 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attention Drifts,but Anchors Hold:Mitigating Hallucination in Multimodal Large Language Models via Cross-Layer Visual Anchors
Mar 26, 2026Multimodal Large Language Models often suffer from object hallucination. While existing research utilizes attention enhancement and visual retracing, we find these works lack sufficient interpretability regarding attention drift in final model stages. In this paper, we investigate the layer wise evolution of visual features and discover that hallucination stems from deep layer attention regressing toward initial visual noise from early layers. We observe that output reliability depends on acquiring visual anchors at intermediate layers rather than final layers. Based on these insights, we propose CLVA, which stands for Cross-Layer Visual Anchors, a training free method that reinforces critical mid layer features while suppressing regressive noise. This approach effectively pulls deep layer attention back to correct visual regions by utilizing essential anchors captured from attention dynamics. We evaluate our method across diverse architectures and benchmarks, demonstrating outstanding performance without significant increase in computational time and GPU memory.
SAGE: Accelerating Vision-Language Models via Entropy-Guided Adaptive Speculative Decoding
Jan 31, 2026Speculative decoding has emerged as a promising approach to accelerate inference in vision-language models (VLMs) by enabling parallel verification of multiple draft tokens. However, existing methods rely on static tree structures that remain fixed throughout the decoding process, failing to adapt to the varying prediction difficulty across generation steps. This leads to suboptimal acceptance lengths and limited speedup. In this paper, we propose SAGE, a novel framework that dynamically adjusts the speculation tree structure based on real-time prediction uncertainty. Our key insight is that output entropy serves as a natural confidence indicator with strong temporal correlation across decoding steps. SAGE constructs deeper-narrower trees for high-confidence predictions to maximize speculation depth, and shallower-wider trees for uncertain predictions to diversify exploration. SAGE improves acceptance lengths and achieves faster acceleration compared to static tree baselines. Experiments on multiple benchmarks demonstrate the effectiveness of SAGE: without any loss in output quality, it delivers up to $3.36\times$ decoding speedup for LLaVA-OneVision-72B and $3.18\times$ for Qwen2.5-VL-72B.
Sparsity-Aware Unlearning for Large Language Models
Jan 31, 2026Large Language Models (LLMs) inevitably memorize sensitive information during training, posing significant privacy risks. Machine unlearning has emerged as a promising solution to selectively remove such information without full retraining. However, existing methods are designed for dense models and overlook model sparsification-an essential technique for efficient LLM deployment. We find that unlearning effectiveness degrades substantially on sparse models. Through empirical analysis, we reveal that this degradation occurs because existing unlearning methods require updating all parameters, yet sparsification prunes substantial weights to zero, fundamentally limiting the model's forgetting capacity. To address this challenge, we propose Sparsity-Aware Unlearning (SAU), which decouples unlearning from sparsification objectives through gradient masking that redirects updates to surviving weights, combined with importance-aware redistribution to compensate for pruned parameters. Extensive experiments demonstrate that SAU significantly outperforms existing methods on sparse LLMs, achieving effective forgetting while preserving model utility.
Heaven-Sent or Hell-Bent? Benchmarking the Intelligence and Defectiveness of LLM Hallucinations
Dec 25, 2025

