 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPAL: Omnidirectional Path-efficient Aerial 3D expLoration
May 25, 2026Autonomous exploration is critical for robot mapping unknown environments. Desirable characteristics of exploration algorithms include compute efficiency and small traversed distance during the exploration process. Motivated by these, we present Omnidirectional Path-efficient Aerial 3D expLoration (OPAL), an exploration framework centered on deliberate 360-degree yaw rotation at ambiguous branch points rather than compute-heavy global tour planning. We devise multiple variants of OPAL to determine the frontier-selection strategy once the yaw pan is completed. One variant is model-free, while others use large language models (LLMs) or vision-language models (VLMs). We characterize the performance of these variants while varying the vicinity search radius to include frontiers in the selection process. Through simulations we find that although the time-consuming in-place yaw rotation increases total exploration time relative to more computationally complex baselines such as EDEN and FALCON, OPAL is computationally simpler and achieves shorter travel distances and higher coverage-versus-distance area under the curve. We also show that adjusting the frontier-selection search radius enables a tradeoff between travel distance and total exploration time. We verify our results on a Modal AI drone in two indoor environments by comparing OPAL against FALCON, and find that the traveled distance for a variant of OPAL to be as much as 25% lower than FALCON.
Vision-Guided Outdoor Flight and Obstacle Evasion via Reinforcement Learning
May 23, 2026Although quadcopters boast impressive traversal capabilities enabled by their omnidirectional maneuverability, the need for continuous pilot control in complex environments impedes their application in GNSS and telemetry-denied scenarios. To this end, we propose a novel sensorimotor policy that uses stereo-vision depth and visual-inertial odometry (VIO) to autonomously navigate through obstacles in an unknown environment to reach a goal point. The policy is comprised of a pre-trained autoencoder as the perception head followed by a planning and control LSTM network which outputs velocity commands that can be followed by an off-the-shelf commercial drone. We leverage reinforcement and privileged learning paradigms to train the policy in simulation through a two-stage process: 1) initial training with optimal trajectories generated by a global motion planner acting as a supervisory backbone, 2) further fine-tuning in a curriculum environment. To bridge the sim-to-real gap, we employ domain randomization and reward shaping to create a policy that is both robust to noise and domain shift. In outdoor experiments, our approach achieves successful zero-shot transfer to both obstacle environments and a drone platform that were never encountered during training.
Semantic-Aware Guided Drone Exploration for Language-Conditioned 3D Indoor Mapping
May 22, 2026We present Semantic-Aware Guided Exploration, SAGE, a system for open-vocabulary exploration in unknown 3D indoor environments that preserves coverage-oriented behavior while allowing semantic cues to reprioritize frontier selection. Building on the FALCON volumetric explorer, SAGE integrates Contrastive Language-Image Pre-training (CLIP) via four key components: object-centric embedding storage, a temporal cache that projects recent observations onto the free-unknown boundary, object frontiers for high-similarity detections, and a unified semantic-geometric planning cost. This cost function bounds semantic reweighting influence, ensuring frontiers are prioritized without sacrificing total coverage. In Matterport3D-based simulations, SAGE outperforms FALCON and a semantic-only ablation in object discovery across map-query pairs. Compared to Finding Things in the Unknown (FTU), SAGE completes exploration 9.0 to 25.9 times faster across the nine shared map-query pairs, achieving a mean speedup of 13.7. Furthermore, SAGE achieves substantially higher volumetric throughput than FTU. Finally, we deploy SAGE in five real-world flights in two environments on a Modal AI Starling 2 quadrotor with onboard sensing and planning, and offboard CLIP inference. Comparing SAGE and FALCON, we find that while FALCON results in faster exploration and shorter mapping trajectories, SAGE outperforms FALCON in terms of object discovery.
Autonomous Frontier-Based Exploration with VLM Guidance
May 22, 2026Autonomous robotic exploration of unknown and hazardous environments, a long-standing challenge, can be significantly improved by leveraging the advanced reasoning of Vision-Language Models (VLMs). We introduce a novel exploration pipeline where a VLM performs high-level strategic decision-making, guiding a conventional low-level robotics control stack. At decision points, the robot generates a multimodal prompt with its current map and visual imagery of potential paths, or frontiers. The VLM analyzes this prompt to select the most promising frontier, replacing simple geometric heuristics with contextual spatial reasoning. This approach, validated in simulation across six indoor environments, improves map coverage by up to 24\% over existing methods. Our pipeline is lightweight, training-free, and easily transferable to any robot with standard sensors and an internet connection.
Indoor Asset Detection in Large Scale 360° Drone-Captured Imagery via 3D Gaussian Splatting
Apr 07, 2026We present an approach for object-level detection and segmentation of target indoor assets in 3D Gaussian Splatting (3DGS) scenes, reconstructed from 360° drone-captured imagery. We introduce a 3D object codebook that jointly leverages mask semantics and spatial information of their corresponding Gaussian primitives to guide multi-view mask association and indoor asset detection. By integrating 2D object detection and segmentation models with semantically and spatially constrained merging procedures, our method aggregates masks from multiple views into coherent 3D object instances. Experiments on two large indoor scenes demonstrate reliable multi-view mask consistency, improving F1 score by 65% over state-of-the-art baselines, and accurate object-level 3D indoor asset detection, achieving an 11% mAP gain over baseline methods.
Versatile Locomotion Skills for Hexapod Robots
Dec 14, 2024



