 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout-Training Co-Design for Efficient LLM-Based Multi-Agent Reinforcement Learning
Feb 10, 2026Despite algorithm-level innovations for multi-agent reinforcement learning (MARL), the underlying networked infrastructure for large-scale MARL training remains underexplored. Existing training frameworks primarily optimize for single-agent scenarios and fail to address the unique system-level challenges of MARL, including rollout-training synchronization barriers, rollout load imbalance, and training resource underutilization. To bridge this gap, we propose FlexMARL, the first end-to-end training framework that holistically optimizes rollout, training, and their orchestration for large-scale LLM-based MARL. Specifically, FlexMARL introduces the joint orchestrator to manage data flow under the rollout-training disaggregated architecture. Building upon the experience store, a novel micro-batch driven asynchronous pipeline eliminates the synchronization barriers while providing strong consistency guarantees. Rollout engine adopts a parallel sampling scheme combined with hierarchical load balancing, which adapts to skewed inter/intra-agent request patterns. Training engine achieves on-demand hardware binding through agent-centric resource allocation. The training states of different agents are swapped via unified and location-agnostic communication. Empirical results on a large-scale production cluster demonstrate that FlexMARL achieves up to 7.3x speedup and improves hardware utilization by up to 5.6x compared to existing frameworks.
Uncertainty Aware Human-machine Collaboration in Camouflaged Object Detection
Feb 12, 2025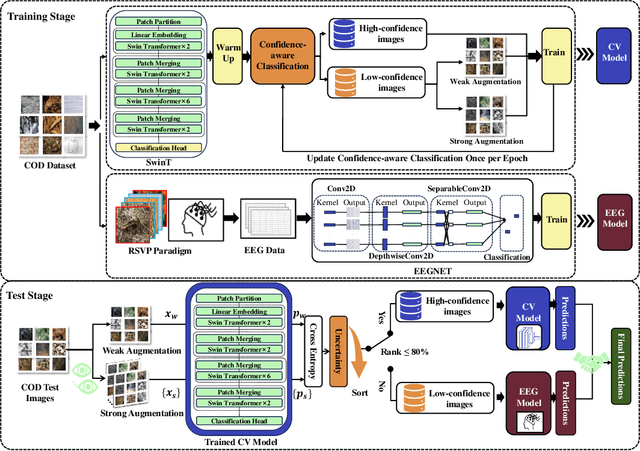
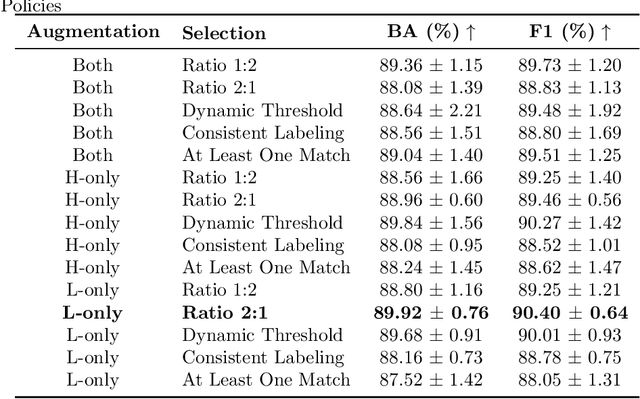
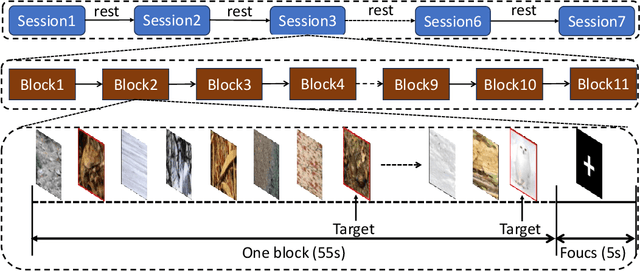
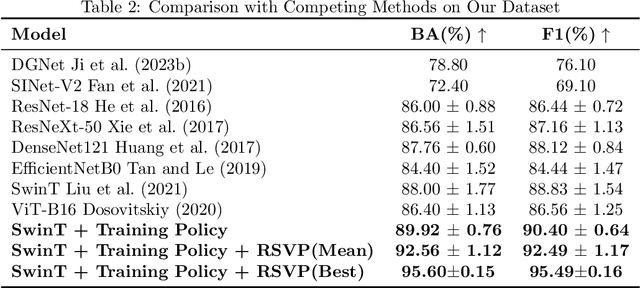
Camouflaged Object Detection (COD), the task of identifying objects concealed within their environments, has seen rapid growth due to its wide range of practical applications. A key step toward developing trustworthy COD systems is the estimation and effective utilization of uncertainty. In this work, we propose a human-machine collaboration framework for classifying the presence of camouflaged objects, leveraging the complementary strengths of computer vision (CV) models and noninvasive brain-computer interfaces (BCIs). Our approach introduces a multiview