 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating and Scaling MPC-Guided Reinforcement Learning for Humanoid Locomotion and Manipulation
Jun 04, 2026In humanoid motion control, model predictive control (MPC) offers physically grounded prediction and constraint handling, while reinforcement learning (RL) enables robust whole-body skills through large-scale simulation. However, using MPC inside RL often requires time-consuming problem construction or excessive training overhead, making such frameworks difficult to justify in practice. This work studies efficient training-time MPC guidance for humanoid locomotion and manipulation, termed MPC-RL. We introduce a centroidal-dynamics MPC reward formulation that leverages guidance from MPC trajectories in training time. To make this practical in massively parallel RL, we develop $π^n$MPC, a parallel-in-horizon and construction-free batched GPU MPC solver that operates directly on time-varying dynamics to avoid high memory usage and pre-compilation. Through a variety of comparative studies and hardware validations, we have found that MPC-RL achieves superior performance in locomotion and manipulation skills. The code base is available at https://github.com/junhengl/mpc-rl.
HANDOFF: Humanoid Agentic Task-Space Whole-Body Control via Distilled Complementary Teachers
Jun 04, 2026For a humanoid robot to be deployed in the real world, the choice of command space (i.e., the interface between task planning and whole-body control) is crucial. Existing whole-body controllers typically demand dense kinematic or spatial references that planners struggle to synthesize from task semantics. We instead propose a compact, explicit interface that is intuitive, general, modular, and expressive enough for diverse manipulation skills. To this end, we introduce HANDOFF, a single humanoid whole-body controller that follows this interface and is distilled via multi-teacher KL distillation under a context-conditioned gating scheme into a mixture-of-experts student from three complementary specialists: whole-body motion tracking with safety-filtered data, locomotion, and fall-recovery. On the Unitree G1, HANDOFF matches state-of-the-art velocity tracking and offers one of the largest robust manipulation workspaces. We further demonstrate hardware feasibility through multiple natural-language-driven task roll-outs, powered by a VLM-driven agentic planner with no task-specific data or controller fine-tuning.
MIRROR: Visual Motion Imitation via Real-time Retargeting and Teleoperation with Parallel Differential Inverse Kinematics
Mar 25, 2026Real-time humanoid teleoperation requires inverse kinematics (IK) solvers that are both responsive and constraint-safe under kinematic redundancy and self-collision constraints. While differential IK enables efficient online retargeting, its locally linearized updates are inherently basin-dependent and often become trapped near joint limits, singularities, or active collision boundaries, leading to unsafe or stagnant behavior. We propose a GPU-parallelized, continuation-based differential IK that improves escape from such constraint-induced local minima while preserving real-time performance, promoting safety and stability. Multiple constrained IK quadratic programs are evaluated in parallel, together with a self-collision avoidance control barrier function (CBF), and a Lyapunov-based progression criterion selects updates that reduce the final global task-space error. The method is paired with a visual skeletal pose estimation pipeline that enables robust, real-time upper-body teleoperation on the THEMIS humanoid robot hardware in real-world tasks.
Safe-SAGE: Social-Semantic Adaptive Guidance for Safe Engagement through Laplace-Modulated Poisson Safety Functions
Mar 05, 2026Traditional safety-critical control methods, such as control barrier functions, suffer from semantic blindness, exhibiting the same behavior around obstacles regardless of contextual significance. This limitation leads to the uniform treatment of all obstacles, despite their differing semantic meanings. We present Safe-SAGE (Social-Semantic Adaptive Guidance for Safe Engagement), a unified framework that bridges the gap between high-level semantic understanding and low-level safety-critical control through a Poisson safety function (PSF) modulated using a Laplace guidance field. Our approach perceives the environment by fusing multi-sensor point clouds with vision-based instance segmentation and persistent object tracking to maintain up-to-date semantics beyond the camera's field of view. A multi-layer safety filter is then used to modulate system inputs to achieve safe navigation using this semantic understanding of the environment. This safety filter consists of both a model predictive control layer and a control barrier function layer. Both layers utilize the PSF and flux modulation of the guidance field to introduce varying levels of conservatism and multi-agent passing norms for different obstacles in the environment. Our framework enables legged robots to navigate semantically rich, dynamic environments with context-dependent safety margins while maintaining rigorous safety guarantees.
