 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAG-VLAQ: Multi-modal Aerial-Ground Query Aggregation for Cross-View Place Recognition
May 10, 2026Multi-modal cross-view place recognition remains a fundamental challenge in computer vision and robotics due to the severe viewpoint, modality, and spatial-structure discrepancies between ground observations and aerial references. To address this challenge, we present MAG-VLAQ, a foundation-model-enhanced query aggregation framework for multi-modal aerial-ground cross-view place recognition. Specifically, our approach leverages pre-trained foundation models to extract dense visual tokens from both ground and aerial images, as well as expressive geometric tokens from ground LiDAR observations. These heterogeneous tokens are then projected into a shared embedding space for cross-modal alignment and fusion. As our main contribution, we propose ODE-conditioned VLAQ, which tightly couples neural ordinary differential equations (ODE)-based RGB-LiDAR fusion with vectors of locally aggregated queries (VLAQ). In this design, the VLAQ query centers are dynamically adapted according to the fused multi-modal state. This mechanism allows the final global descriptor to preserve globally learned retrieval prototypes while remaining responsive to scene-specific visual and geometric evidence, significantly improving aerial-ground matching. Extensive experiments on KITTI360-AG and nuScenes-AG validate the effectiveness of our proposed MAG-VLAQ. Notably, on KITTI360-AG, our MAG-VLAQ nearly doubles the state-of-the-art performance, achieving 61.1 Recall@1 in the satellite setting, compared with 34.5 from the closest competing approach.
VFM-Recon: Unlocking Cross-Domain Scene-Level Neural Reconstruction with Scale-Aligned Foundation Priors
Mar 13, 2026Scene-level neural volumetric reconstruction from monocular videos remains challenging, especially under severe domain shifts. Although recent advances in vision foundation models (VFMs) provide transferable generalized priors learned from large-scale data, their scaleambiguous predictions are incompatible with the scale consistency required by volumetric fusion. To address this gap, we present VFMRecon, the first attempt to bridge transferable VFM priors with scaleconsistent requirements in scene-level neural reconstruction. Specifically, we first introduce a lightweight scale alignment stage that restores multiview scale coherence. We then integrate pretrained VFM features into the neural volumetric reconstruction pipeline via lightweight task-specific adapters, which are trained for reconstruction while preserving the crossdomain robustness of pretrained representations. We train our model on ScanNet train split and evaluate on both in-distribution ScanNet test split and out-of-distribution TUM RGB-D and Tanks and Temples datasets. The results demonstrate that our model achieves state-of-theart performance across all datasets domains. In particular, on the challenging outdoor Tanks and Temples dataset, our model achieves an F1 score of 70.1 in reconstructed mesh evaluation, substantially outperforming the closest competitor, VGGT, which only attains 51.8.
Thermal odometry and dense mapping using learned ddometry and Gaussian splatting
Feb 07, 2026Thermal infrared sensors, with wavelengths longer than smoke particles, can capture imagery independent of darkness, dust, and smoke. This robustness has made them increasingly valuable for motion estimation and environmental perception in robotics, particularly in adverse conditions. Existing thermal odometry and mapping approaches, however, are predominantly geometric and often fail across diverse datasets while lacking the ability to produce dense maps. Motivated by the efficiency and high-quality reconstruction ability of recent Gaussian Splatting (GS) techniques, we propose TOM-GS, a thermal odometry and mapping method that integrates learning-based odometry with GS-based dense mapping. TOM-GS is among the first GS-based SLAM systems tailored for thermal cameras, featuring dedicated thermal image enhancement and monocular depth integration. Extensive experiments on motion estimation and novel-view rendering demonstrate that TOM-GS outperforms existing learning-based methods, confirming the benefits of learning-based pipelines for robust thermal odometry and dense reconstruction.
Keyframe-Based Feed-Forward Visual Odometry
Jan 22, 2026The emergence of visual foundation models has revolutionized visual odometry~(VO) and SLAM, enabling pose estimation and dense reconstruction within a single feed-forward network. However, unlike traditional pipelines that leverage keyframe methods to enhance efficiency and accuracy, current foundation model based methods, such as VGGT-Long, typically process raw image sequences indiscriminately. This leads to computational redundancy and degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information. Integrating traditional geometric heuristics into these methods is non-trivial, as their performance depends on high-dimensional latent representations rather than explicit geometric metrics. To bridge this gap, we propose a novel keyframe-based feed-forward VO. Instead of relying on hand-crafted rules, our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner, aligning selection with the intrinsic characteristics of the underlying foundation model. We train our agent on TartanAir dataset and conduct extensive evaluations across several real-world datasets. Experimental results demonstrate that the proposed method achieves consistent and substantial improvements over state-of-the-art feed-forward VO methods.
