseLoco, a framework for training multi-skill diffusion-based policies for dynamic legged locomotion from offline datasets, enabling real-time control of diverse skills on robots in the real world. Offline learning at scale has led to breakthroughs in computer vision, natural language processing, and robotic manipulation domains. However, scaling up learning for legged robot locomotion, especially with multiple skills in a single policy, presents significant challenges for prior online reinforcement learning methods. To address this challenge, we propose a novel, scalable framework that leverages diffusion models to directly learn from offline multimodal datasets with a diverse set of locomotion skills. With design choices tailored for real-time control in dynamical systems, including receding horizon control and delayed inputs, DiffuseLoco is capable of reproducing multimodality in performing various locomotion skills, zero-shot transfer to real quadrupedal robots, and it can be deployed on edge computing devices. Furthermore, DiffuseLoco demonstrates free transitions between skills and robustness against environmental variations. Through extensive benchmarking in real-world experiments, DiffuseLoco exhibits better stability and velocity tracking performance compared to prior reinforcement learning and non-diffusion-based behavior cloning baselines. The design choices are validated via comprehensive ablation studies. This work opens new possibilities for scaling up learning-based legged locomotion controllers through the scaling of large, expressive models and diverse offline datasets.
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
Oct 10, 2022
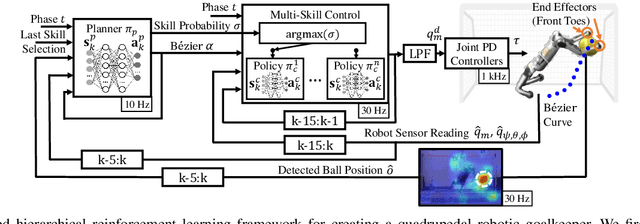
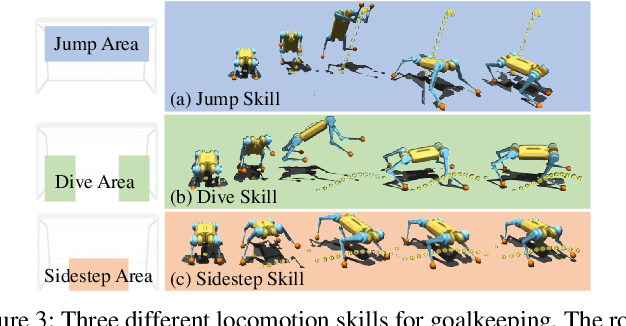
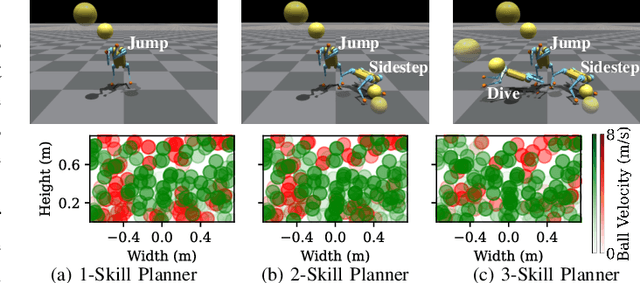
We present a reinforcement learning (RL) framework that enables quadrupedal robots to perform soccer goalkeeping tasks in the real world. Soccer goalkeeping using quadrupeds is a challenging problem, that combines highly dynamic locomotion with precise and fast non-prehensile object (ball) manipulation. The robot needs to react to and intercept a potentially flying ball using dynamic locomotion maneuvers in a very short amount of time, usually less than one second. In this paper, we propose to address this problem using a hierarchical model-free RL framework. The first component of the framework contains multiple control policies for distinct locomotion skills, which can be used to cover different regions of the goal. Each control policy enables the robot to track random parametric end-effector trajectories while performing one specific locomotion skill, such as jump, dive, and sidestep. These skills are then utilized by the second part of the framework which is a high-level planner to determine a desired skill and end-effector trajectory in order to intercept a ball flying to different regions of the goal. We deploy the proposed framework on a Mini Cheetah quadrupedal robot and demonstrate the effectiveness of our framework for various agile interceptions of a fast-moving ball in the real world.
Collaborative Navigation and Manipulation of a Cable-towed Load by Multiple Quadrupedal Robots
Jun 29, 2022
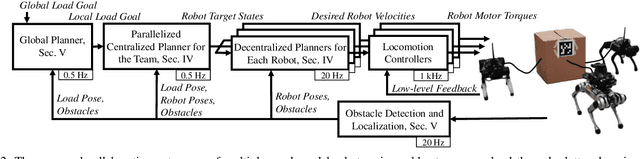
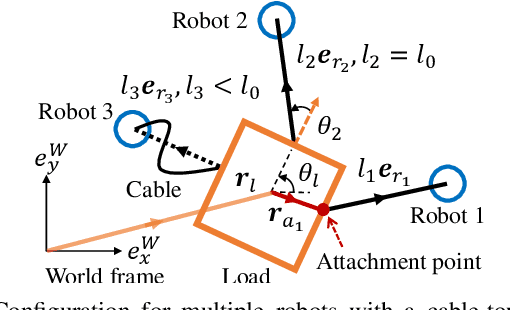
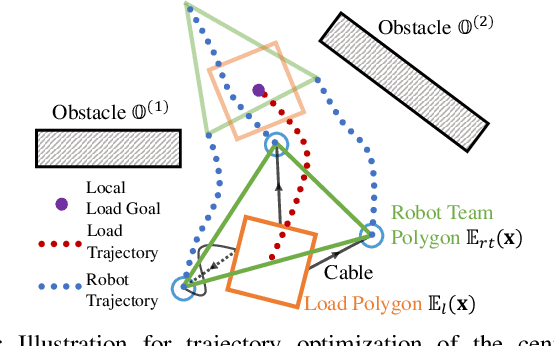
This paper tackles the problem of robots collaboratively towing a load with cables to a specified goal location while avoiding collisions in real time. The introduction of cables (as opposed to rigid links) enables the robotic team to travel through narrow spaces by changing its intrinsic dimensions through slack/taut switches of the cable. However, this is a challenging problem because of the hybrid mode switches and the dynamical coupling among multiple robots and the load. Previous attempts at addressing such a problem were performed offline and do not consider avoiding obstacles online. In this paper, we introduce a cascaded planning scheme with a parallelized centralized trajectory optimization that deals with hybrid mode switches. We additionally develop a set of decentralized planners per robot, which enables our approach to solve the problem of collaborative load manipulation online. We develop and demonstrate one of the first collaborative autonomy framework that is able to move a cable-towed load, which is too heavy to move by a single robot, through narrow spaces with real-time feedback and reactive planning in experiments.