 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Aware Human-machine Collaboration in Camouflaged Object Detection
Feb 12, 2025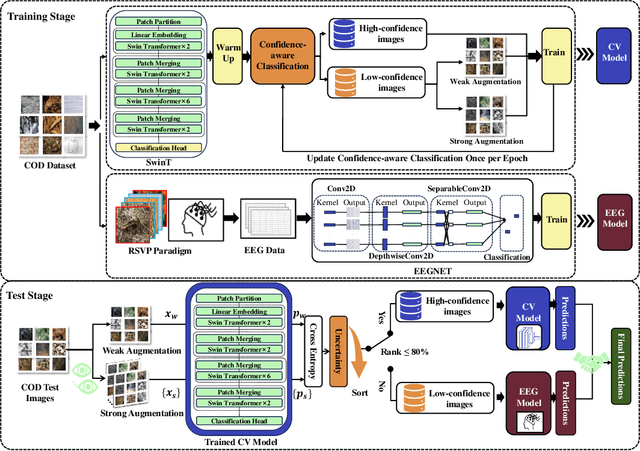
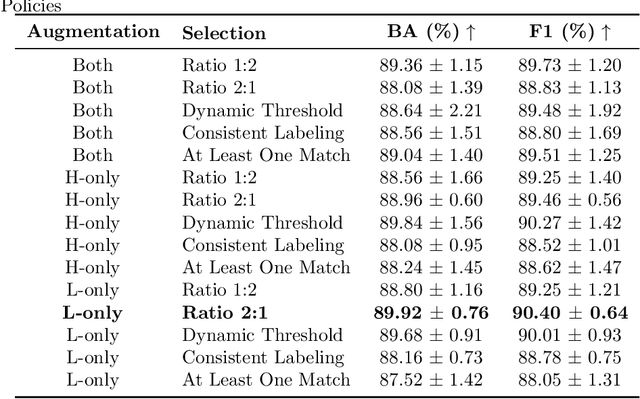
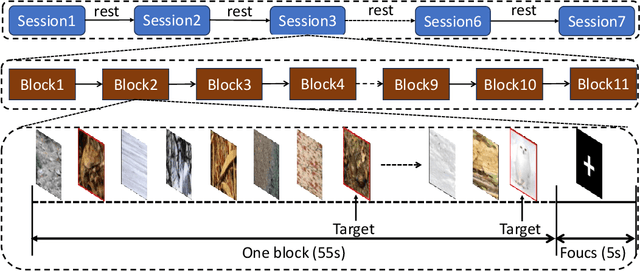
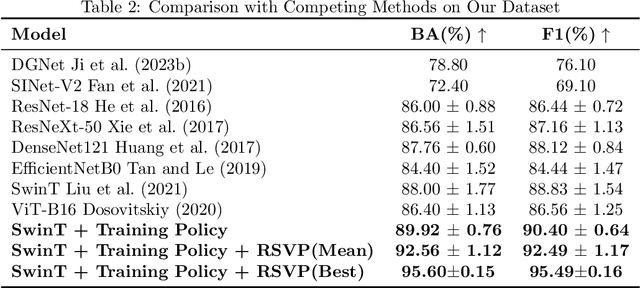
Camouflaged Object Detection (COD), the task of identifying objects concealed within their environments, has seen rapid growth due to its wide range of practical applications. A key step toward developing trustworthy COD systems is the estimation and effective utilization of uncertainty. In this work, we propose a human-machine collaboration framework for classifying the presence of camouflaged objects, leveraging the complementary strengths of computer vision (CV) models and noninvasive brain-computer interfaces (BCIs). Our approach introduces a multiview backbone to estimate uncertainty in CV model predictions, utilizes this uncertainty during training to improve efficiency, and defers low-confidence cases to human evaluation via RSVP-based BCIs during testing for more reliable decision-making. We evaluated the framework in the CAMO dataset, achieving state-of-the-art results with an average improvement of 4.56\% in balanced accuracy (BA) and 3.66\% in the F1 score compared to existing methods. For the best-performing participants, the improvements reached 7.6\% in BA and 6.66\% in the F1 score. Analysis of the training process revealed a strong correlation between our confidence measures and precision, while an ablation study confirmed the effectiveness of the proposed training policy and the human-machine collaboration strategy. In general, this work reduces human cognitive load, improves system reliability, and provides a strong foundation for advancements in real-world COD applications and human-computer interaction. Our code and data are available at: https://github.com/ziyuey/Uncertainty-aware-human-machine-collaboration-in-camouflaged-object-identification.