DC-VLAQ: Query-Residual Aggregation for Robust Visual Place Recognition
Jan 19, 2026One of the central challenges in visual place recognition (VPR) is learning a robust global representation that remains discriminative under large viewpoint changes, illumination variations, and severe domain shifts. While visual foundation models (VFMs) provide strong local features, most existing methods rely on a single model, overlooking the complementary cues offered by different VFMs. However, exploiting such complementary information inevitably alters token distributions, which challenges the stability of existing query-based global aggregation schemes. To address these challenges, we propose DC-VLAQ, a representation-centric framework that integrates the fusion of complementary VFMs and robust global aggregation. Specifically, we first introduce a lightweight residual-guided complementary fusion that anchors representations in the DINOv2 feature space while injecting complementary semantics from CLIP through a learned residual correction. In addition, we propose the Vector of Local Aggregated Queries (VLAQ), a query--residual global aggregation scheme that encodes local tokens by their residual responses to learnable queries, resulting in improved stability and the preservation of fine-grained discriminative cues. Extensive experiments on standard VPR benchmarks, including Pitts30k, Tokyo24/7, MSLS, Nordland, SPED, and AmsterTime, demonstrate that DC-VLAQ consistently outperforms strong baselines and achieves state-of-the-art performance, particularly under challenging domain shifts and long-term appearance changes.
3D Scene-Camera Representation with Joint Camera Photometric Optimization
Jun 26, 2025Representing scenes from multi-view images is a crucial task in computer vision with extensive applications. However, inherent photometric distortions in the camera imaging can significantly degrade image quality. Without accounting for these distortions, the 3D scene representation may inadvertently incorporate erroneous information unrelated to the scene, diminishing the quality of the representation. In this paper, we propose a novel 3D scene-camera representation with joint camera photometric optimization. By introducing internal and external photometric model, we propose a full photometric model and corresponding camera representation. Based on simultaneously optimizing the parameters of the camera representation, the proposed method effectively separates scene-unrelated information from the 3D scene representation. Additionally, during the optimization of the photometric parameters, we introduce a depth regularization to prevent the 3D scene representation from fitting scene-unrelated information. By incorporating the camera model as part of the mapping process, the proposed method constructs a complete map that includes both the scene radiance field and the camera photometric model. Experimental results demonstrate that the proposed method can achieve high-quality 3D scene representations, even under conditions of imaging degradation, such as vignetting and dirt.
Uncertainty Aware Human-machine Collaboration in Camouflaged Object Detection
Feb 12, 2025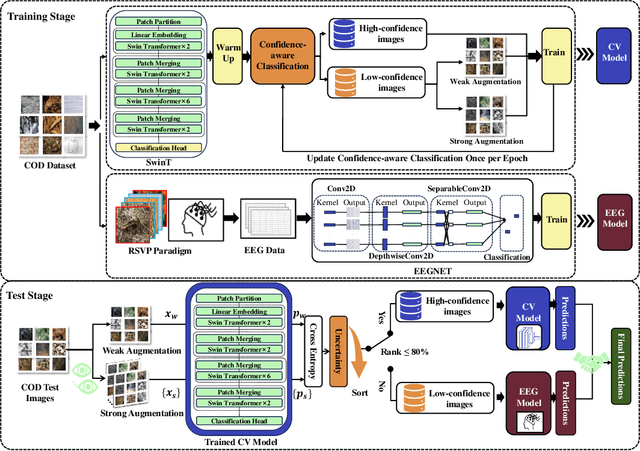
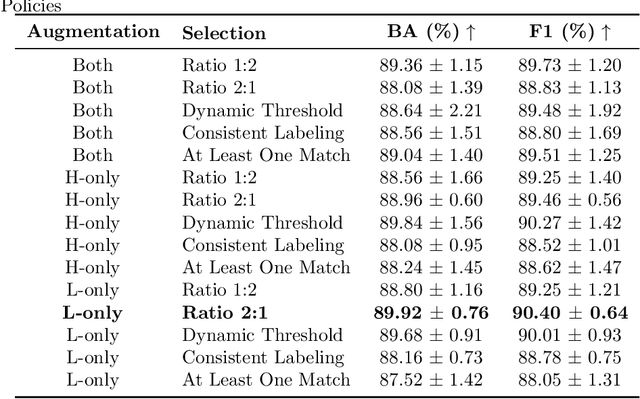
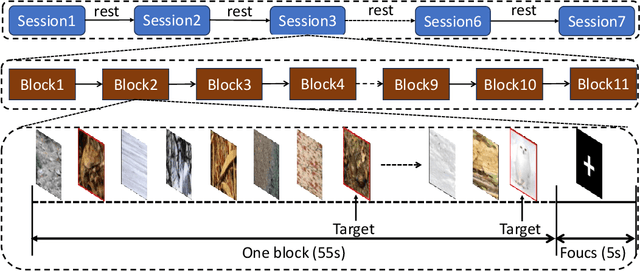
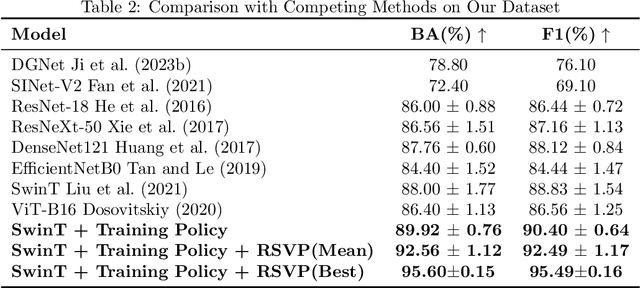
Camouflaged Object Detection (COD), the task of identifying objects concealed within their environments, has seen rapid growth due to its wide range of practical applications. A key step toward developing trustworthy COD systems is the estimation and effective utilization of uncertainty. In this work, we propose a human-machine collaboration framework for classifying the presence of camouflaged objects, leveraging the complementary strengths of computer vision (CV) models and noninvasive brain-computer interfaces (BCIs). Our approach introduces a multiview backbone to estimate uncertainty in CV model predictions, utilizes this uncertainty during training to improve efficiency, and