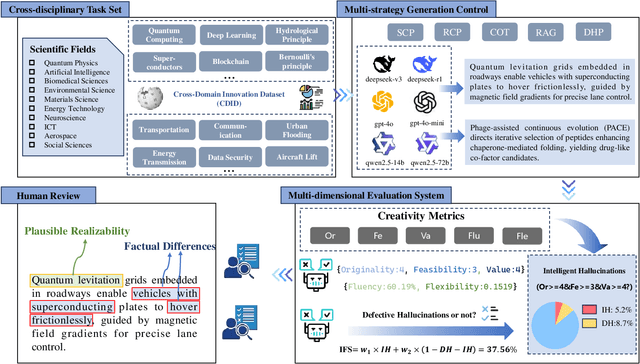

Hallucinations in large language models (LLMs) are commonly regarded as errors to be minimized. However, recent perspectives suggest that some hallucinations may encode creative or epistemically valuable content, a dimension that remains underquantified in current literature. Existing hallucination detection methods primarily focus on factual consistency, struggling to handle heterogeneous scientific tasks and balance creativity with accuracy. To address these challenges, we propose HIC-Bench, a novel evaluation framework that categorizes hallucinations into Intelligent Hallucinations (IH) and Defective Hallucinations (DH), enabling systematic investigation of their interplay in LLM creativity. HIC-Bench features three core characteristics: (1) Structured IH/DH Assessment. using a multi-dimensional metric matrix integrating Torrance Tests of Creative Thinking (TTCT) metrics (Originality, Feasibility, Value) with hallucination-specific dimensions (scientific plausibility, factual deviation); (2) Cross-Domain Applicability. spanning ten scientific domains with open-ended innovation tasks; and (3) Dynamic Prompt Optimization. leveraging the Dynamic Hallucination Prompt (DHP) to guide models toward creative and reliable outputs. The evaluation process employs multiple LLM judges, averaging scores to mitigate bias, with human annotators verifying IH/DH classifications. Experimental results reveal a nonlinear relationship between IH and DH, demonstrating that creativity and correctness can be jointly optimized. These insights position IH as a catalyst for creativity and reveal the ability of LLM hallucinations to drive scientific innovation.Additionally, the HIC-Bench offers a valuable platform for advancing research into the creative intelligence of LLM hallucinations.
REMISVFU: Vertical Federated Unlearning via Representation Misdirection for Intermediate Output Feature
Dec 11, 2025
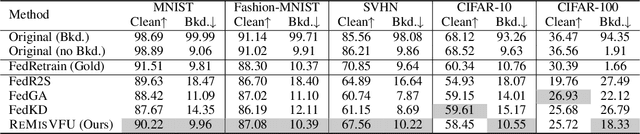


Data-protection regulations such as the GDPR grant every participant in a federated system a right to be forgotten. Federated unlearning has therefore emerged as a research frontier, aiming to remove a specific party's contribution from the learned model while preserving the utility of the remaining parties. However, most unlearning techniques focus on Horizontal Federated Learning (HFL), where data are partitioned by samples. In contrast, Vertical Federated Learning (VFL) allows organizations that possess complementary feature spaces to train a joint model without sharing raw data. The resulting feature-partitioned architecture renders HFL-oriented unlearning methods ineffective. In this paper, we propose REMISVFU, a plug-and-play representation misdirection framework that enables fast, client-level unlearning in splitVFL systems. When a deletion request arrives, the forgetting party collapses its encoder output to a randomly sampled anchor on the unit sphere, severing the statistical link between its features and the global model. To maintain utility for the remaining parties, the server jointly optimizes a retention loss and a forgetting loss, aligning their gradients via orthogonal projection to eliminate destructive interference. Evaluations on public benchmarks show that REMISVFU suppresses back-door attack success to the natural class-prior level and sacrifices only about 2.5% points of clean accuracy, outperforming state-of-the-art baselines.
Exploiting Text Semantics for Few and Zero Shot Node Classification on Text-attributed Graph
May 13, 2025



Text-attributed graph (TAG) provides a text description for each graph node, and few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. Existing work utilizes various graph-based augmentation techniques to train the node and text embeddings, while text-based augmentations are largely unexplored. In this paper, we propose Text Semantics Augmentation (TSA) to improve accuracy by introducing more text semantic supervision signals. Specifically, we design two augmentation techniques, i.e., positive semantics matching and negative semantics contrast, to provide more reference texts for each graph node or text description. Positive semantic matching retrieves texts with similar embeddings to match with a graph node. Negative semantic contrast adds a negative prompt to construct a text description with the opposite semantics, which is contrasted with the original node and text. We evaluate TSA on 5 datasets and compare with 13 state-of-the-art baselines. The results show that TSA consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
Robust Machine Unlearning for Quantized Neural Networks via Adaptive Gradient Reweighting with Similar Labels
Mar 18, 2025Model quantization enables efficient deployment of deep neural networks on edge devices through low-bit parameter representation, yet raises critical challenges for implementing machine unlearning (MU) under data privacy regulations. Existing MU methods designed for full-precision models fail to address two fundamental limitations in quantized networks: 1) Noise amplification from label mismatch during data processing, and 2) Gradient imbalance between forgotten and retained data during training. These issues are exacerbated by quantized models' constrained parameter space and discrete optimization. We propose Q-MUL, the first dedicated unlearning framework for quantized models. Our method introduces two key innovations: 1) Similar Labels assignment replaces random labels with semantically consistent alternatives to minimize noise injection, and 2) Adaptive Gradient Reweighting dynamically aligns parameter update contributions from forgotten and retained data. Through systematic analysis of quantized model vulnerabilities, we establish theoretical foundations for these mechanisms. Extensive evaluations on benchmark datasets demonstrate Q-MUL's superiority over existing approaches.
Hound: Hunting Supervision Signals for Few and Zero Shot Node Classification on Text-attributed Graph
Sep 01, 2024