Deep Learning Assisted Optimization for 3D Reconstruction from Single 2D Line Drawings
Sep 07, 2022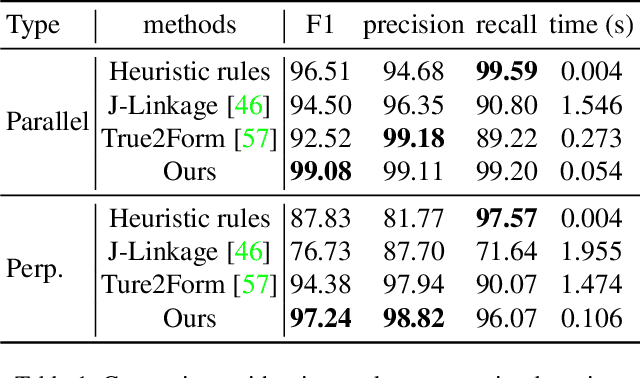
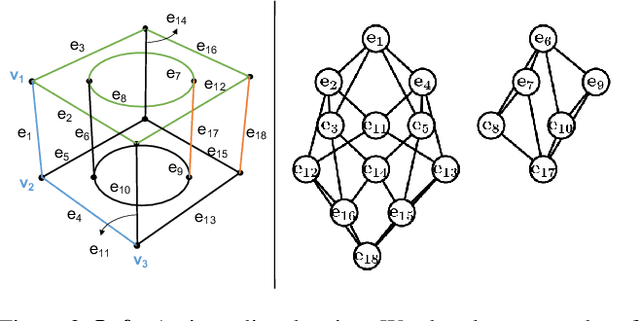
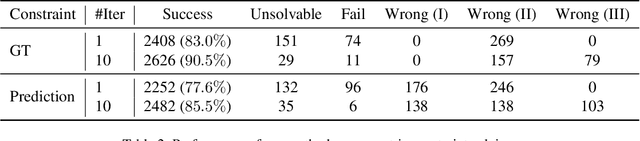
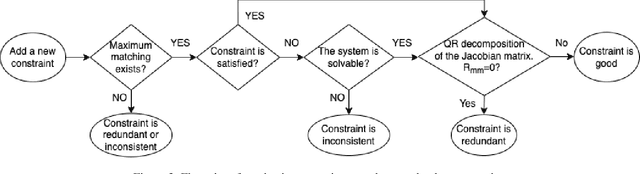
In this paper, we revisit the long-standing problem of automatic reconstruction of 3D objects from single line drawings. Previous optimization-based methods can generate compact and accurate 3D models, but their success rates depend heavily on the ability to (i) identifying a sufficient set of true geometric constraints, and (ii) choosing a good initial value for the numerical optimization. In view of these challenges, we propose to train deep neural networks to detect pairwise relationships among geometric entities (i.e., edges) in the 3D object, and to predict initial depth value of the vertices. Our experiments on a large dataset of CAD models show that, by leveraging deep learning in a geometric constraint solving pipeline, the success rate of optimization-based 3D reconstruction can be significantly improved.
Neural Face Identification in a 2D Wireframe Projection of a Manifold Object
Mar 08, 2022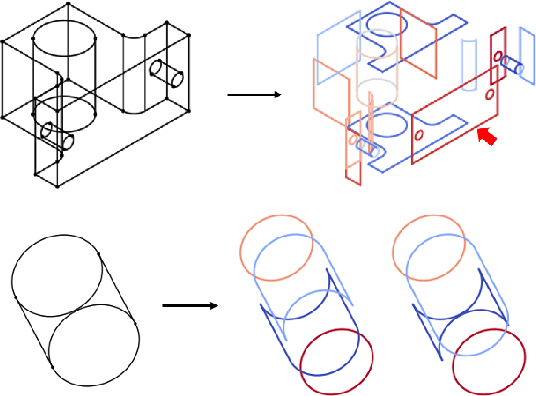


In computer-aided design (CAD) systems, 2D line drawings are commonly used to illustrate 3D object designs. To reconstruct the 3D models depicted by a single 2D line drawing, an important key is finding the edge loops in the line drawing which correspond to the actual faces of the 3D object. In this paper, we approach the classical problem of face identification from a novel data-driven point of view. We cast it as a sequence generation problem: starting from an arbitrary edge, we adopt a variant of the popular Transformer model to predict the edges associated with the same face in a natural order. This allows us to avoid searching the space of all possible edge loops with various hand-crafted rules and heuristics as most existing methods do, deal with challenging cases such as curved surfaces and nested edge loops, and leverage additional cues such as face types. We further discuss how possibly imperfect predictions can be used for 3D object reconstruction.