backbone to estimate uncertainty in CV model predictions, utilizes this uncertainty during training to improve efficiency, and defers low-confidence cases to human evaluation via RSVP-based BCIs during testing for more reliable decision-making. We evaluated the framework in the CAMO dataset, achieving state-of-the-art results with an average improvement of 4.56\% in balanced accuracy (BA) and 3.66\% in the F1 score compared to existing methods. For the best-performing participants, the improvements reached 7.6\% in BA and 6.66\% in the F1 score. Analysis of the training process revealed a strong correlation between our confidence measures and precision, while an ablation study confirmed the effectiveness of the proposed training policy and the human-machine collaboration strategy. In general, this work reduces human cognitive load, improves system reliability, and provides a strong foundation for advancements in real-world COD applications and human-computer interaction. Our code and data are available at: https://github.com/ziyuey/Uncertainty-aware-human-machine-collaboration-in-camouflaged-object-identification.
A dual-branch model with inter- and intra-branch contrastive loss for long-tailed recognition
Sep 28, 2023Real-world data often exhibits a long-tailed distribution, in which head classes occupy most of the data, while tail classes only have very few samples. Models trained on long-tailed datasets have poor adaptability to tail classes and the decision boundaries are ambiguous. Therefore, in this paper, we propose a simple yet effective model, named Dual-Branch Long-Tailed Recognition (DB-LTR), which includes an imbalanced learning branch and a Contrastive Learning Branch (CoLB). The imbalanced learning branch, which consists of a shared backbone and a linear classifier, leverages common imbalanced learning approaches to tackle the data imbalance issue. In CoLB, we learn a prototype for each tail class, and calculate an inter-branch contrastive loss, an intra-branch contrastive loss and a metric loss. CoLB can improve the capability of the model in adapting to tail classes and assist the imbalanced learning branch to learn a well-represented feature space and discriminative decision boundary. Extensive experiments on three long-tailed benchmark datasets, i.e., CIFAR100-LT, ImageNet-LT and Places-LT, show that our DB-LTR is competitive and superior to the comparative methods.