Text-attributed graph (TAG) is an important type of graph structured data with text descriptions for each node. Few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. However, the two tasks are challenging due to the lack of supervision signals, and existing methods only use the contrastive loss to align graph-based node embedding and language-based text embedding. In this paper, we propose Hound to improve accuracy by introducing more supervision signals, and the core idea is to go beyond the node-text pairs that come with data. Specifically, we design three augmentation techniques, i.e., node perturbation, text matching, and semantics negation to provide more reference nodes for each text and vice versa. Node perturbation adds/drops edges to produce diversified node embeddings that can be matched with a text. Text matching retrieves texts with similar embeddings to match with a node. Semantics negation uses a negative prompt to construct a negative text with the opposite semantics, which is contrasted with the original node and text. We evaluate Hound on 5 datasets and compare with 13 state-of-the-art baselines. The results show that Hound consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
TreeCSS: An Efficient Framework for Vertical Federated Learning
Aug 03, 2024Vertical federated learning (VFL) considers the case that the features of data samples are partitioned over different participants. VFL consists of two main steps, i.e., identify the common data samples for all participants (alignment) and train model using the aligned data samples (training). However, when there are many participants and data samples, both alignment and training become slow. As such, we propose TreeCSS as an efficient VFL framework that accelerates the two main steps. In particular, for sample alignment, we design an efficient multi-party private set intersection (MPSI) protocol called Tree-MPSI, which adopts a tree-based structure and a data-volume-aware scheduling strategy to parallelize alignment among the participants. As model training time scales with the number of data samples, we conduct coreset selection (CSS) to choose some representative data samples for training. Our CCS method adopts a clustering-based scheme for security and generality, which first clusters the features locally on each participant and then merges the local clustering results to select representative samples. In addition, we weight the samples according to their distances to the centroids to reflect their importance to model training. We evaluate the effectiveness and efficiency of our TreeCSS framework on various datasets and models. The results show that compared with vanilla VFL, TreeCSS accelerates training by up to 2.93x and achieves comparable model accuracy.
Generative and Contrastive Paradigms Are Complementary for Graph Self-Supervised Learning
Oct 24, 2023



For graph self-supervised learning (GSSL), masked autoencoder (MAE) follows the generative paradigm and learns to reconstruct masked graph edges or node features. Contrastive Learning (CL) maximizes the similarity between augmented views of the same graph and is widely used for GSSL. However, MAE and CL are considered separately in existing works for GSSL. We observe that the MAE and CL paradigms are complementary and propose the graph contrastive masked autoencoder (GCMAE) framework to unify them. Specifically, by focusing on local edges or node features, MAE cannot capture global information of the graph and is sensitive to particular edges and features. On the contrary, CL excels in extracting global information because it considers the relation between graphs. As such, we equip GCMAE with an MAE branch and a CL branch, and the two branches share a common encoder, which allows the MAE branch to exploit the global information extracted by the CL branch. To force GCMAE to capture global graph structures, we train it to reconstruct the entire adjacency matrix instead of only the masked edges as in existing works. Moreover, a discrimination loss is proposed for feature reconstruction, which improves the disparity between node embeddings rather than reducing the reconstruction error to tackle the feature smoothing problem of MAE. We evaluate GCMAE on four popular graph tasks (i.e., node classification, node clustering, link prediction, and graph classification) and compare with 14 state-of-the-art baselines. The results show that GCMAE consistently provides good accuracy across these tasks, and the maximum accuracy improvement is up to 3.2% compared with the best-performing baseline.