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds
Jan 09, 2026Bipedal humanoid robots must precisely coordinate balance, timing, and contact decisions when locomoting on constrained footholds such as stepping stones, beams, and planks -- even minor errors can lead to catastrophic failure. Classical optimization and control pipelines handle these constraints well but depend on highly accurate mathematical representations of terrain geometry, making them prone to error when perception is noisy or incomplete. Meanwhile, reinforcement learning has shown strong resilience to disturbances and modeling errors, yet end-to-end policies rarely discover the precise foothold placement and step sequencing required for discontinuous terrain. These contrasting limitations motivate approaches that guide learning with physics-based structure rather than relying purely on reward shaping. In this work, we introduce a locomotion framework in which a reduced-order stepping planner supplies dynamically consistent motion targets that steer the RL training process via Control Lyapunov Function (CLF) rewards. This combination of structured footstep planning and data-driven adaptation produces accurate, agile, and hardware-validated stepping-stone locomotion on a humanoid robot, substantially improving reliability compared to conventional model-free reinforcement-learning baselines.
CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions
Oct 16, 2025Reinforcement learning (RL), while powerful and expressive, can often prioritize performance at the expense of safety. Yet safety violations can lead to catastrophic outcomes in real-world deployments. Control Barrier Functions (CBFs) offer a principled method to enforce dynamic safety -- traditionally deployed \emph{online} via safety filters. While the result is safe behavior, the fact that the RL policy does not have knowledge of the CBF can lead to conservative behaviors. This paper proposes CBF-RL, a framework for generating safe behaviors with RL by enforcing CBFs \emph{in training}. CBF-RL has two key attributes: (1) minimally modifying a nominal RL policy to encode safety constraints via a CBF term, (2) and safety filtering of the policy rollouts in training. Theoretically, we prove that continuous-time safety filters can be deployed via closed-form expressions on discrete-time roll-outs. Practically, we demonstrate that CBF-RL internalizes the safety constraints in the learned policy -- both enforcing safer actions and biasing towards safer rewards -- enabling safe deployment without the need for an online safety filter. We validate our framework through ablation studies on navigation tasks and on the Unitree G1 humanoid robot, where CBF-RL enables safer exploration, faster convergence, and robust performance under uncertainty, enabling the humanoid robot to avoid obstacles and climb stairs safely in real-world settings without a runtime safety filter.