* Published at Neural Networks
MIANet: Aggregating Unbiased Instance and General Information for Few-Shot Semantic Segmentation
May 23, 2023


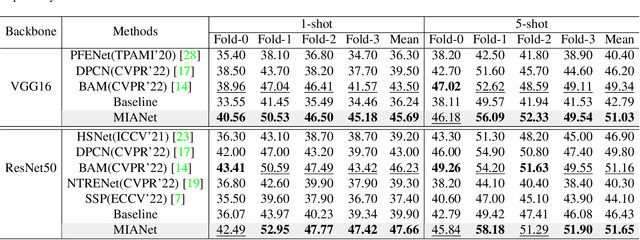
Existing few-shot segmentation methods are based on the meta-learning strategy and extract instance knowledge from a support set and then apply the knowledge to segment target objects in a query set. However, the extracted knowledge is insufficient to cope with the variable intra-class differences since the knowledge is obtained from a few samples in the support set. To address the problem, we propose a multi-information aggregation network (MIANet) that effectively leverages the general knowledge, i.e., semantic word embeddings, and instance information for accurate segmentation. Specifically, in MIANet, a general information module (GIM) is proposed to extract a general class prototype from word embeddings as a supplement to instance information. To this end, we design a triplet loss that treats the general class prototype as an anchor and samples positive-negative pairs from local features in the support set. The calculated triplet loss can transfer semantic similarities among language identities from a word embedding space to a visual representation space. To alleviate the model biasing towards the seen training classes and to obtain multi-scale information, we then introduce a non-parametric hierarchical prior module (HPM) to generate unbiased instance-level information via calculating the pixel-level similarity between the support and query image features. Finally, an information fusion module (IFM) combines the general and instance information to make predictions for the query image. Extensive experiments on PASCAL-5i and COCO-20i show that MIANet yields superior performance and set a new state-of-the-art. Code is available at https://github.com/Aldrich2y/MIANet.
On-edge Multi-task Transfer Learning: Model and Practice with Data-driven Task Allocation
Jul 06, 2021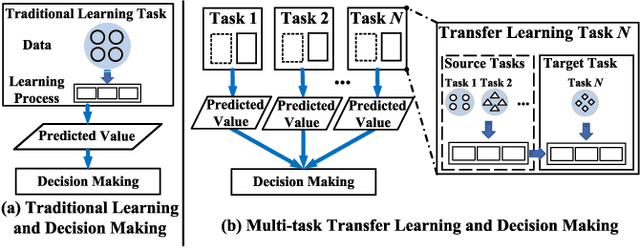

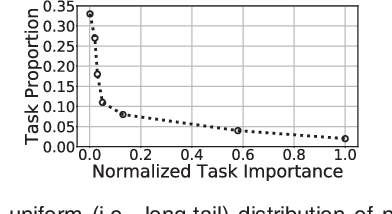
On edge devices, data scarcity occurs as a common problem where transfer learning serves as a widely-suggested remedy. Nevertheless, transfer learning imposes a heavy computation burden to resource-constrained edge devices. Existing task allocation works usually assume all submitted tasks are equally important, leading to inefficient resource allocation at a task level when directly applied in Multi-task Transfer Learning (MTL). To address these issues, we first reveal that it is crucial to measure the impact of tasks on overall decision performance improvement and quantify \emph{task importance}. We then show that task allocation with task importance for MTL (TATIM) is a variant of the NP-complete Knapsack problem, where the complicated computation to solve this problem needs to be conducted repeatedly under varying contexts. To solve TATIM with high computational efficiency, we propose a Data-driven Cooperative Task Allocation (DCTA) approach. Finally, we evaluate the performance of DCTA by not only a trace-driven simulation, but also a new comprehensive real-world AIOps case study that bridges model and practice via a new architecture and main components design within the AIOps system. Extensive experiments show that our DCTA reduces 3.24 times of processing time, and saves 48.4\% energy consumption compared with the state-of-the-art when solving TATIM.