defers low-confidence cases to human evaluation via RSVP-based BCIs during testing for more reliable decision-making. We evaluated the framework in the CAMO dataset, achieving state-of-the-art results with an average improvement of 4.56\% in balanced accuracy (BA) and 3.66\% in the F1 score compared to existing methods. For the best-performing participants, the improvements reached 7.6\% in BA and 6.66\% in the F1 score. Analysis of the training process revealed a strong correlation between our confidence measures and precision, while an ablation study confirmed the effectiveness of the proposed training policy and the human-machine collaboration strategy. In general, this work reduces human cognitive load, improves system reliability, and provides a strong foundation for advancements in real-world COD applications and human-computer interaction. Our code and data are available at: https://github.com/ziyuey/Uncertainty-aware-human-machine-collaboration-in-camouflaged-object-identification.
SLC$^2$-SLAM: Semantic-guided Loop Closure with Shared Latent Code for NeRF SLAM
Jan 15, 2025



Targeting the notorious cumulative drift errors in NeRF SLAM, we propose a Semantic-guided Loop Closure with Shared Latent Code, dubbed SLC$^2$-SLAM. Especially, we argue that latent codes stored in many NeRF SLAM systems are not fully exploited, as they are only used for better reconstruction. In this paper, we propose a simple yet effective way to detect potential loops using the same latent codes as local features. To further improve the loop detection performance, we use the semantic information, which are also decoded from the same latent codes to guide the aggregation of local features. Finally, with the potential loops detected, we close them with a graph optimization followed by bundle adjustment to refine both the estimated poses and the reconstructed scene. To evaluate the performance of our SLC$^2$-SLAM, we conduct extensive experiments on Replica and ScanNet datasets. Our proposed semantic-guided loop closure significantly outperforms the pre-trained NetVLAD and ORB combined with Bag-of-Words, which are used in all the other NeRF SLAM with loop closure. As a result, our SLC$^2$-SLAM also demonstrated better tracking and reconstruction performance, especially in larger scenes with more loops, like ScanNet.
VIPeR: Visual Incremental Place Recognition with Adaptive Mining and Lifelong Learning
Jul 31, 2024Visual place recognition (VPR) is an essential component of many autonomous and augmented/virtual reality systems. It enables the systems to robustly localize themselves in large-scale environments. Existing VPR methods demonstrate attractive performance at the cost of heavy pre-training and limited generalizability. When deployed in unseen environments, these methods exhibit significant performance drops. Targeting this issue, we present VIPeR, a novel approach for visual incremental place recognition with the ability to adapt to new environments while retaining the performance of previous environments. We first introduce an adaptive mining strategy that balances the performance within a single environment and the generalizability across multiple environments. Then, to prevent catastrophic forgetting in lifelong learning, we draw inspiration from human memory systems and design a novel memory bank for our VIPeR. Our memory bank contains a sensory memory, a working memory and a long-term memory, with the first two focusing on the current environment and the last one for all previously visited environments. Additionally, we propose a probabilistic knowledge distillation to explicitly safeguard the previously learned knowledge. We evaluate our proposed VIPeR on three large-scale datasets, namely Oxford Robotcar, Nordland, and TartanAir. For comparison, we first set a baseline performance with naive finetuning. Then, several more recent lifelong learning methods are compared. Our VIPeR achieves better performance in almost all aspects with the biggest improvement of 13.65% in average performance.