Bracing for Impact: Robust Humanoid Push Recovery and Locomotion with Reduced Order Models
May 16, 2025



Push recovery during locomotion will facilitate the deployment of humanoid robots in human-centered environments. In this paper, we present a unified framework for walking control and push recovery for humanoid robots, leveraging the arms for push recovery while dynamically walking. The key innovation is to use the environment, such as walls, to facilitate push recovery by combining Single Rigid Body model predictive control (SRB-MPC) with Hybrid Linear Inverted Pendulum (HLIP) dynamics to enable robust locomotion, push detection, and recovery by utilizing the robot's arms to brace against such walls and dynamically adjusting the desired contact forces and stepping patterns. Extensive simulation results on a humanoid robot demonstrate improved perturbation rejection and tracking performance compared to HLIP alone, with the robot able to recover from pushes up to 100N for 0.2s while walking at commanded speeds up to 0.5m/s. Robustness is further validated in scenarios with angled walls and multi-directional pushes.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
May 16, 2025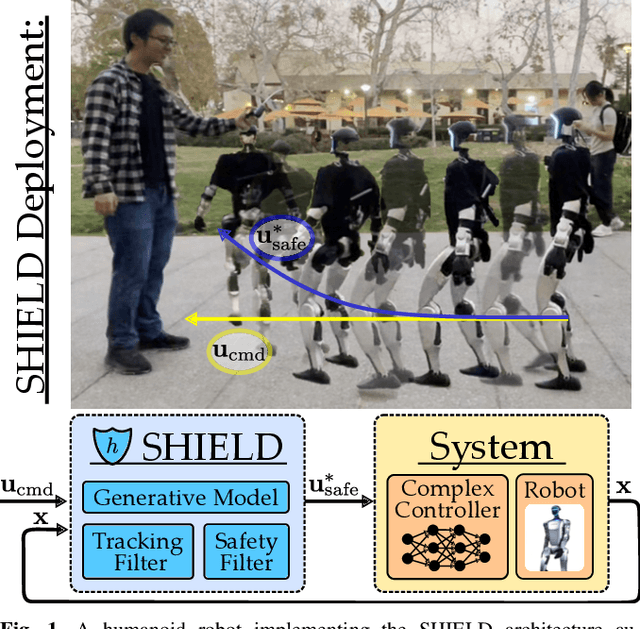

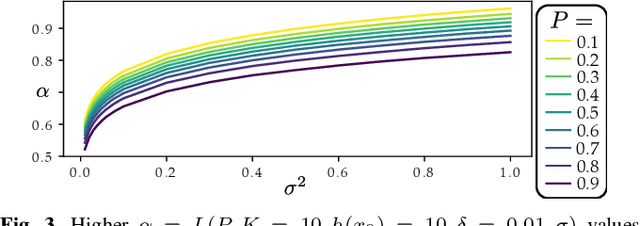
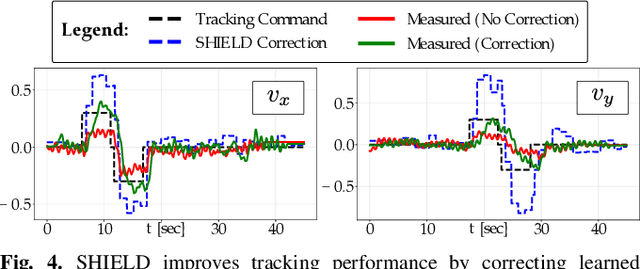
Robot learning has produced remarkably effective ``black-box'' controllers for complex tasks such as dynamic locomotion on humanoids. Yet ensuring dynamic safety, i.e., constraint satisfaction, remains challenging for such policies. Reinforcement learning (RL) embeds constraints heuristically through reward engineering, and adding or modifying constraints requires retraining. Model-based approaches, like control barrier functions (CBFs), enable runtime constraint specification with formal guarantees but require accurate dynamics models. This paper presents SHIELD, a layered safety framework that bridges this gap by: (1) training a generative, stochastic dynamics residual model using real-world data from hardware rollouts of the nominal controller, capturing system behavior and uncertainties; and (2) adding a safety layer on top of the nominal (learned locomotion) controller that leverages this model via a stochastic discrete-time CBF formulation enforcing safety constraints in probability. The result is a minimally-invasive safety layer that can be added to the existing autonomy stack to give probabilistic guarantees of safety that balance risk and performance. In hardware experiments on an Unitree G1 humanoid, SHIELD enables safe navigation (obstacle avoidance) through varied indoor and outdoor environments using a nominal (unknown) RL controller and onboard perception.