* 15 pages, published in IEEE TRANSACTIONS ON Parallel and Distributed Systems, VOL. 31, NO. 6, JUNE 2020
MoTiAC: Multi-Objective Actor-Critics for Real-Time Bidding
Feb 18, 2020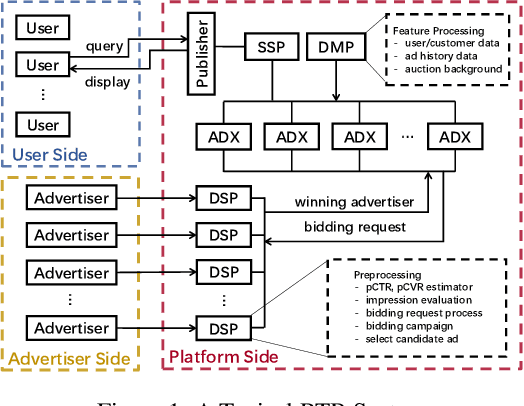
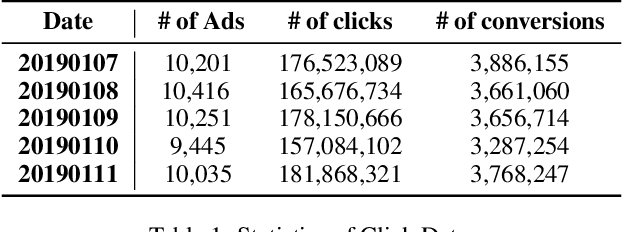
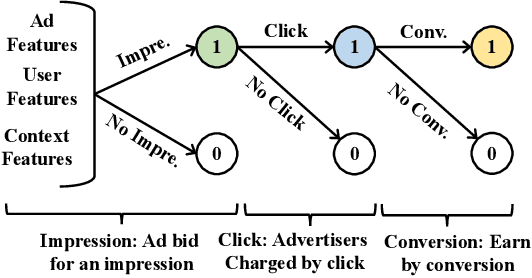
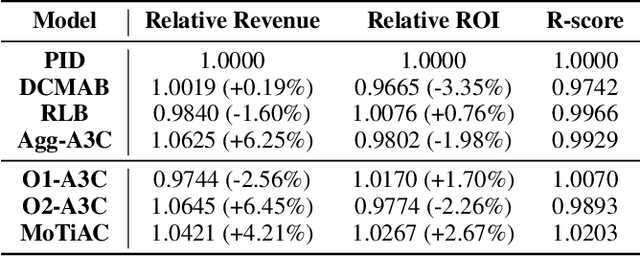
Online real-time bidding (RTB) is known as a complex auction game where ad platforms seek to consider various influential key performance indicators (KPIs), like revenue and return on investment (ROI). The trade-off among these competing goals needs to be balanced on a massive scale. To address the problem, we propose a multi-objective reinforcement learning algorithm, named MoTiAC, for the problem of bidding optimization with various goals. Specifically, in MoTiAC, instead of using a fixed and linear combination of multiple objectives, we compute adaptive weights overtime on the basis of how well the current state agrees with the agent's prior. In addition, we provide interesting properties of model updating and further prove that Pareto optimality could be guaranteed. We demonstrate the effectiveness of our method on a real-world commercial dataset. Experiments show that the model outperforms all state-of-the-art baselines.