Benchmarking Neural Radiance Fields for Autonomous Robots: An Overview
May 09, 2024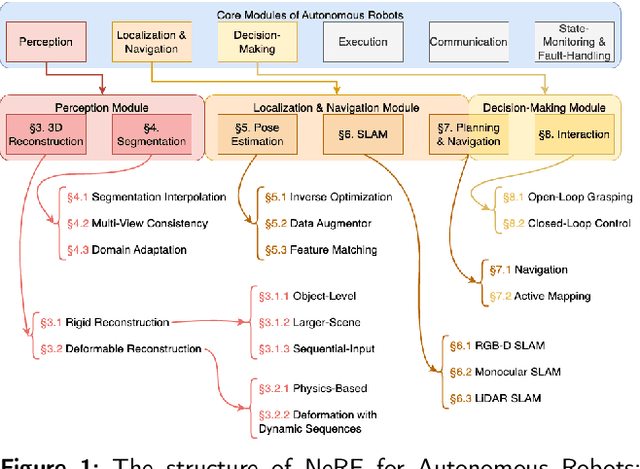
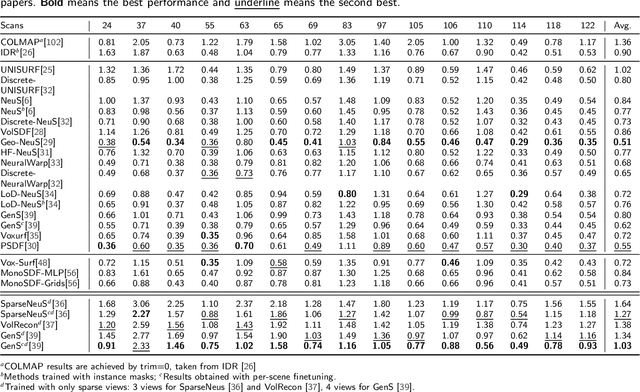
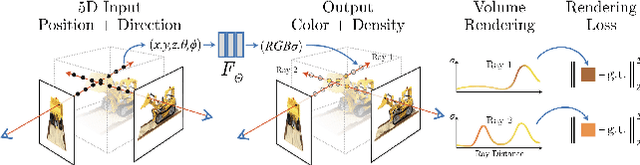
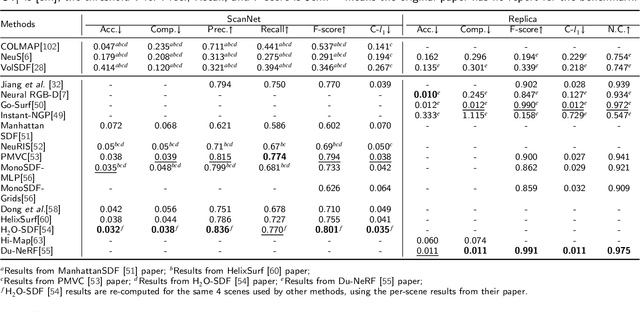
Neural Radiance Fields (NeRF) have emerged as a powerful paradigm for 3D scene representation, offering high-fidelity renderings and reconstructions from a set of sparse and unstructured sensor data. In the context of autonomous robotics, where perception and understanding of the environment are pivotal, NeRF holds immense promise for improving performance. In this paper, we present a comprehensive survey and analysis of the state-of-the-art techniques for utilizing NeRF to enhance the capabilities of autonomous robots. We especially focus on the perception, localization and navigation, and decision-making modules of autonomous robots and delve into tasks crucial for autonomous operation, including 3D reconstruction, segmentation, pose estimation, simultaneous localization and mapping (SLAM), navigation and planning, and interaction. Our survey meticulously benchmarks existing NeRF-based methods, providing insights into their strengths and limitations. Moreover, we explore promising avenues for future research and development in this domain. Notably, we discuss the integration of advanced techniques such as 3D Gaussian splatting (3DGS), large language models (LLM), and generative AIs, envisioning enhanced reconstruction efficiency, scene understanding, decision-making capabilities. This survey serves as a roadmap for researchers seeking to leverage NeRFs to empower autonomous robots, paving the way for innovative solutions that can navigate and interact seamlessly in complex environments.