Misinformation Detection in Social Media Video Posts
Feb 15, 2022
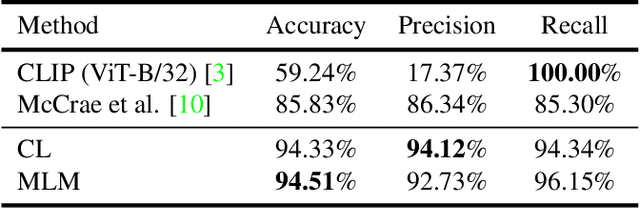
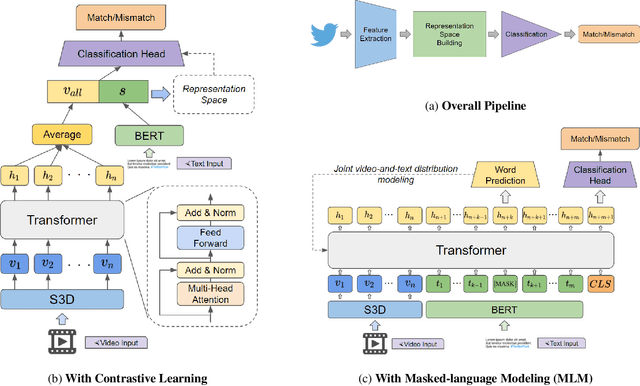
With the growing adoption of short-form video by social media platforms, reducing the spread of misinformation through video posts has become a critical challenge for social media providers. In this paper, we develop methods to detect misinformation in social media posts, exploiting modalities such as video and text. Due to the lack of large-scale public data for misinformation detection in multi-modal datasets, we collect 160,000 video posts from Twitter, and leverage self-supervised learning to learn expressive representations of joint visual and textual data. In this work, we propose two new methods for detecting semantic inconsistencies within short-form social media video posts, based on contrastive learning and masked language modeling. We demonstrate that our new approaches outperform current state-of-the-art methods on both artificial data generated by random-swapping of positive samples and in the wild on a new manually-labeled test set for semantic misinformation.
A Survey of Toxic Comment Classification Methods
Dec 13, 2021


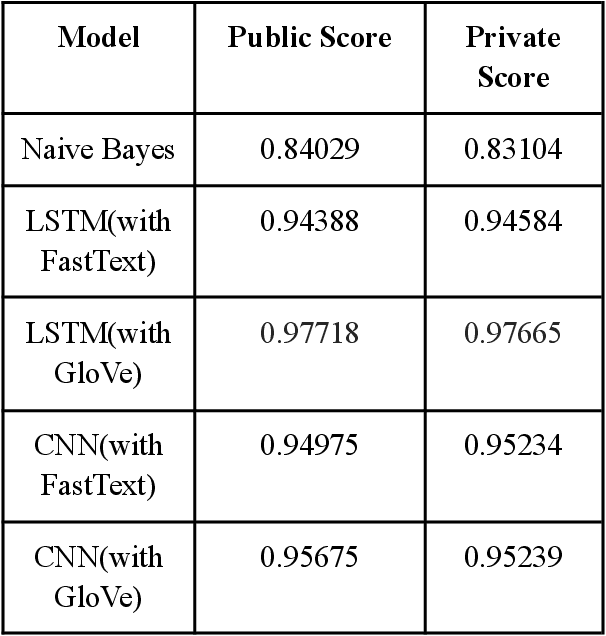
While in real life everyone behaves themselves at least to some extent, it is much more difficult to expect people to behave themselves on the internet, because there are few checks or consequences for posting something toxic to others. Yet, for people on the other side, toxic texts often lead to serious psychological consequences. Detecting such toxic texts is challenging. In this paper, we attempt to build a toxicity detector using machine learning methods including CNN, Naive Bayes model, as well as LSTM. While there has been numerous groundwork laid by others, we aim to build models that provide higher accuracy than the predecessors. We produced very high accuracy models using LSTM and CNN, and compared them to the go-to solutions in language processing, the Naive Bayes model. A word embedding approach is also applied to empower the accuracy of our models.