Hexapod robots are potentially suitable for carrying out tasks in cluttered environments since they are stable, compact, and light weight. They also have multi-joint legs and variable height bodies that make them good candidates for tasks such as stairs climbing and squeezing under objects in a typical home environment or an attic. Expanding on our previous work on joist climbing in attics, we train a legged hexapod equipped with a depth camera and visual inertial odometry (VIO) to perform three tasks: climbing stairs, avoiding obstacles, and squeezing under obstacles such as a table. Our policies are trained with simulation data only and can be deployed on lowcost hardware not requiring real-time joint state feedback. We train our model in a teacher-student model with 2 phases: In phase 1, we use reinforcement learning with access to privileged information such as height maps and joint feedback. In phase 2, we use supervised learning to distill the model into one with access to only onboard observations, consisting of egocentric depth images and robot pose captured by a tracking VIO camera. By manipulating available privileged information, constructing simulation terrains, and refining reward functions during phase 1 training, we are able to train the robots with skills that are robust in non-ideal physical environments. We demonstrate successful sim-to-real transfer and achieve high success rates across all three tasks in physical experiments.
Swap Path Network for Robust Person Search Pre-training
Dec 06, 2024



In person search, we detect and rank matches to a query person image within a set of gallery scenes. Most person search models make use of a feature extraction backbone, followed by separate heads for detection and re-identification. While pre-training methods for vision backbones are well-established, pre-training additional modules for the person search task has not been previously examined. In this work, we present the first framework for end-to-end person search pre-training. Our framework splits person search into object-centric and query-centric methodologies, and we show that the query-centric framing is robust to label noise, and trainable using only weakly-labeled person bounding boxes. Further, we provide a novel model dubbed Swap Path Net (SPNet) which implements both query-centric and object-centric training objectives, and can swap between the two while using the same weights. Using SPNet, we show that query-centric pre-training, followed by object-centric fine-tuning, achieves state-of-the-art results on the standard PRW and CUHK-SYSU person search benchmarks, with 96.4% mAP on CUHK-SYSU and 61.2% mAP on PRW. In addition, we show that our method is more effective, efficient, and robust for person search pre-training than recent backbone-only pre-training alternatives.
Scalable Indoor Novel-View Synthesis using Drone-Captured 360 Imagery with 3D Gaussian Splatting
Oct 15, 2024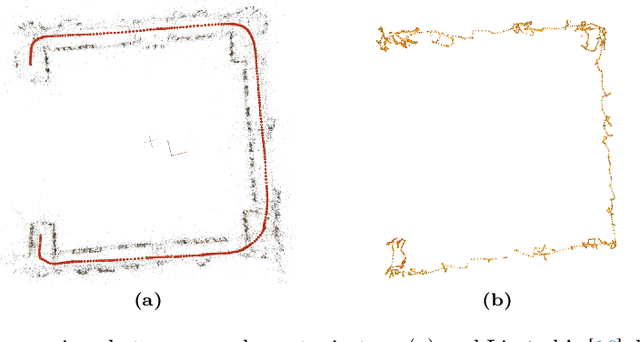