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
Oct 10, 2022
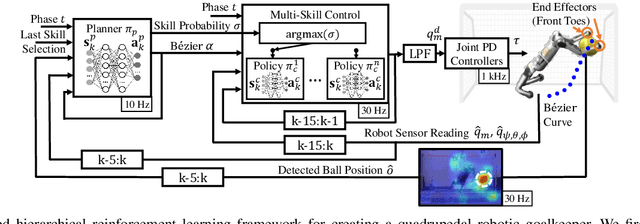
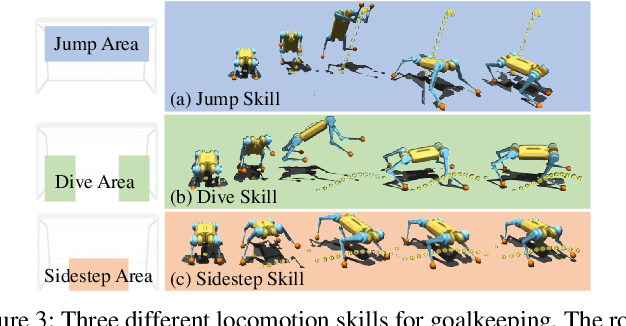
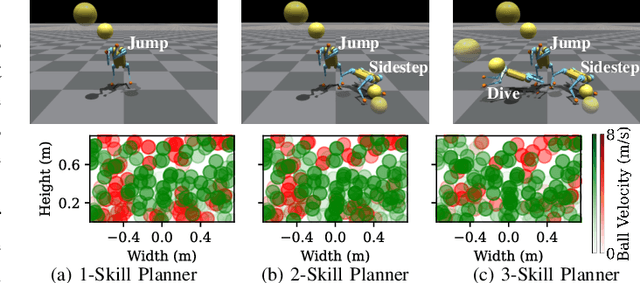
We present a reinforcement learning (RL) framework that enables quadrupedal robots to perform soccer goalkeeping tasks in the real world. Soccer goalkeeping using quadrupeds is a challenging problem, that combines highly dynamic locomotion with precise and fast non-prehensile object (ball) manipulation. The robot needs to react to and intercept a potentially flying ball using dynamic locomotion maneuvers in a very short amount of time, usually less than one second. In this paper, we propose to address this problem using a hierarchical model-free RL framework. The first component of the framework contains multiple control policies for distinct locomotion skills, which can be used to cover different regions of the goal. Each control policy enables the robot to track random parametric end-effector trajectories while performing one specific locomotion skill, such as jump, dive, and sidestep. These skills are then utilized by the second part of the framework which is a high-level planner to determine a desired skill and end-effector trajectory in order to intercept a ball flying to different regions of the goal. We deploy the proposed framework on a Mini Cheetah quadrupedal robot and demonstrate the effectiveness of our framework for various agile interceptions of a fast-moving ball in the real world.
GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots
Sep 12, 2022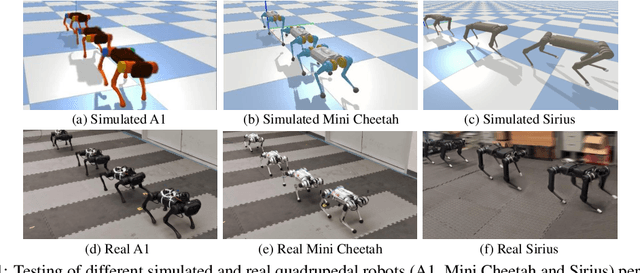

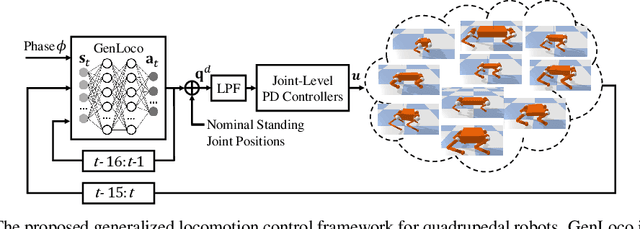

Recent years have seen a surge in commercially-available and affordable quadrupedal robots, with many of these platforms being actively used in research and industry. As the availability of legged robots grows, so does the need for controllers that enable these robots to perform useful skills. However, most learning-based frameworks for controller development focus on training robot-specific controllers, a process that needs to be repeated for every new robot. In this work, we introduce a framework for training generalized locomotion (GenLoco) controllers for quadrupedal robots. Our framework synthesizes general-purpose locomotion controllers that can be deployed on a large variety of quadrupedal robots with similar morphologies. We present a simple but effective morphology randomization method that procedurally generates a diverse set of simulated robots for training. We show that by training a controller on this large set of simulated robots, our models acquire more general control strategies that can be directly transferred to novel simulated and real-world robots with diverse morphologies, which were not observed during training.