Multi-Modal Semantic Inconsistency Detection in Social Media News Posts
May 26, 2021
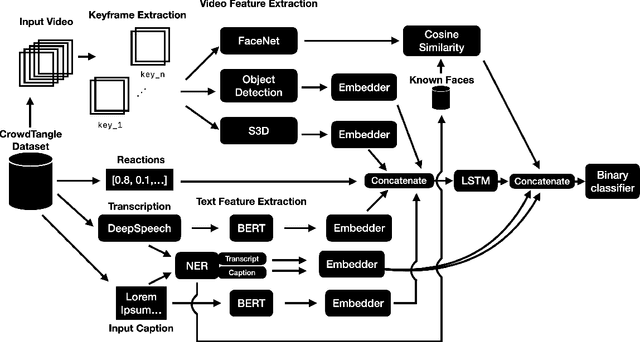
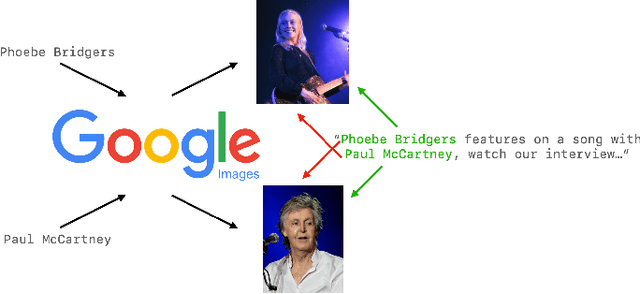

As computer-generated content and deepfakes make steady improvements, semantic approaches to multimedia forensics will become more important. In this paper, we introduce a novel classification architecture for identifying semantic inconsistencies between video appearance and text caption in social media news posts. We develop a multi-modal fusion framework to identify mismatches between videos and captions in social media posts by leveraging an ensemble method based on textual analysis of the caption, automatic audio transcription, semantic video analysis, object detection, named entity consistency, and facial verification. To train and test our approach, we curate a new video-based dataset of 4,000 real-world Facebook news posts for analysis. Our multi-modal approach achieves 60.5% classification accuracy on random mismatches between caption and appearance, compared to accuracy below 50% for uni-modal models. Further ablation studies confirm the necessity of fusion across modalities for correctly identifying semantic inconsistencies.
Fast, Accurate Barcode Detection in Ultra High-Resolution Images
Feb 13, 2021
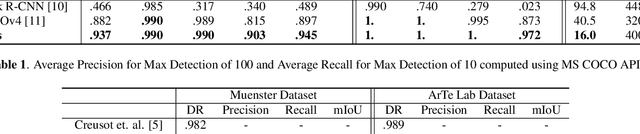

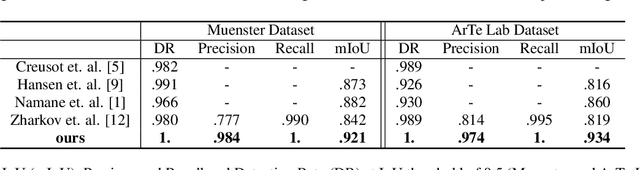
Object detection in Ultra High-Resolution (UHR) images has long been a challenging problem in computer vision due to the varying scales of the targeted objects. When it comes to barcode detection, resizing UHR input images to smaller sizes often leads to the loss of pertinent information, while processing them directly is highly inefficient and computationally expensive. In this paper, we propose using semantic segmentation to achieve a fast and accurate detection of barcodes of various scales in UHR images. Our pipeline involves a modified Region Proposal Network (RPN) on images of size greater than 10k$\times$10k and a newly proposed Y-Net segmentation network, followed by a post-processing workflow for fitting a bounding box around each segmented barcode mask. The end-to-end system has a latency of 16 milliseconds, which is $2.5\times$ faster than YOLOv4 and $5.9\times$ faster than Mask RCNN. In terms of accuracy, our method outperforms YOLOv4 and Mask R-CNN by a $mAP$ of 5.5% and 47.1% respectively, on a synthetic dataset. We have made available the generated synthetic barcode dataset and its code at http://www.github.com/viplab/BSBD/.