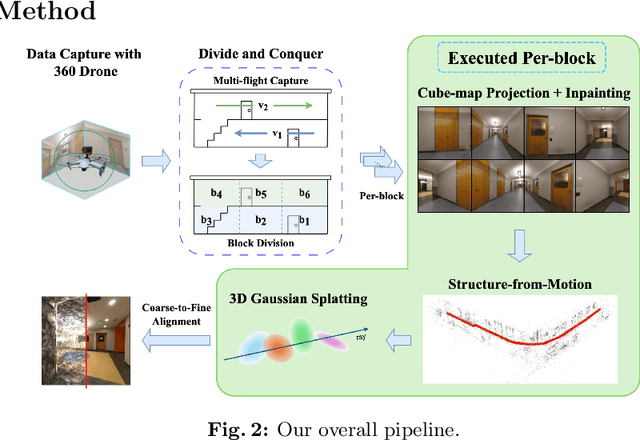
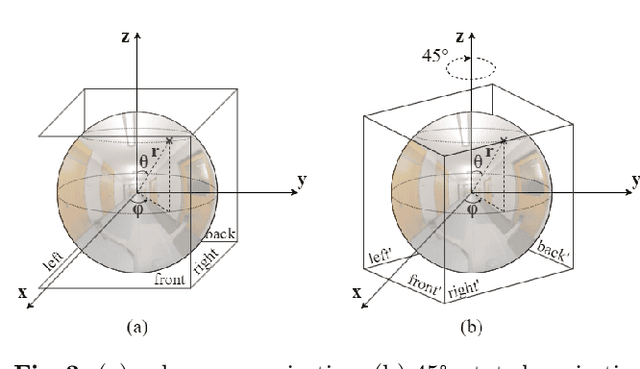
Scene reconstruction and novel-view synthesis for large, complex, multi-story, indoor scenes is a challenging and time-consuming task. Prior methods have utilized drones for data capture and radiance fields for scene reconstruction, both of which present certain challenges. First, in order to capture diverse viewpoints with the drone's front-facing camera, some approaches fly the drone in an unstable zig-zag fashion, which hinders drone-piloting and generates motion blur in the captured data. Secondly, most radiance field methods do not easily scale to arbitrarily large number of images. This paper proposes an efficient and scalable pipeline for indoor novel-view synthesis from drone-captured 360 videos using 3D Gaussian Splatting. 360 cameras capture a wide set of viewpoints, allowing for comprehensive scene capture under a simple straightforward drone trajectory. To scale our method to large scenes, we devise a divide-and-conquer strategy to automatically split the scene into smaller blocks that can be reconstructed individually and in parallel. We also propose a coarse-to-fine alignment strategy to seamlessly match these blocks together to compose the entire scene. Our experiments demonstrate marked improvement in both reconstruction quality, i.e. PSNR and SSIM, and computation time compared to prior approaches.
Adapting Segment Anything Model to Melanoma Segmentation in Microscopy Slide Images
Oct 03, 2024



Melanoma segmentation in Whole Slide Images (WSIs) is useful for prognosis and the measurement of crucial prognostic factors such as Breslow depth and primary invasive tumor size. In this paper, we present a novel approach that uses the Segment Anything Model (SAM) for automatic melanoma segmentation in microscopy slide images. Our method employs an initial semantic segmentation model to generate preliminary segmentation masks that are then used to prompt SAM. We design a dynamic prompting strategy that uses a combination of centroid and grid prompts to achieve optimal coverage of the super high-resolution slide images while maintaining the quality of generated prompts. To optimize for invasive melanoma segmentation, we further refine the prompt generation process by implementing in-situ melanoma detection and low-confidence region filtering. We select Segformer as the initial segmentation model and EfficientSAM as the segment anything model for parameter-efficient fine-tuning. Our experimental results demonstrate that this approach not only surpasses other state-of-the-art melanoma segmentation methods but also significantly outperforms the baseline Segformer by 9.1% in terms of IoU.
Gallery Filter Network for Person Search
Oct 25, 2022



In person search, we aim to localize a query person from one scene in other gallery scenes. The cost of this search operation is dependent on the number of gallery scenes, making it beneficial to reduce the pool of likely scenes. We describe and demonstrate the Gallery Filter Network (GFN), a novel module which can efficiently discard gallery scenes from the search process, and benefit scoring for persons detected in remaining scenes. We show that the GFN is robust under a range of different conditions by testing on different retrieval sets, including cross-camera, occluded, and low-resolution scenarios. In addition, we develop the base SeqNeXt person search model, which improves and simplifies the original SeqNet model. We show that the SeqNeXt+GFN combination yields significant performance gains over other state-of-the-art methods on the standard PRW and CUHK-SYSU person search datasets. To aid experimentation for this and other models, we provide standardized tooling for the data processing and evaluation pipeline typically used for person search research.