Deep Reinforcement Learning for Imbalanced Classification
Jan 05, 2019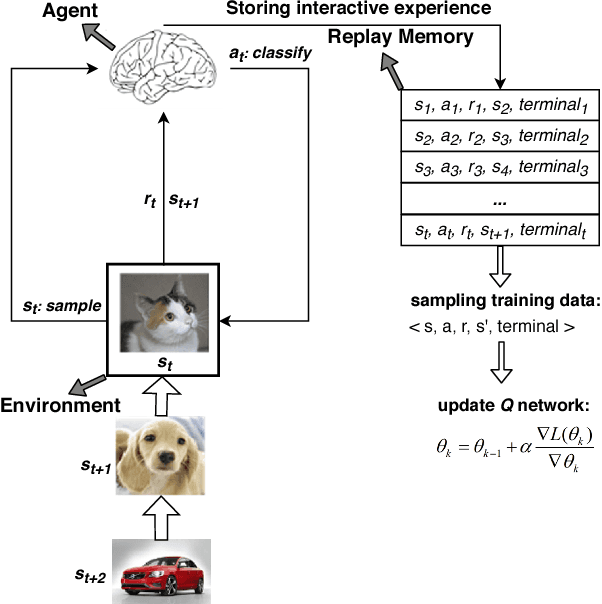

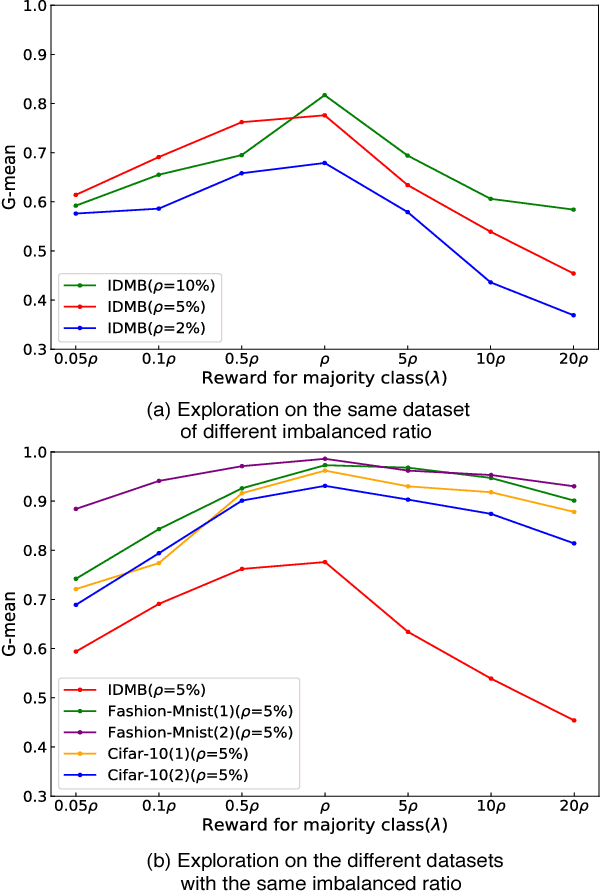
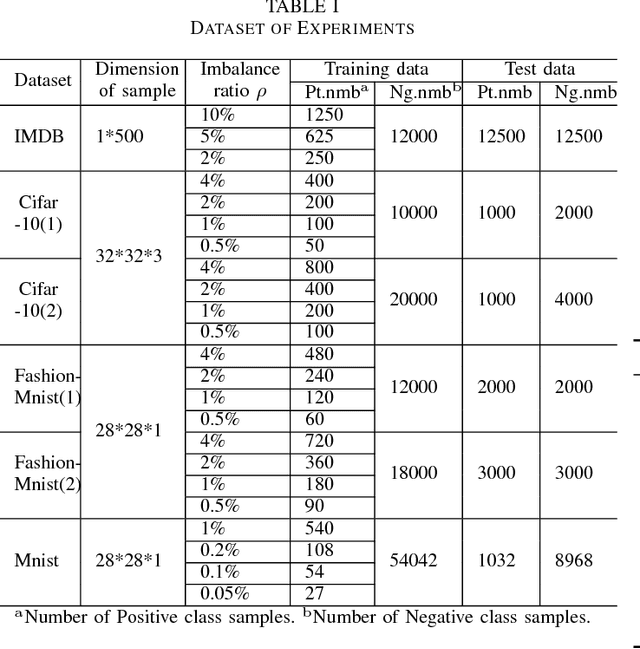
Data in real-world application often exhibit skewed class distribution which poses an intense challenge for machine learning. Conventional classification algorithms are not effective in the case of imbalanced data distribution, and may fail when the data distribution is highly imbalanced. To address this issue, we propose a general imbalanced classification model based on deep reinforcement learning. We formulate the classification problem as a sequential decision-making process and solve it by deep Q-learning network. The agent performs a classification action on one sample at each time step, and the environment evaluates the classification action and returns a reward to the agent. The reward from minority class sample is larger so the agent is more sensitive to the minority class. The agent finally finds an optimal classification policy in imbalanced data under the guidance of specific reward function and beneficial learning environment. Experiments show that our proposed model outperforms the other imbalanced classification algorithms, and it can identify more minority samples and has great classification performance.